Text2Vis: A Challenging and Diverse Benchmark for Generating Multimodal Visualizations from Text
作者: Mizanur Rahman, Md Tahmid Rahman Laskar, Shafiq Joty, Enamul Hoque
分类: cs.CL, cs.CV
发布日期: 2025-07-26
🔗 代码/项目: GITHUB
💡 一句话要点
Text2Vis:提出一个具有挑战性和多样性的基准,用于从文本生成多模态可视化。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文本到可视化 多模态学习 基准数据集 强化学习 大型语言模型 自动评估 数据科学 图表生成
📋 核心要点
- 现有方法缺乏一个全面的基准来严格评估大型语言模型在文本到可视化生成任务中的能力,阻碍了该领域的发展。
- 提出Text2Vis基准,包含多样化的图表类型和数据科学查询,并设计跨模态actor-critic框架,联合优化文本答案和可视化代码。
- 实验表明,该框架将GPT-4o的通过率从26%提升到42%,并引入基于LLM的自动评估框架,实现大规模评估。
📝 摘要(中文)
自动数据可视化在简化数据解释、增强决策制定和提高效率方面起着关键作用。虽然大型语言模型(LLMs)在从自然语言生成可视化方面显示出潜力,但缺乏全面的基准限制了对其能力的严格评估。我们引入Text2Vis,这是一个旨在评估文本到可视化模型的基准,涵盖20多种图表类型和多样的数据科学查询,包括趋势分析、相关性、异常值检测和预测分析。它包含1,985个样本,每个样本都有一个数据表、自然语言查询、简短答案、可视化代码和带注释的图表。这些查询涉及复杂的推理、对话轮次和动态数据检索。我们对11个开源和闭源模型进行了基准测试,揭示了显著的性能差距,突出了关键挑战,并为未来的发展提供了见解。为了缩小这一差距,我们提出了第一个跨模态actor-critic agentic框架,该框架共同改进文本答案和可视化代码,将GPT-4o的通过率从直接方法的26%提高到42%,并提高了图表质量。我们还引入了一个基于LLM的自动评估框架,该框架可以在没有人工注释的情况下对数千个样本进行可扩展的评估,测量答案的正确性、代码执行的成功率、可视化的可读性和图表的准确性。我们在https://github.com/vis-nlp/Text2Vis上发布了Text2Vis。
🔬 方法详解
问题定义:现有文本到可视化生成方法缺乏统一且具有挑战性的评估基准,难以全面评估模型在处理复杂数据科学查询和生成高质量可视化方面的能力。现有方法在处理复杂推理、对话轮次和动态数据检索方面存在不足,且缺乏有效的自动评估机制。
核心思路:论文的核心思路是构建一个包含多样化数据科学查询和图表类型的基准数据集Text2Vis,并提出一个跨模态actor-critic agentic框架,该框架通过联合优化文本答案和可视化代码来提高生成质量。此外,引入基于LLM的自动评估框架,以实现大规模、高效的评估。
技术框架:整体框架包含数据收集与标注、模型训练和自动评估三个主要阶段。数据收集与标注阶段构建了Text2Vis数据集,包含数据表、自然语言查询、答案、可视化代码和图表。模型训练阶段使用跨模态actor-critic agentic框架,该框架包含actor网络(生成文本答案和可视化代码)和critic网络(评估生成结果)。自动评估阶段使用基于LLM的评估框架,评估答案正确性、代码执行成功率、可视化可读性和图表准确性。
关键创新:主要创新点在于:1) 构建了Text2Vis基准数据集,包含多样化的数据科学查询和图表类型;2) 提出了跨模态actor-critic agentic框架,通过联合优化文本答案和可视化代码来提高生成质量;3) 引入了基于LLM的自动评估框架,实现大规模、高效的评估。与现有方法相比,该方法能够更好地处理复杂的数据科学查询,并生成更高质量的可视化结果。
关键设计:跨模态actor-critic agentic框架的关键设计包括:actor网络采用Transformer架构,用于生成文本答案和可视化代码;critic网络采用预训练语言模型,用于评估生成结果的质量;奖励函数结合了答案正确性、代码执行成功率、可视化可读性和图表准确性等指标。自动评估框架的关键设计包括:使用预训练语言模型作为评估器,并设计了针对不同评估指标的prompt模板。
