UloRL:An Ultra-Long Output Reinforcement Learning Approach for Advancing Large Language Models' Reasoning Abilities
作者: Dong Du, Shulin Liu, Tao Yang, Shaohua Chen, Yang Li
分类: cs.CL, cs.AI
发布日期: 2025-07-26
备注: 12 pages
💡 一句话要点
UloRL:一种超长输出强化学习方法,提升大型语言模型的推理能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 超长序列 强化学习 大型语言模型 推理能力 分段Rollout
📋 核心要点
- 传统强化学习框架在处理LLM超长输出时,面临长尾序列分布和训练过程中的熵崩溃等问题,导致训练效率低下。
- UloRL方法将超长输出解码分割成短片段,缓解长尾样本延迟,并动态掩码已掌握的积极tokens,防止熵崩溃。
- 实验表明,UloRL显著提升了LLM在AIME2025和BeyondAIME等推理任务上的性能,并加速了训练过程。
📝 摘要(中文)
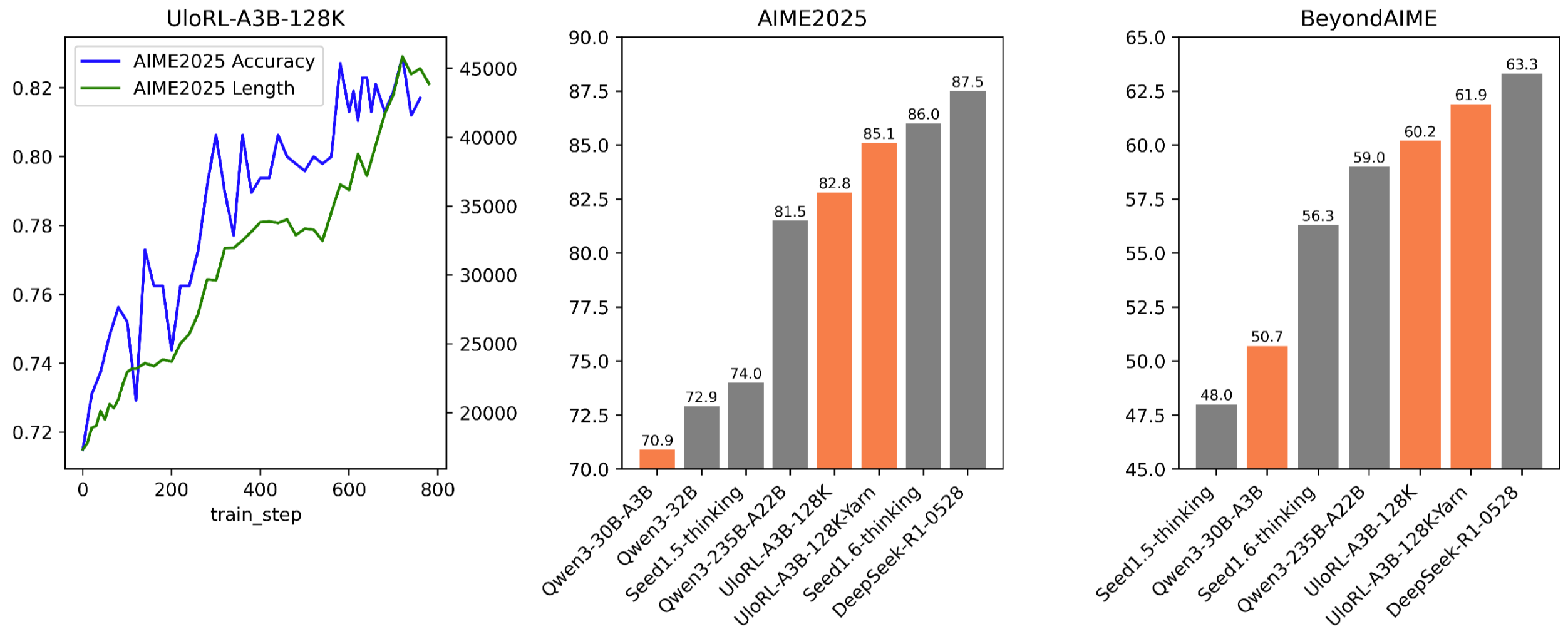
本文提出了一种超长输出强化学习(UloRL)方法,旨在提升大型语言模型(LLMs)的推理能力。该方法利用可验证奖励的强化学习(RLVR)来增强LLMs通过扩展输出序列进行推理的能力。针对传统RL框架在处理超长输出时面临的长尾序列分布和训练期间的熵崩溃问题,UloRL将超长输出解码分割成短片段,通过缓解长尾样本造成的延迟来实现高效训练。此外,引入了对已掌握的积极tokens(MPTs)的动态掩码,以防止熵崩溃。实验结果表明,该方法有效提升了模型性能。在Qwen3-30B-A3B模型上,分段rollout的RL训练速度提高了2.06倍,而使用128k tokens输出的RL训练将模型在AIME2025上的性能从70.9%提高到85.1%,在BeyondAIME上的性能从50.7%提高到61.9%,甚至超过了Qwen3-235B-A22B。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在生成超长序列时,由于长尾分布和训练过程中的熵崩溃导致的强化学习训练效率低下的问题。现有方法难以有效处理超长序列,导致模型难以充分利用长序列中的信息进行推理。
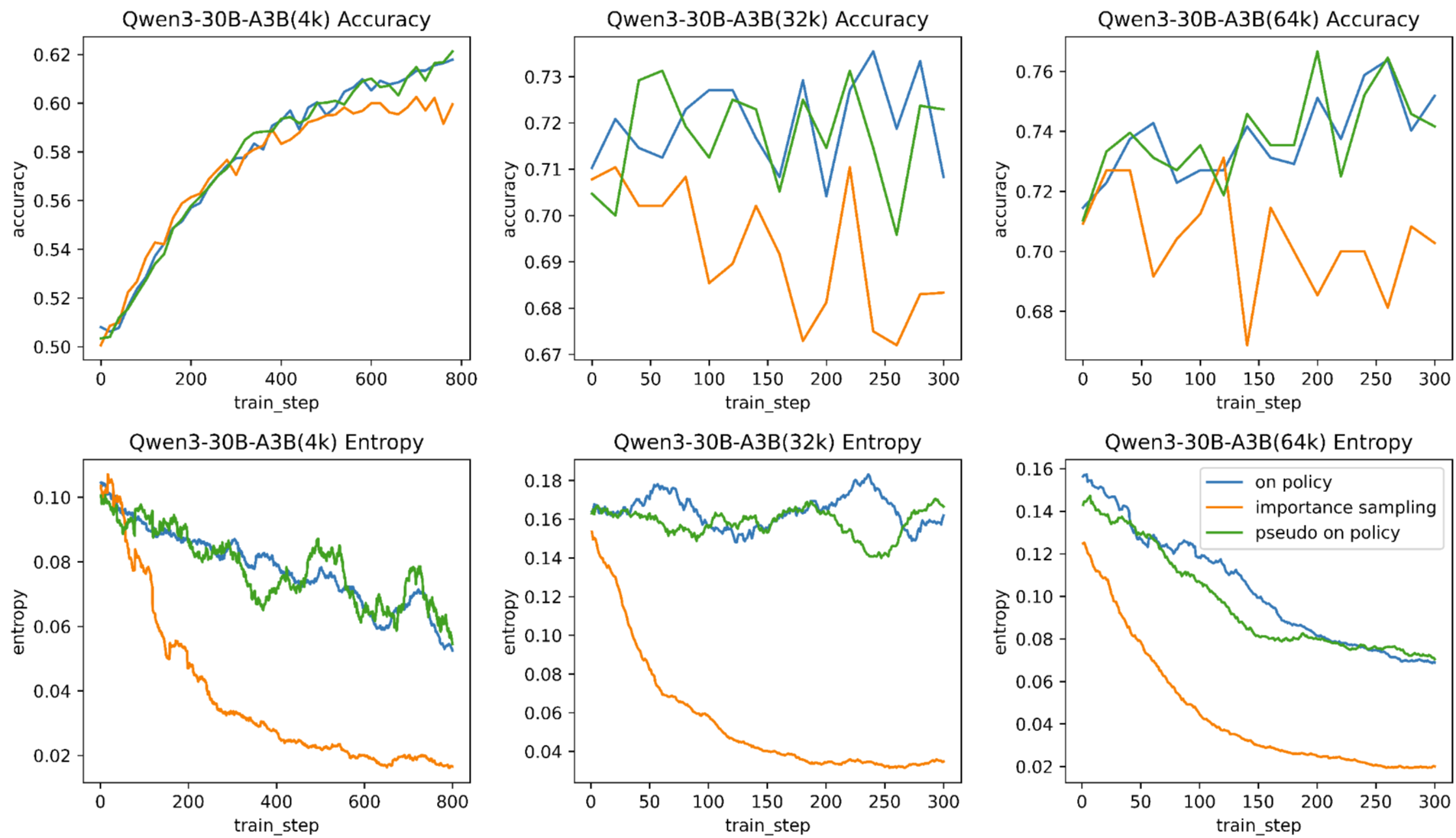
