Retrieval augmented generation based dynamic prompting for few-shot biomedical named entity recognition using large language models
作者: Yao Ge, Sudeshna Das, Yuting Guo, Abeed Sarker
分类: cs.CL, cs.AI
发布日期: 2025-07-25
备注: 31 pages, 4 figures, 15 tables
💡 一句话要点
提出基于检索增强生成动态提示的少样本生物医学命名实体识别方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 生物医学命名实体识别 大型语言模型 少样本学习 检索增强生成 动态提示 上下文学习 提示工程
📋 核心要点
- 现有少样本生物医学NER方法在利用大型语言模型时,面临着性能不足的挑战,尤其是在提示工程方面。
- 论文提出一种基于检索增强生成(RAG)的动态提示策略,通过上下文相似性选择示例并动态更新提示,提升模型性能。
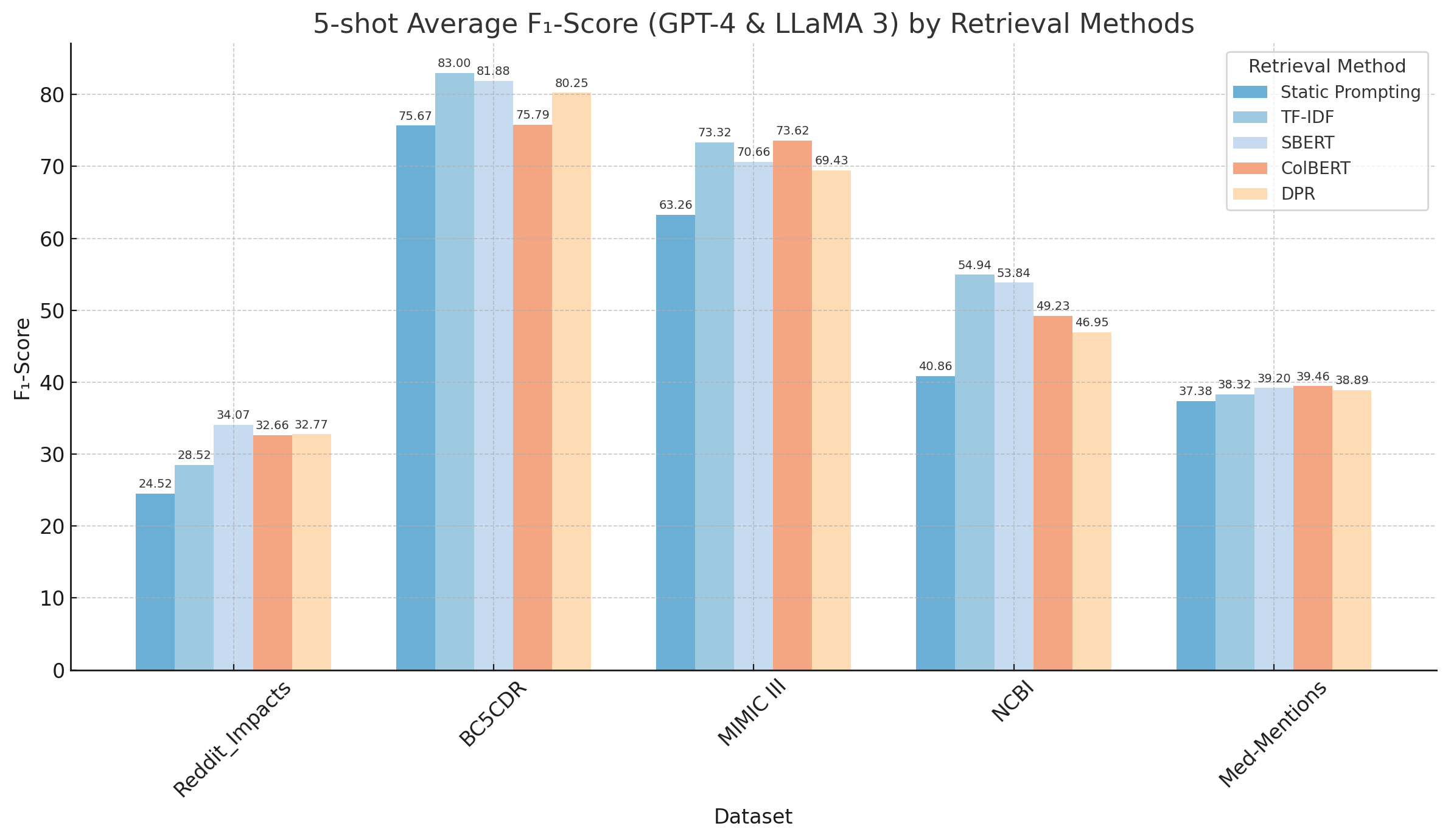
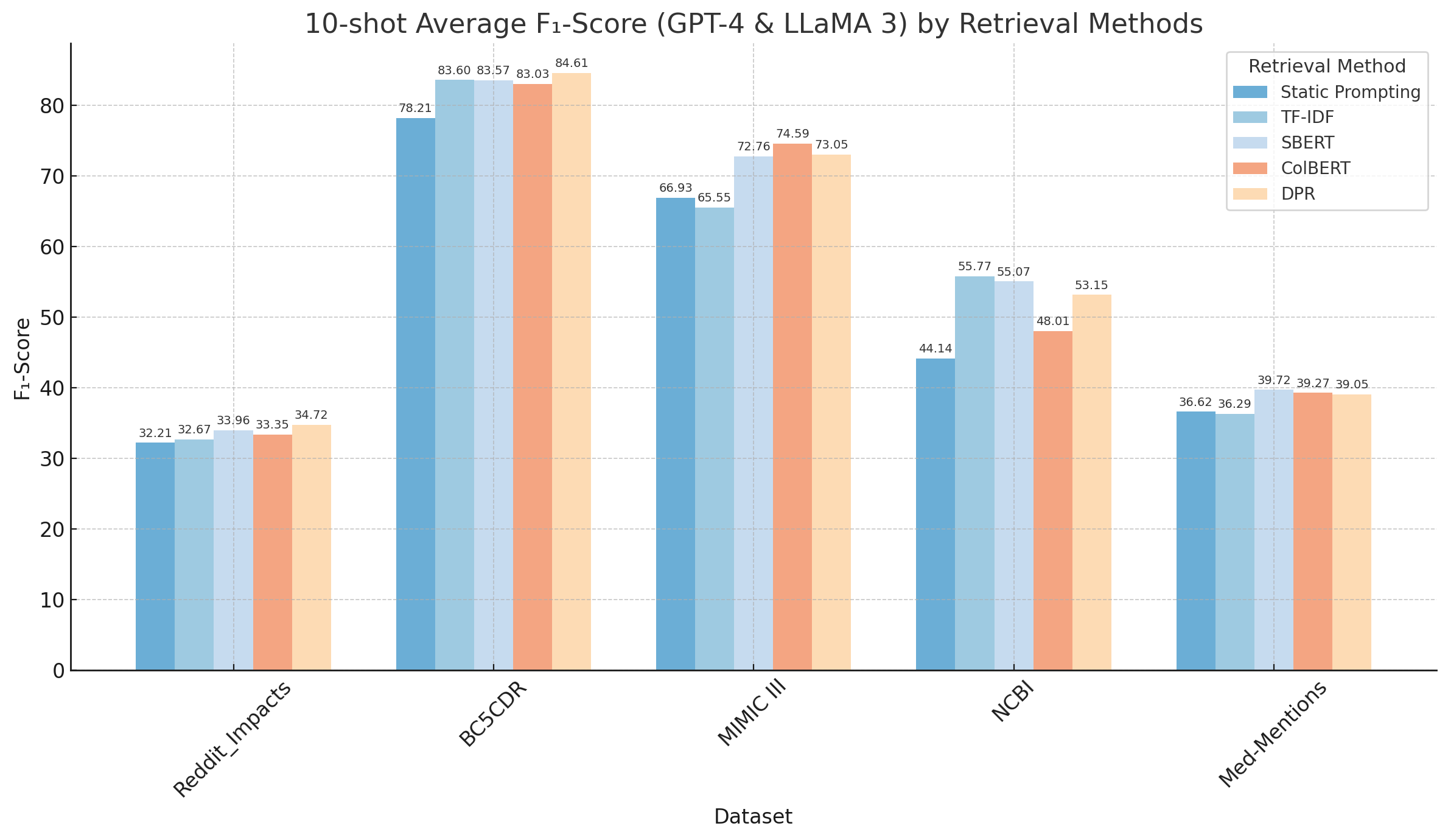
- 实验结果表明,动态提示方法显著提高了生物医学NER的F1分数,TF-IDF和SBERT检索方法表现最佳。
📝 摘要(中文)
生物医学命名实体识别(NER)是一项高实用性的自然语言处理(NLP)任务,大型语言模型(LLMs)在该领域展现出潜力,尤其是在少样本场景下(即训练数据有限)。本文通过研究一种涉及检索增强生成(RAG)的动态提示策略,旨在解决LLMs在少样本生物医学NER中的性能挑战。该方法基于输入文本的相似性选择带标注的上下文学习示例,并在推理过程中为每个实例动态更新提示。