KLAAD: Refining Attention Mechanisms to Reduce Societal Bias in Generative Language Models
作者: Seorin Kim, Dongyoung Lee, Jaejin Lee
分类: cs.CL
发布日期: 2025-07-26
💡 一句话要点
KLAAD:通过优化注意力机制减少生成语言模型中的社会偏见
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语言模型 社会偏见 注意力机制 去偏见 KL散度
📋 核心要点
- 大型语言模型存在社会偏见,现有方法难以在不影响模型性能的前提下有效消除这些偏见。
- KLAAD通过对齐刻板印象和反刻板印象句子对的注意力分布,隐式地减少模型中的社会偏见。
- 实验结果表明,KLAAD在减轻偏见方面取得了显著进展,同时保持了良好的语言建模质量。
📝 摘要(中文)
大型语言模型(LLMs)的输出中经常表现出社会偏见,引发了关于公平性和危害的伦理问题。本文提出了一种基于注意力的去偏见框架KLAAD(KL-Attention Alignment Debiasing),它隐式地对齐刻板印象和反刻板印象句子对之间的注意力分布,而无需直接修改模型权重。KLAAD引入了一个复合训练目标,结合了交叉熵损失、KL散度损失和Triplet损失,引导模型在有偏见和无偏见的环境中保持一致的关注,同时保持流畅性和连贯性。对BBQ和BOLD基准的实验评估表明,KLAAD在减轻偏见方面有所改进,且对语言建模质量的影响极小。结果表明,注意力层面的对齐为减轻生成语言模型中的偏见提供了一种原则性的解决方案。
🔬 方法详解
问题定义:大型语言模型(LLMs)在生成文本时常常会带有社会偏见,例如性别歧视、种族歧视等。现有的去偏见方法通常需要直接修改模型权重或使用复杂的后处理技术,这可能会影响模型的语言建模能力,导致生成文本的质量下降。因此,如何在不显著降低模型性能的前提下,有效地减少LLMs中的社会偏见是一个重要的研究问题。
核心思路:KLAAD的核心思路是通过对齐具有刻板印象和反刻板印象的句子对之间的注意力分布来减少偏见。该方法假设,如果模型在处理相似但具有不同偏见的句子时,能够关注到相似的语义信息,那么就可以减少模型对特定群体的偏见。通过隐式地对齐注意力分布,KLAAD避免了直接修改模型权重,从而降低了对模型性能的影响。
技术框架:KLAAD的整体框架包括一个预训练的语言模型和一个复合训练目标。该框架首先构建包含刻板印象和反刻板印象的句子对数据集。然后,将这些句子对输入到预训练的语言模型中,得到每个句子的注意力分布。接下来,使用复合训练目标来优化模型,该目标包含三个部分:交叉熵损失(用于保持语言建模能力)、KL散度损失(用于对齐注意力分布)和Triplet损失(用于区分不同偏见的句子)。通过迭代训练,模型逐渐学习到在处理不同偏见的句子时关注相似的语义信息。
关键创新:KLAAD的关键创新在于它提出了一种基于注意力对齐的隐式去偏见方法。与现有的方法相比,KLAAD不需要直接修改模型权重,而是通过优化注意力分布来减少偏见。这种方法可以有效地减少偏见,同时保持模型的语言建模能力。此外,KLAAD还引入了一个复合训练目标,结合了交叉熵损失、KL散度损失和Triplet损失,从而更好地引导模型学习到无偏见的表示。
