Flora: Effortless Context Construction to Arbitrary Length and Scale
作者: Tianxiang Chen, Zhentao Tan, Xiaofan Bo, Yue Wu, Tao Gong, Qi Chu, Jieping Ye, Nenghai Yu
分类: cs.CL
发布日期: 2025-07-26 (更新: 2025-10-09)
🔗 代码/项目: GITHUB
💡 一句话要点
Flora:一种无需人工干预的任意长度和规模长文本上下文构建方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长文本上下文 大型语言模型 指令调优 自动化数据构建 元指令学习
📋 核心要点
- 现有长文本上下文构建方法依赖人工或LLM干预,成本高昂且限制了长度和多样性,同时牺牲了短文本处理能力。
- Flora通过自动组装短指令并利用长上下文元指令引导LLM生成响应,实现了无需人工干预的任意长度和规模长文本上下文构建。
- 实验表明,Flora显著提升了LLM在长文本基准测试中的性能,同时保持了较好的短文本处理能力,在Llama3-8B-Instruct和QwQ-32B上验证了有效性。
📝 摘要(中文)
由于长文本的稀缺性、高计算需求以及对短文本能力的显著遗忘,有效处理长上下文对于大型语言模型(LLMs)来说极具挑战。最近的方法试图构建用于指令调优的长上下文,但这些方法通常需要LLMs或人工干预,这既昂贵又在长度和多样性上受到限制。此外,当前长上下文LLMs的短上下文性能下降仍然显著。本文介绍了一种无需人工/LLM干预的长上下文构建策略Flora。Flora可以通过基于类别任意组装短指令,并指示LLMs基于长上下文元指令生成响应,从而显著增强LLMs的长上下文性能。这使得Flora能够生成具有丰富多样性的任意长度和规模的上下文,同时仅略微影响短上下文性能。在Llama3-8B-Instruct和QwQ-32B上的实验表明,Flora增强的LLMs在三个长上下文基准测试中表现出色,同时保持了强大的短上下文任务性能。
🔬 方法详解
问题定义:现有的大型语言模型在处理长文本上下文时面临挑战。主要痛点在于:一是长文本数据稀缺,导致模型训练不足;二是处理长文本需要大量的计算资源;三是在优化长文本能力的同时,模型往往会遗忘或降低在短文本任务上的性能。现有的长文本上下文构建方法通常需要人工或LLM的参与,这限制了数据规模和多样性,并且成本较高。
核心思路:Flora的核心思路是自动化地构建长文本上下文,避免人工或LLM的干预。它通过将短指令按照类别进行组合,并使用长上下文元指令来引导LLM生成响应。这种方法的核心在于利用短指令的可组合性来生成任意长度和规模的长文本,同时通过元指令来保持上下文的连贯性和一致性。
技术框架:Flora的整体框架包括以下几个主要阶段:1) 短指令收集与分类:收集大量的短指令,并按照不同的类别进行分类。2) 长上下文构建:根据设定的长度和规模,从不同类别的短指令中随机选择并组合,形成长文本上下文。3) 元指令生成:为每个长文本上下文生成相应的元指令,用于指导LLM理解和处理上下文。4) LLM训练:使用构建的长文本上下文和元指令对LLM进行训练,提高其长文本处理能力。
关键创新:Flora最重要的技术创新点在于其完全自动化的长文本上下文构建流程。与现有方法相比,Flora无需人工标注或LLM生成,从而可以大规模、低成本地生成多样化的长文本数据。此外,Flora通过元指令的设计,有效地引导LLM理解和利用长文本上下文,从而提高了模型的性能。
关键设计:Flora的关键设计包括:1) 短指令分类策略:采用有效的分类方法,确保短指令的多样性和相关性。2) 长上下文组合策略:设计合理的组合策略,避免上下文的冗余和冲突。3) 元指令生成方法:设计清晰、简洁的元指令,引导LLM理解上下文并生成高质量的响应。具体的参数设置、损失函数和网络结构等细节取决于所使用的LLM和具体的任务。
🖼️ 关键图片
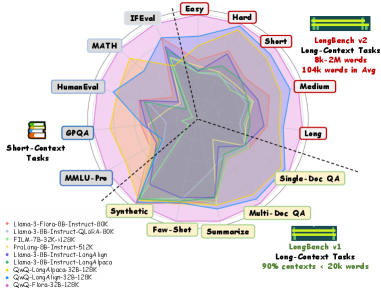

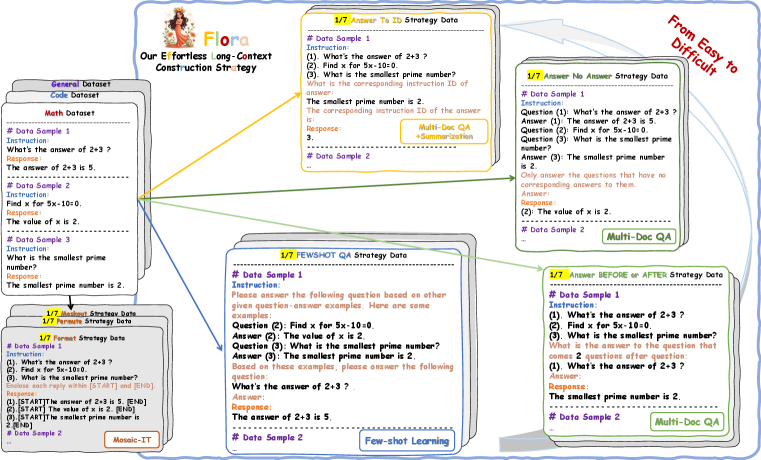
📊 实验亮点
实验结果表明,Flora能够显著提升LLM在长文本基准测试中的性能,同时保持较好的短文本处理能力。例如,在Llama3-8B-Instruct和QwQ-32B上,Flora增强的LLMs在三个长上下文基准测试中表现出色。具体性能数据需要在论文中查找,但总体而言,Flora在提升长文本性能的同时,对短文本性能的影响很小,证明了其有效性。
🎯 应用场景
Flora具有广泛的应用前景,例如可以用于提升LLM在长篇文档摘要、长对话生成、复杂问题解答等领域的性能。通过构建大规模、多样化的长文本训练数据,Flora可以帮助LLM更好地理解和处理真实世界的复杂场景,从而提高其在各种实际应用中的表现。此外,Flora的自动化构建流程也降低了长文本数据获取的成本,促进了LLM在更多领域的应用。
📄 摘要(原文)
Effectively handling long contexts is challenging for Large Language Models (LLMs) due to the rarity of long texts, high computational demands, and substantial forgetting of short-context abilities. Recent approaches have attempted to construct long contexts for instruction tuning, but these methods often require LLMs or human interventions, which are both costly and limited in length and diversity. Also, the drop in short-context performances of present long-context LLMs remains significant. In this paper, we introduce Flora, an effortless (human/LLM-free) long-context construction strategy. Flora can markedly enhance the long-context performance of LLMs by arbitrarily assembling short instructions based on categories and instructing LLMs to generate responses based on long-context meta-instructions. This enables Flora to produce contexts of arbitrary length and scale with rich diversity, while only slightly compromising short-context performance. Experiments on Llama3-8B-Instruct and QwQ-32B show that LLMs enhanced by Flora excel in three long-context benchmarks while maintaining strong performances in short-context tasks. Our data-construction code is available at \href{https://github.com/txchen-USTC/Flora}{https://github.com/txchen-USTC/Flora}.