我们实施并优化了静态和动态提示工程技术,并在五个生物医学NER数据集上进行了评估。相对于基本静态提示,使用结构化组件的静态提示使GPT-4的平均F1分数提高了12%,GPT-3.5和LLaMA 3-70B提高了11%。动态提示进一步提高了性能,其中TF-IDF和SBERT检索方法产生了最佳结果,在5-shot和10-shot设置中分别将平均F1分数提高了7.3%和5.6%。这些发现突出了通过RAG进行上下文自适应提示在生物医学NER中的实用性。
🔬 方法详解
问题定义:论文旨在解决少样本生物医学命名实体识别(NER)任务中,大型语言模型(LLMs)性能不足的问题。现有的方法,特别是静态提示方法,无法充分利用上下文信息,导致模型在处理不同类型的生物医学文本时表现不佳。
核心思路:论文的核心思路是利用检索增强生成(RAG)技术,为每个输入文本动态生成最合适的提示。通过检索与输入文本相似的已标注样本,并将这些样本作为上下文信息添加到提示中,从而使LLM能够更好地理解输入文本的含义,并更准确地识别命名实体。
技术框架:整体框架包含以下几个主要步骤:1) 检索:使用TF-IDF或SBERT等方法,从已标注的样本库中检索与输入文本最相似的样本。2) 生成提示:将检索到的相似样本作为上下文信息,构建动态提示。提示中包含任务描述、输入文本和相似样本。3) LLM推理:将动态提示输入到LLM中,进行命名实体识别。4) 后处理:对LLM的输出进行后处理,提取识别出的命名实体。
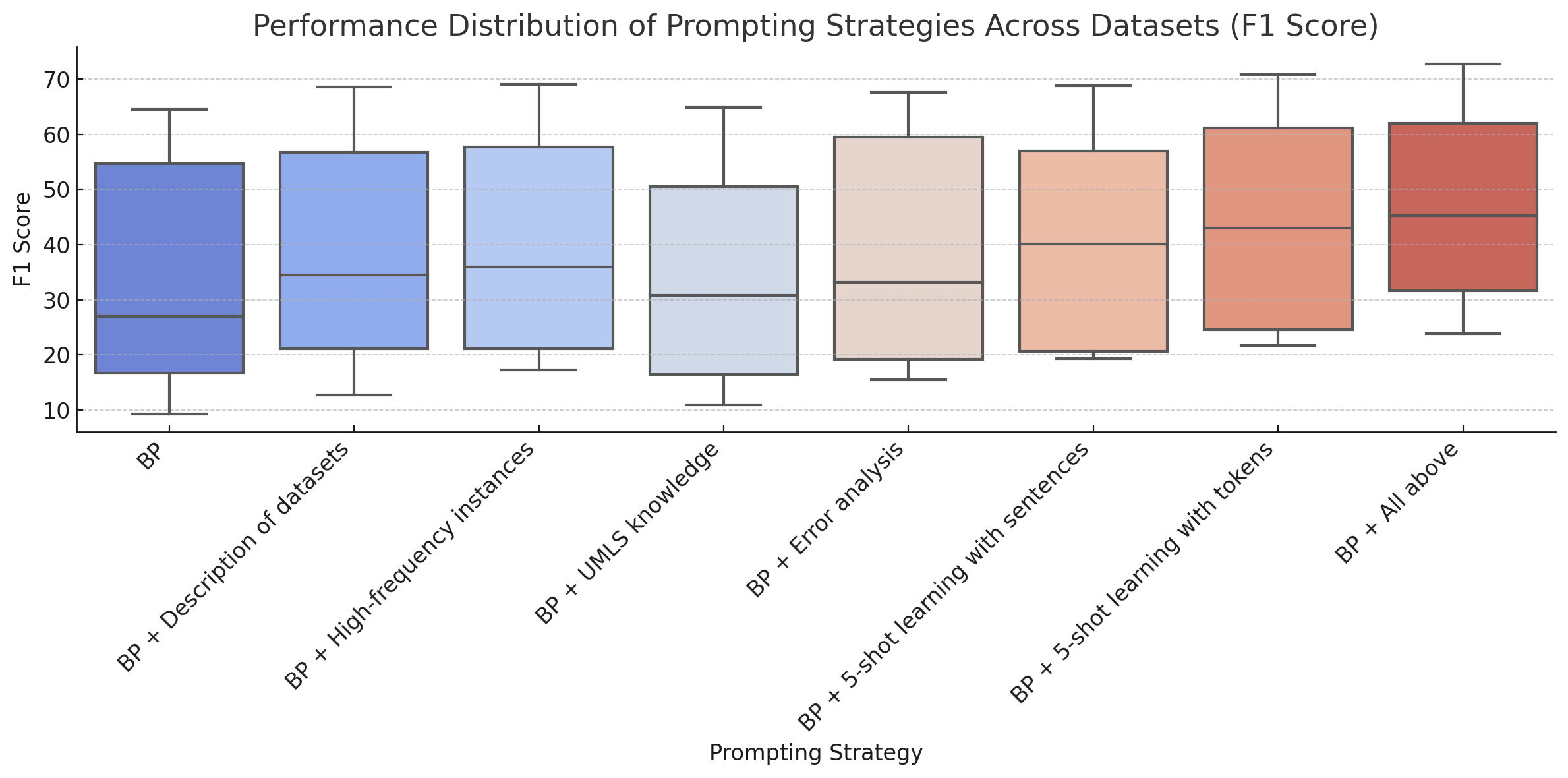
关键创新:最重要的技术创新点在于动态提示策略。与传统的静态提示方法相比,动态提示能够根据输入文本的特点,自适应地调整提示内容,从而更好地利用上下文信息,提高模型的泛化能力。此外,论文还比较了不同的检索方法(TF-IDF和SBERT)对性能的影响。