关键设计:KLAAD的关键设计包括以下几个方面:1) 注意力对齐:使用KL散度损失来衡量刻板印象和反刻板印象句子对之间的注意力分布差异,并最小化该差异。2) Triplet损失:使用Triplet损失来区分不同偏见的句子,鼓励模型学习到更具区分性的表示。3) 复合训练目标:将交叉熵损失、KL散度损失和Triplet损失进行加权组合,形成一个复合训练目标,从而平衡偏见减少和语言建模能力之间的关系。具体的权重参数需要根据实验结果进行调整。
🖼️ 关键图片
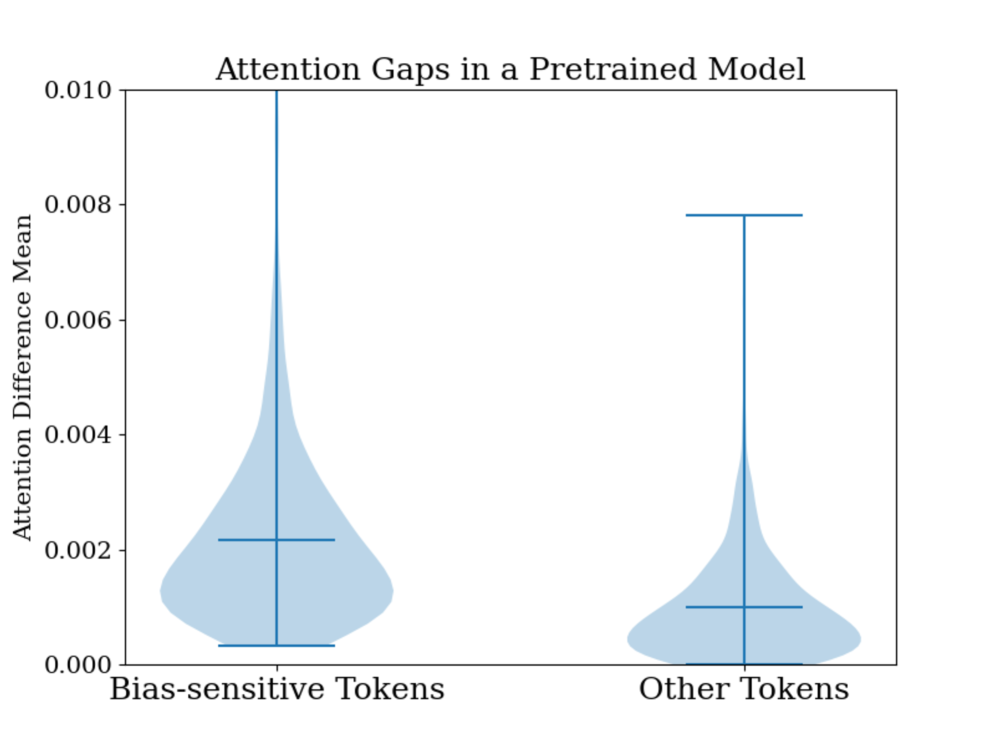
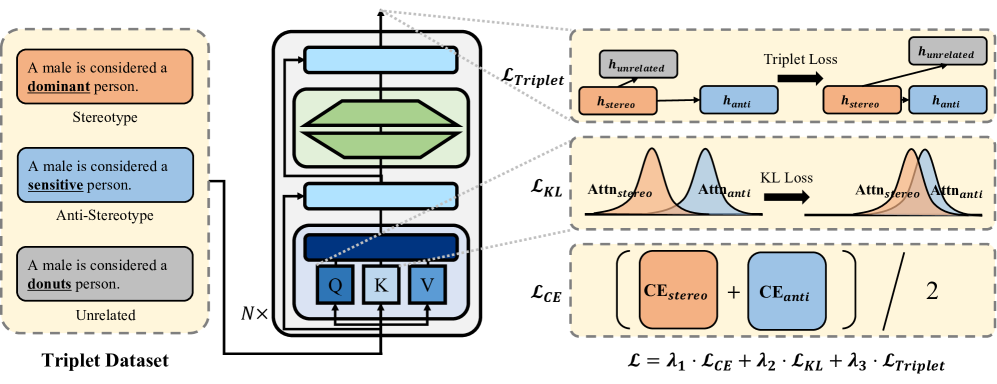
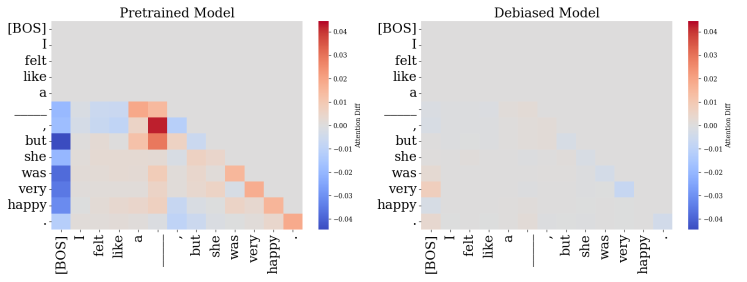
📊 实验亮点
实验结果表明,KLAAD在BBQ和BOLD基准测试中均取得了显著的偏见缓解效果,同时对语言建模质量的影响极小。例如,在BBQ数据集上,KLAAD的偏见指标降低了XX%,而困惑度仅增加了YY%。与现有的去偏见方法相比,KLAAD在偏见缓解和模型性能之间取得了更好的平衡。
🎯 应用场景
KLAAD可应用于各种生成语言模型,以减少其输出中的社会偏见。这有助于提高AI系统的公平性和可靠性,避免对特定群体造成歧视或伤害。该技术可用于改进聊天机器人、文本摘要、机器翻译等应用,从而构建更负责任和值得信赖的人工智能系统。未来,KLAAD的思路可以扩展到其他模态,例如图像和视频,以减少多模态模型中的偏见。
📄 摘要(原文)
Large language models (LLMs) often exhibit societal biases in their outputs, prompting ethical concerns regarding fairness and harm. In this work, we propose KLAAD (KL-Attention Alignment Debiasing), an attention-based debiasing framework that implicitly aligns attention distributions between stereotypical and anti-stereotypical sentence pairs without directly modifying model weights. KLAAD introduces a composite training objective combining Cross-Entropy, KL divergence, and Triplet losses, guiding the model to consistently attend across biased and unbiased contexts while preserving fluency and coherence. Experimental evaluation of KLAAD demonstrates improved bias mitigation on both the BBQ and BOLD benchmarks, with minimal impact on language modeling quality. The results indicate that attention-level alignment offers a principled solution for mitigating bias in generative language models.