HCAttention: Extreme KV Cache Compression via Heterogeneous Attention Computing for LLMs
作者: Dongquan Yang, Yifan Yang, Xiaotian Yu, Xianbiao Qi, Rong Xiao
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-07-26
💡 一句话要点
提出HCAttention以解决大语言模型KV缓存压缩问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 KV缓存压缩 异构计算 内存管理 自然语言处理 模型优化 推理效率
📋 核心要点
- 现有KV缓存压缩方法在内存减少超过85%时性能显著下降,导致处理长上下文输入的挑战。
- HCAttention通过关键量化、值卸载和动态KV驱逐,提出了一种异构注意力计算框架,旨在高效推理。
- 实验结果显示,该方法在将KV缓存内存占用缩减至25%时,仍能保持全注意力模型的准确性,并在仅使用12.5%缓存时表现出色。
📝 摘要(中文)
处理长上下文输入的大语言模型在推理时面临着巨大的内存需求,尤其是Key-Value (KV)缓存的内存消耗。现有的KV缓存压缩方法在内存减少超过85%时性能显著下降。此外,利用GPU-CPU协作进行近似注意力的策略在这一领域尚未得到充分探索。为此,我们提出了HCAttention,一个异构注意力计算框架,集成了关键量化、值卸载和动态KV驱逐,以在极端内存限制下实现高效推理。该方法兼容现有的变换器架构,无需模型微调。实验结果表明,我们的方法在将KV缓存内存占用缩减至原始大小的25%时,仍能保持全注意力模型的准确性,且在仅使用12.5%缓存时仍具竞争力,创造了LLM KV缓存压缩的新状态。HCAttention是首个将Llama-3-8B模型扩展至在单个80GB A100 GPU上处理400万标记的研究。
🔬 方法详解
问题定义:论文要解决的问题是如何在推理过程中有效压缩大语言模型的KV缓存,以应对长上下文输入的内存需求。现有方法在内存压缩超过85%时性能显著下降,限制了模型的应用场景。