关键设计:论文的关键设计包括:1) 使用TF-IDF和SBERT作为检索方法,评估其对性能的影响。2) 设计结构化的静态提示,包含任务描述、输入文本和预定义的实体类型。3) 评估不同数量的上下文样本(5-shot和10-shot)对性能的影响。4) 使用F1分数作为评估指标,评估模型在五个生物医学NER数据集上的性能。
🖼️ 关键图片
📊 实验亮点
实验结果表明,动态提示策略显著提高了生物医学NER的性能。使用结构化组件的静态提示使GPT-4的平均F1分数提高了12%,GPT-3.5和LLaMA 3-70B提高了11%。动态提示进一步提高了性能,其中TF-IDF和SBERT检索方法在5-shot和10-shot设置中分别将平均F1分数提高了7.3%和5.6%。这些结果表明,基于RAG的动态提示是一种有效的少样本生物医学NER方法。
🎯 应用场景
该研究成果可应用于生物医学文本挖掘、药物研发、临床决策支持等领域。通过提高生物医学NER的准确率,可以更有效地从海量生物医学文献中提取关键信息,加速科研进程,并为临床医生提供更准确的诊断和治疗建议。未来,该方法可以扩展到其他自然语言处理任务,如关系抽取、事件抽取等。
📄 摘要(原文)
Biomedical named entity recognition (NER) is a high-utility natural language processing (NLP) task, and large language models (LLMs) show promise particularly in few-shot settings (i.e., limited training data). In this article, we address the performance challenges of LLMs for few-shot biomedical NER by investigating a dynamic prompting strategy involving retrieval-augmented generation (RAG). In our approach, the annotated in-context learning examples are selected based on their similarities with the input texts, and the prompt is dynamically updated for each instance during inference. We implemented and optimized static and dynamic prompt engineering techniques and evaluated them on five biomedical NER datasets. Static prompting with structured components increased average F1-scores by 12% for GPT-4, and 11% for GPT-3.5 and LLaMA 3-70B, relative to basic static prompting. Dynamic prompting further improved performance, with TF-IDF and SBERT retrieval methods yielding the best results, improving average F1-scores by 7.3% and 5.6% in 5-shot and 10-shot settings, respectively. These findings highlight the utility of contextually adaptive prompts via RAG for biomedical NER.