🖼️ 关键图片
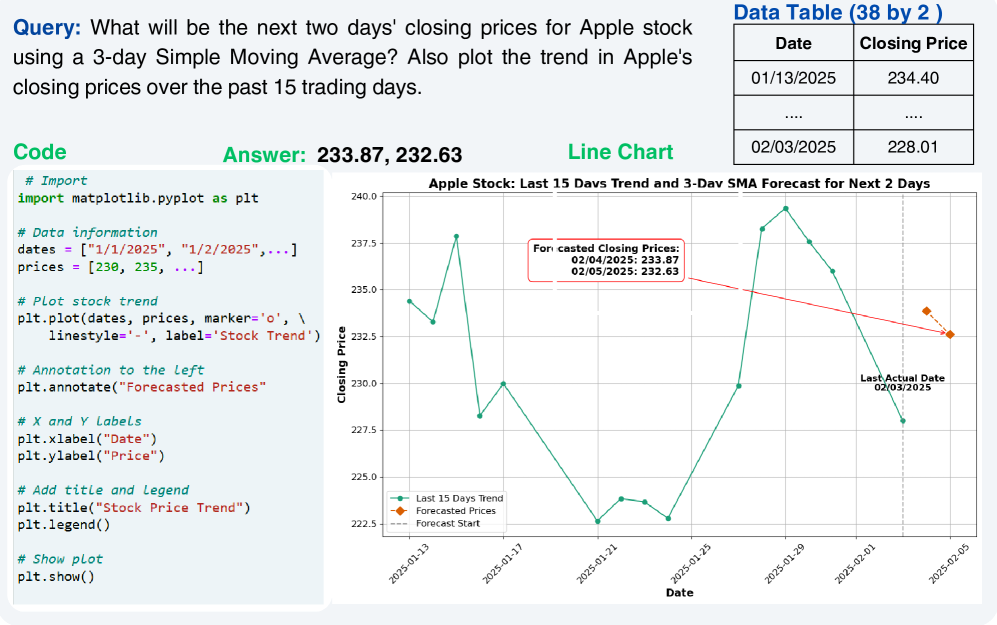
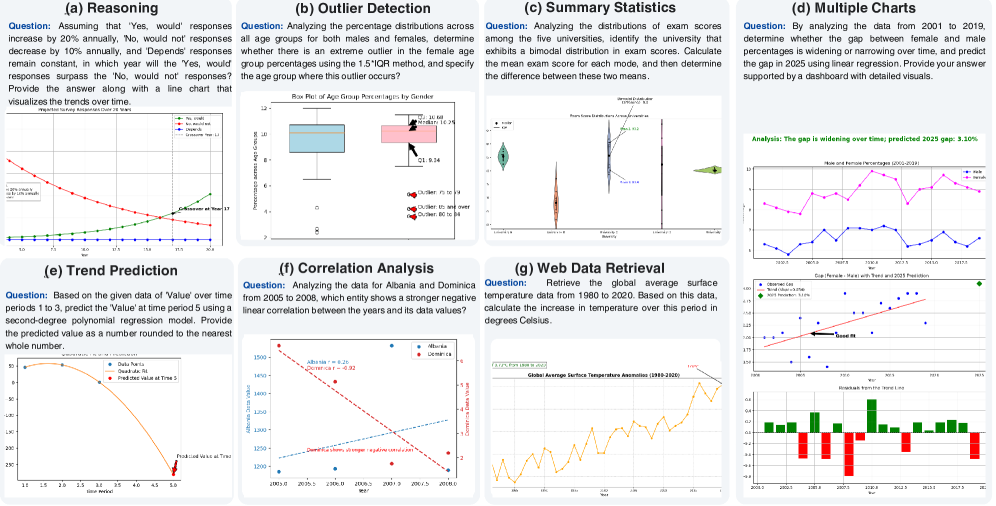

📊 实验亮点
实验结果表明,提出的跨模态actor-critic agentic框架显著提高了GPT-4o在Text2Vis基准上的性能,通过率从26%提升到42%。此外,基于LLM的自动评估框架能够在大规模数据集上进行高效评估,无需人工标注,为模型评估提供了新的解决方案。
🎯 应用场景
该研究成果可应用于自动化数据分析、商业智能、教育等领域。通过Text2Vis基准,可以促进文本到可视化生成模型的发展,提高数据可视化的效率和质量。该研究还有助于开发更智能的数据分析工具,帮助用户更好地理解和利用数据。
📄 摘要(原文)
Automated data visualization plays a crucial role in simplifying data interpretation, enhancing decision-making, and improving efficiency. While large language models (LLMs) have shown promise in generating visualizations from natural language, the absence of comprehensive benchmarks limits the rigorous evaluation of their capabilities. We introduce Text2Vis, a benchmark designed to assess text-to-visualization models, covering 20+ chart types and diverse data science queries, including trend analysis, correlation, outlier detection, and predictive analytics. It comprises 1,985 samples, each with a data table, natural language query, short answer, visualization code, and annotated charts. The queries involve complex reasoning, conversational turns, and dynamic data retrieval. We benchmark 11 open-source and closed-source models, revealing significant performance gaps, highlighting key challenges, and offering insights for future advancements. To close this gap, we propose the first cross-modal actor-critic agentic framework that jointly refines the textual answer and visualization code, increasing GPT-4o`s pass rate from 26% to 42% over the direct approach and improving chart quality. We also introduce an automated LLM-based evaluation framework that enables scalable assessment across thousands of samples without human annotation, measuring answer correctness, code execution success, visualization readability, and chart accuracy. We release Text2Vis at https://github.com/vis-nlp/Text2Vis.