核心思路:HCAttention的核心思路是通过异构注意力计算,结合关键量化、值卸载和动态KV驱逐,来实现高效的内存使用。这种设计旨在在不牺牲模型准确性的前提下,显著减少内存占用。
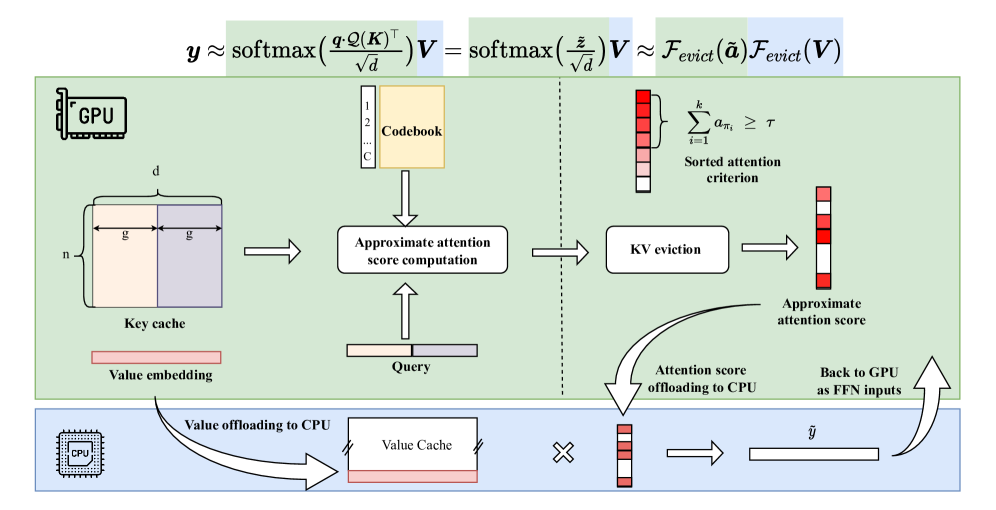
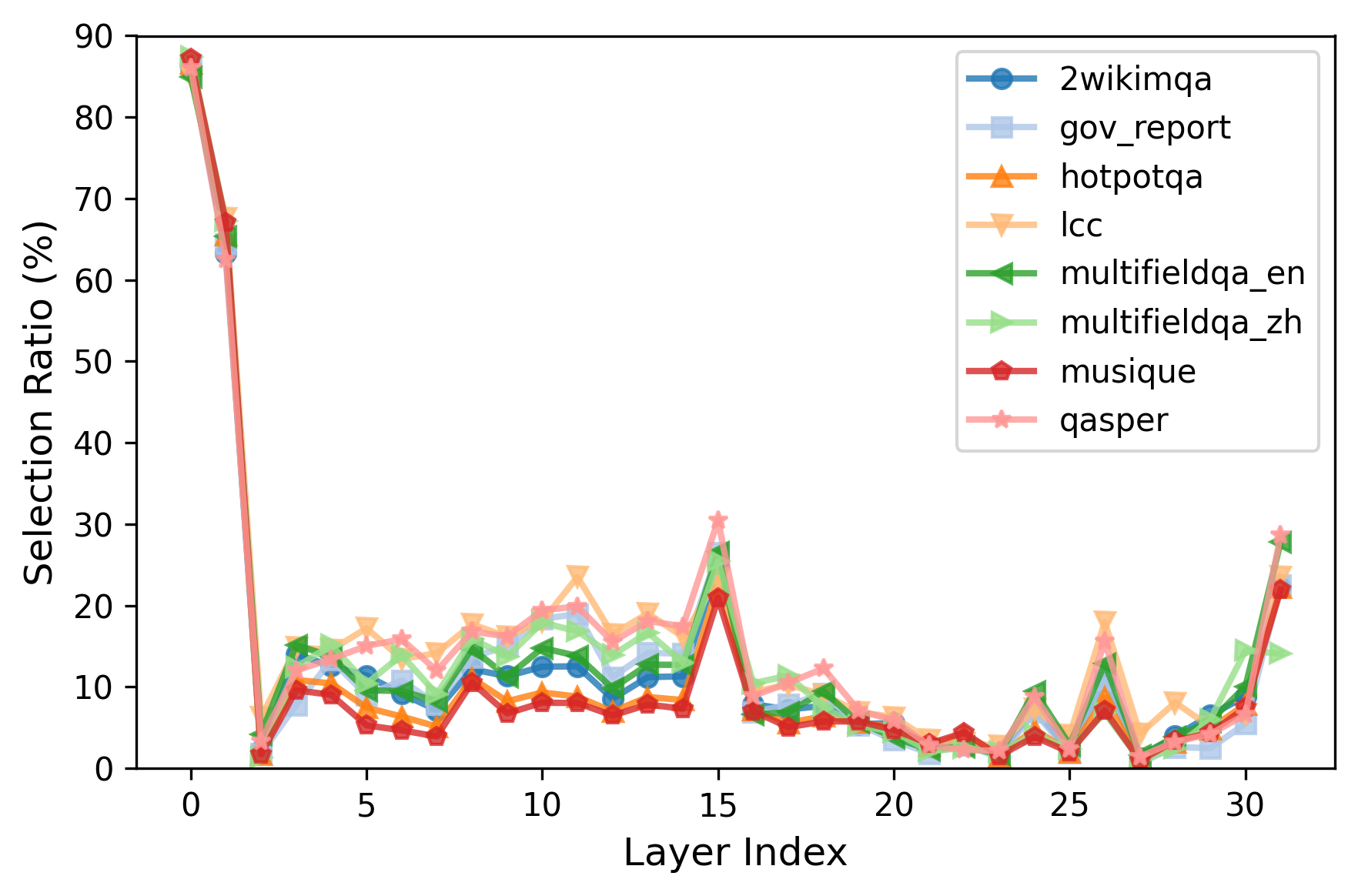
技术框架:HCAttention的整体架构包括三个主要模块:关键量化模块负责将关键向量进行量化以减少存储需求;值卸载模块将部分值向量卸载到外部存储;动态KV驱逐模块根据使用频率动态管理KV缓存。
关键创新:HCAttention的主要创新在于其异构计算框架,首次将GPU-CPU协作引入KV缓存压缩中,显著提高了内存利用效率,并保持了模型的推理性能。
关键设计:在关键量化过程中,采用了适应性量化策略以平衡精度与内存占用;值卸载设计考虑了访问频率,以优化存储和计算效率;动态KV驱逐策略则基于实时使用情况,确保高效的内存管理。
🖼️ 关键图片
📊 实验亮点
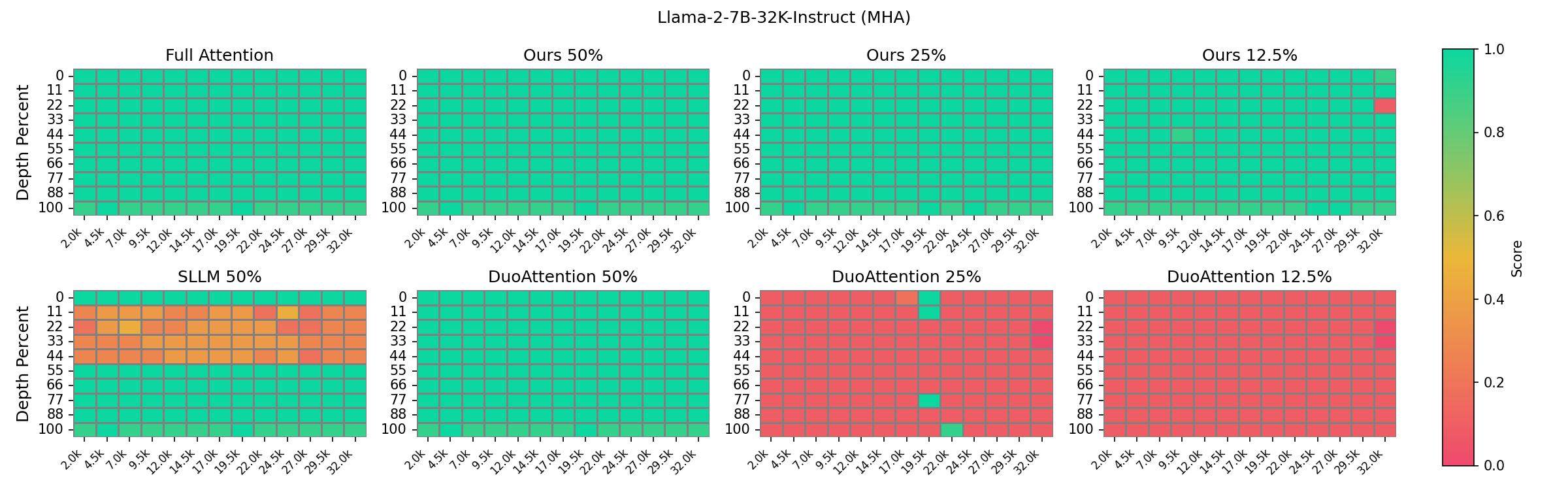
实验结果表明,HCAttention在将KV缓存内存占用缩减至原始大小的25%时,仍能保持全注意力模型的准确性,并在仅使用12.5%缓存时表现出色,创造了LLM KV缓存压缩的新状态,显示出其在极端内存条件下的强大性能。
🎯 应用场景
HCAttention的研究成果在多个领域具有潜在应用价值,尤其是在需要处理长文本或大规模数据的自然语言处理任务中。其高效的内存管理能力使得大语言模型能够在资源受限的环境中运行,推动了智能助手、自动翻译和文本生成等应用的发展。未来,HCAttention可能会影响更广泛的AI模型设计和优化策略。
📄 摘要(原文)
Processing long-context inputs with large language models presents a significant challenge due to the enormous memory requirements of the Key-Value (KV) cache during inference. Existing KV cache compression methods exhibit noticeable performance degradation when memory is reduced by more than 85%. Additionally, strategies that leverage GPU-CPU collaboration for approximate attention remain underexplored in this setting. We propose HCAttention, a heterogeneous attention computation framework that integrates key quantization, value offloading, and dynamic KV eviction to enable efficient inference under extreme memory constraints. The method is compatible with existing transformer architectures and does not require model fine-tuning. Experimental results on the LongBench benchmark demonstrate that our approach preserves the accuracy of full-attention model while shrinking the KV cache memory footprint to 25% of its original size. Remarkably, it stays competitive with only 12.5% of the cache, setting a new state-of-the-art in LLM KV cache compression. To the best of our knowledge, HCAttention is the first to extend the Llama-3-8B model to process 4 million tokens on a single A100 GPU with 80GB memory.