CaliDrop: KV Cache Compression with Calibration
作者: Yi Su, Quantong Qiu, Yuechi Zhou, Juntao Li, Qingrong Xia, Ping Li, Xinyu Duan, Zhefeng Wang, Min Zhang
分类: cs.CL
发布日期: 2025-07-26 (更新: 2025-08-04)
💡 一句话要点
CaliDrop:通过校准增强KV缓存压缩中的Token Eviction策略,提升长文本场景下的LLM性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: KV缓存压缩 Token Eviction 长文本处理 大型语言模型 注意力机制
📋 核心要点
- 长文本场景下,LLM的KV缓存占用大量内存,Token Eviction虽能压缩缓存,但高压缩率下精度损失严重。
- CaliDrop的核心思想是利用相邻位置queries的高相似性,对丢弃的token进行推测性校准,弥补精度损失。
- 实验结果表明,CaliDrop能显著提升现有Token Eviction方法的准确性,有效缓解高压缩率下的性能下降。
📝 摘要(中文)
大型语言模型(LLM)在生成过程中需要大量的计算资源。Key-Value(KV)缓存通过存储注意力机制的中间结果来显著加速这一过程,但其内存占用随序列长度、批次大小和模型大小线性增长,这在长文本场景中造成了瓶颈。为了缓解这一瓶颈,研究者们提出了各种KV缓存压缩技术,包括token eviction、量化和低秩投影等,这些技术通常可以相互补充。本文重点关注增强token eviction策略。Token eviction利用注意力模式通常是稀疏的这一观察结果,允许移除不太重要的KV条目以节省内存。然而,这种减少通常以显著的精度下降为代价,尤其是在高压缩率下。为了解决这个问题,我们提出了一种新的策略 extbf{CaliDrop},它通过校准来增强token eviction。我们的初步实验表明,附近位置的queries表现出高度的相似性。基于这一观察,CaliDrop对丢弃的token执行推测性校准,以减轻token eviction造成的精度损失。大量的实验表明,CaliDrop显著提高了现有token eviction方法的准确性。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在长文本生成时,KV缓存占用内存过大的问题。现有的Token Eviction方法虽然能压缩KV缓存,但在高压缩率下会造成显著的精度损失,限制了其应用。
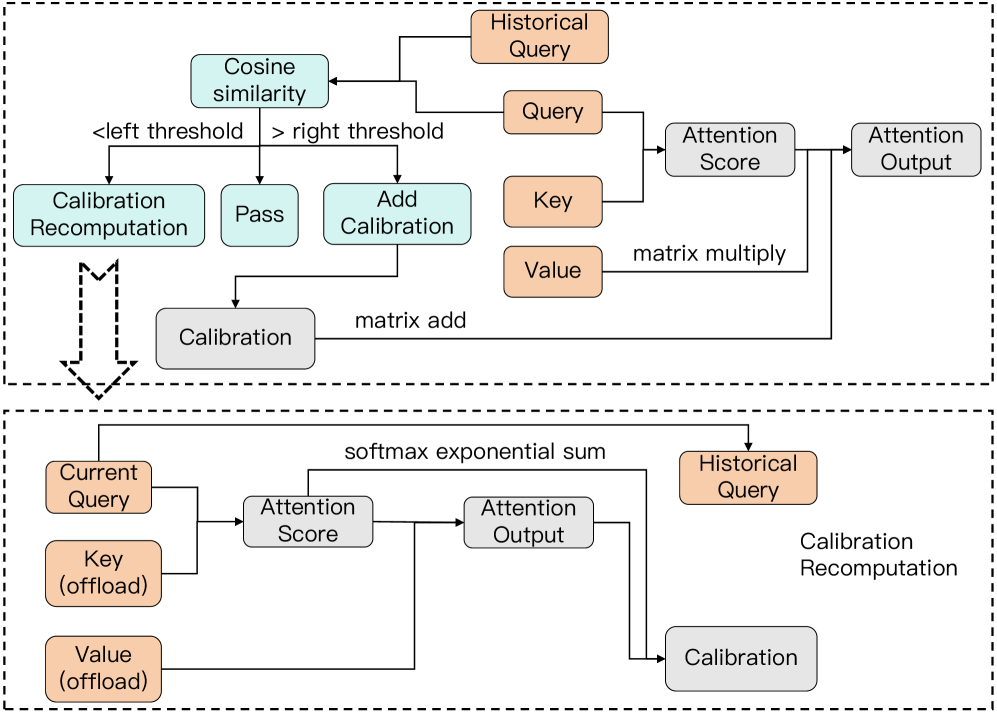
核心思路:CaliDrop的核心思路是,即使某些token被evict(丢弃)了,仍然可以利用与其相邻位置的token的信息来推测(校准)这些被丢弃token的影响。这是基于一个观察:相邻位置的query通常具有较高的相似性,因此可以利用这些相似性来弥补信息损失。
技术框架:CaliDrop可以被看作是现有Token Eviction方法的一个增强模块。整体流程是:1. 使用现有的Token Eviction方法选择要丢弃的token;2. 对于每个被丢弃的token,CaliDrop利用其相邻位置的token信息进行校准,以估计被丢弃token对后续计算的影响;3. 将校准后的结果用于后续的注意力计算。
关键创新:CaliDrop的关键创新在于提出了“校准”的概念,即通过推测被丢弃token的影响来弥补信息损失。与直接丢弃token相比,CaliDrop试图保留被丢弃token的部分信息,从而减少精度损失。这种推测性的校准是CaliDrop与现有Token Eviction方法的本质区别。
关键设计:具体的校准方法(如何利用相邻位置的token信息来推测被丢弃token的影响)是CaliDrop的关键设计。论文中可能涉及具体的相似度度量方法、加权平均策略或其他更复杂的推测模型。这些细节决定了CaliDrop的性能。
🖼️ 关键图片