核心思路:论文的核心思路是将超长序列分割成多个短序列片段,并在强化学习过程中对这些片段进行训练,从而缓解长尾分布带来的训练延迟。同时,通过动态掩码已掌握的积极tokens,防止模型在训练过程中过早收敛,保持探索能力。
技术框架:UloRL方法主要包含两个关键模块:分段Rollout和动态掩码。分段Rollout将超长输出序列分割成多个短片段,每个片段作为一个独立的训练样本。动态掩码则根据模型对tokens的掌握程度,动态地屏蔽一部分tokens,鼓励模型探索新的tokens组合。整体流程是:首先将超长序列分割成短片段,然后使用强化学习算法对这些片段进行训练,并在训练过程中使用动态掩码策略。
关键创新:该方法最重要的创新点在于将超长序列的强化学习问题分解为多个短序列的强化学习问题,从而降低了训练难度,提高了训练效率。同时,动态掩码策略有效地防止了熵崩溃,保证了模型的探索能力。与现有方法相比,UloRL能够更有效地利用超长序列中的信息,提升模型的推理能力。
关键设计:在分段Rollout中,需要确定合适的片段长度。片段长度的选择需要在训练效率和信息完整性之间进行权衡。在动态掩码中,需要设计合适的掩码策略,例如,可以根据模型对tokens的预测概率来确定掩码的概率。损失函数通常采用标准的强化学习损失函数,例如Policy Gradient或Actor-Critic损失函数。
🖼️ 关键图片

📊 实验亮点
实验结果表明,UloRL方法在Qwen3-30B-A3B模型上,通过分段rollout将训练速度提高了2.06倍。同时,使用128k tokens输出的RL训练将模型在AIME2025上的性能从70.9%提高到85.1%,在BeyondAIME上的性能从50.7%提高到61.9%,甚至超过了Qwen3-235B-A22B。这些结果表明,UloRL能够显著提升LLM在推理任务上的性能。
🎯 应用场景
UloRL方法具有广泛的应用前景,可以应用于需要生成超长序列的各种任务中,例如长篇小说创作、代码生成、复杂问题求解等。该方法能够提升LLM在这些任务中的性能,使其能够更好地理解和利用长序列中的信息,从而生成更具创造性和逻辑性的内容。此外,UloRL还可以应用于对话系统,使其能够进行更长时间的连贯对话。
📄 摘要(原文)
Recent advances in large language models (LLMs) have highlighted the potential of reinforcement learning with verifiable rewards (RLVR) to enhance reasoning capabilities through extended output sequences. However, traditional RL frameworks face inefficiencies when handling ultra-long outputs due to long-tail sequence distributions and entropy collapse during training. To address these challenges, we propose an Ultra-Long Output Reinforcement Learning (UloRL) approach for advancing large language models' reasoning abilities. Specifically, we divide ultra long output decoding into short segments, enabling efficient training by mitigating delays caused by long-tail samples. Additionally, we introduce dynamic masking of well-Mastered Positive Tokens (MPTs) to prevent entropy collapse. Experimental results demonstrate the effectiveness of our approach. On the Qwen3-30B-A3B model, RL with segment rollout achieved 2.06x increase in training speed, while RL training with 128k-token outputs improves the model's performance on AIME2025 from 70.9\% to 85.1\% and on BeyondAIME from 50.7\% to 61.9\%, even surpassing Qwen3-235B-A22B with remarkable gains. These findings underscore the potential of our methods to advance the reasoning capabilities of LLMs with ultra-long sequence generation. We will release our code and model for further use by the community.