📊 实验亮点
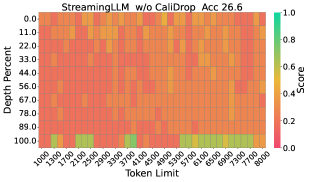
论文通过实验证明,CaliDrop能够显著提高现有Token Eviction方法的准确性。具体的性能提升幅度取决于所使用的Token Eviction方法和压缩率。实验结果表明,即使在高压缩率下,CaliDrop也能有效缓解精度下降的问题,使得Token Eviction方法更具实用性。具体的性能数据需要在论文中查找。
🎯 应用场景
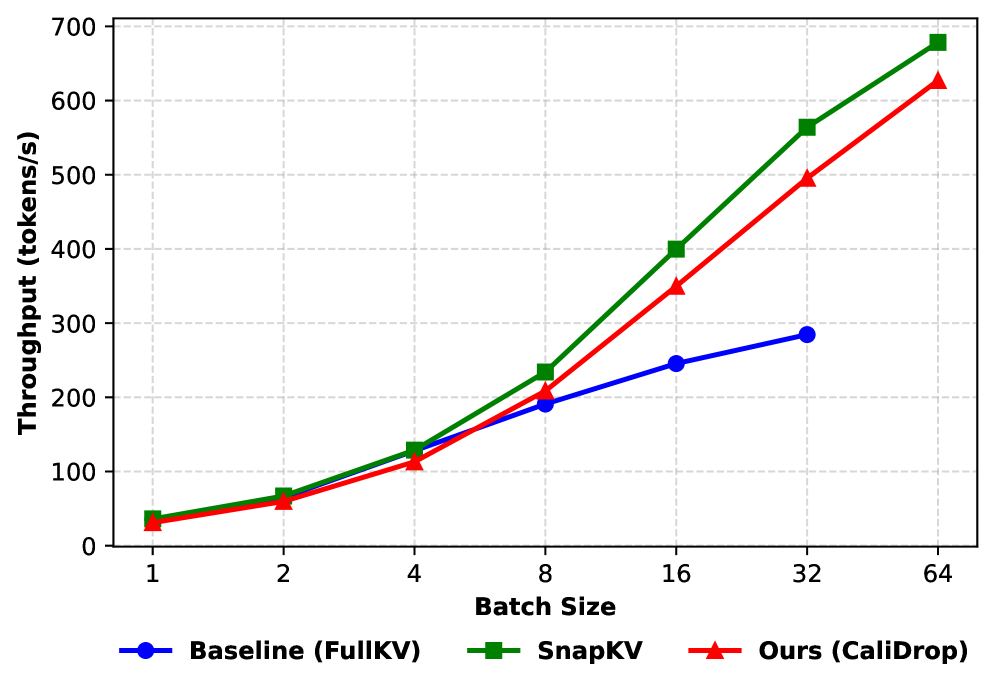
CaliDrop可应用于各种需要处理长文本的LLM应用场景,例如长篇文档生成、对话系统、代码生成等。通过降低KV缓存的内存占用,CaliDrop使得LLM能够在资源受限的设备上运行更长的序列,或者在相同的硬件条件下处理更大的批次,从而提高效率和降低成本。未来,CaliDrop可以与其他KV缓存压缩技术结合,进一步提升LLM的性能。
📄 摘要(原文)
Large Language Models (LLMs) require substantial computational resources during generation. While the Key-Value (KV) cache significantly accelerates this process by storing attention intermediates, its memory footprint grows linearly with sequence length, batch size, and model size, creating a bottleneck in long-context scenarios. Various KV cache compression techniques, including token eviction, quantization, and low-rank projection, have been proposed to mitigate this bottleneck, often complementing each other. This paper focuses on enhancing token eviction strategies. Token eviction leverages the observation that the attention patterns are often sparse, allowing for the removal of less critical KV entries to save memory. However, this reduction usually comes at the cost of notable accuracy degradation, particularly under high compression ratios. To address this issue, we propose \textbf{CaliDrop}, a novel strategy that enhances token eviction through calibration. Our preliminary experiments show that queries at nearby positions exhibit high similarity. Building on this observation, CaliDrop performs speculative calibration on the discarded tokens to mitigate the accuracy loss caused by token eviction. Extensive experiments demonstrate that CaliDrop significantly improves the accuracy of existing token eviction methods.