Trustworthy Reasoning: Evaluating and Enhancing Factual Accuracy in LLM Intermediate Thought Processes
作者: Rui Jiao, Yue Zhang, Jinku Li
分类: cs.CL, cs.AI
发布日期: 2025-07-25 (更新: 2025-08-02)
💡 一句话要点
提出可信推理框架,提升LLM中间推理步骤的事实准确性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 事实准确性 可信推理 强化学习 机制可解释性
📋 核心要点
- 现有LLM在复杂推理中,即使答案正确,中间步骤也可能包含事实错误,这在高风险领域造成潜在危害。
- 提出可信推理框架,包含事实检查分类器、增强的GRPO强化学习和机制可解释性分析,提升推理过程的事实准确性。
- 实验表明,该方法显著提升了LLM的事实稳健性,最高提升达49.90%,并在多个基准测试中保持或提升了性能。
📝 摘要(中文)
本文提出了一个新颖的框架,旨在解决大型语言模型(LLM)中一个关键的脆弱性问题:即使最终答案正确,中间推理步骤中也普遍存在事实不准确的情况。这种现象在高风险领域(如医疗保健、法律分析和科学研究)中构成了重大风险,因为错误但自信的推理可能会误导用户做出危险的决策。该框架集成了三个核心组件:(1)一个专门的事实检查分类器,该分类器在反事实增强数据上进行训练,以检测推理链中细微的事实不一致;(2)一种增强的群体相对策略优化(GRPO)强化学习方法,通过多维奖励来平衡事实性、连贯性和结构正确性;(3)一种机制可解释性方法,用于检查事实性改进如何在推理过程中体现在模型激活中。对多个最先进模型的广泛评估揭示了令人担忧的模式:即使是像Claude-3.7和GPT-o1这样的领先模型,其推理事实准确性也分别只有81.93%和82.57%。我们的方法显著提高了事实稳健性(高达49.90%的改进),同时保持或提高了在具有挑战性的基准(包括Math-500、AIME-2024和GPQA)上的性能。此外,我们的神经激活水平分析提供了可操作的见解,了解事实增强如何重塑模型架构中的推理轨迹,为未来通过激活引导优化明确针对事实稳健性的训练方法奠定了基础。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在中间推理步骤中存在的事实不准确问题。即使LLM最终给出了正确的答案,其推理过程中可能包含错误的事实陈述,这在高风险领域(如医疗、法律等)会产生误导性影响。现有方法未能有效解决这一问题,缺乏对中间推理步骤事实性的有效评估和改进机制。
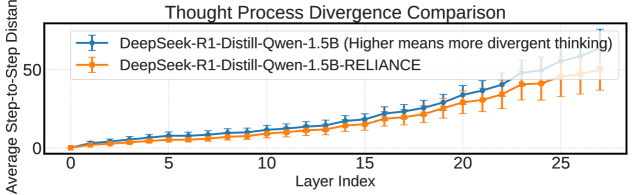
核心思路:论文的核心思路是通过构建一个综合框架,从事实检查、强化学习和机制可解释性三个维度来提升LLM推理过程的事实准确性。该框架旨在识别并纠正推理链中的事实错误,同时保持推理的连贯性和结构正确性。通过对模型激活的分析,理解事实性改进在模型内部的体现,为未来的训练方法提供指导。
技术框架:该框架包含三个主要模块:(1)事实检查分类器:用于检测推理链中细微的事实不一致性,该分类器在反事实增强数据上进行训练,以提高检测能力。(2)增强的GRPO强化学习:使用强化学习方法优化LLM的推理过程,通过多维奖励函数平衡事实性、连贯性和结构正确性。GRPO(Group Relative Policy Optimization)是一种策略优化算法,用于在多个策略之间进行选择和优化。(3)机制可解释性分析:通过分析模型在推理过程中的激活状态,理解事实性改进如何在模型内部体现,为未来的训练方法提供指导。
关键创新:该论文的关键创新在于:(1)提出了一个综合性的框架,将事实检查、强化学习和机制可解释性相结合,以提升LLM推理过程的事实准确性。(2)设计了一个专门的事实检查分类器,能够检测推理链中细微的事实不一致性。(3)使用增强的GRPO强化学习方法,通过多维奖励函数平衡事实性、连贯性和结构正确性。(4)通过机制可解释性分析,理解事实性改进在模型内部的体现,为未来的训练方法提供指导。
关键设计:事实检查分类器使用反事实增强数据进行训练,以提高检测能力。GRPO强化学习方法使用多维奖励函数,包括事实性奖励、连贯性奖励和结构正确性奖励。事实性奖励基于事实检查分类器的输出,连贯性奖励基于推理链的流畅性和逻辑性,结构正确性奖励基于推理步骤的完整性和正确性。机制可解释性分析通过分析模型在推理过程中的激活状态,识别与事实性相关的神经元和连接,为未来的训练方法提供指导。
🖼️ 关键图片

📊 实验亮点
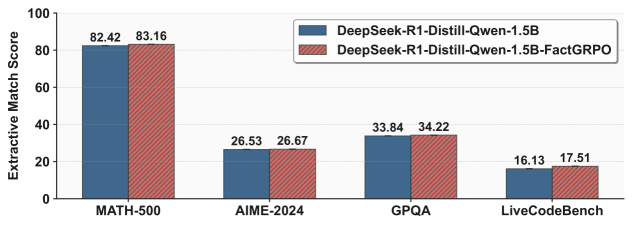
实验结果表明,该方法显著提高了LLM的事实稳健性,最高提升达49.90%。即使是像Claude-3.7和GPT-o1这样的领先模型,其推理事实准确性也分别只有81.93%和82.57%,经过该方法优化后,性能得到了显著提升。此外,该方法在Math-500、AIME-2024和GPQA等具有挑战性的基准测试中保持或提升了性能,证明了其有效性和泛化能力。
🎯 应用场景
该研究成果可广泛应用于需要高度可信推理的领域,如医疗诊断、法律咨询、金融分析和科学研究。通过提高LLM推理过程的事实准确性,可以减少错误信息带来的风险,提升决策质量,并增强用户对AI系统的信任。未来,该技术可用于构建更可靠、更安全的AI应用,并促进AI在关键领域的广泛应用。
📄 摘要(原文)
We present a novel framework addressing a critical vulnerability in Large Language Models (LLMs): the prevalence of factual inaccuracies within intermediate reasoning steps despite correct final answers. This phenomenon poses substantial risks in high-stakes domains including healthcare, legal analysis, and scientific research, where erroneous yet confidently presented reasoning can mislead users into dangerous decisions. Our framework integrates three core components: (1) a specialized fact-checking classifier trained on counterfactually augmented data to detect subtle factual inconsistencies within reasoning chains; (2) an enhanced Group Relative Policy Optimization (GRPO) reinforcement learning approach that balances factuality, coherence, and structural correctness through multi-dimensional rewards; and (3) a mechanistic interpretability method examining how factuality improvements manifest in model activations during reasoning processes. Extensive evaluation across multi state-of-the-art models reveals concerning patterns: even leading models like Claude-3.7 and GPT-o1 demonstrate reasoning factual accuracy of only 81.93% and 82.57% respectively. Our approach significantly enhances factual robustness (up to 49.90% improvement) while maintaining or improving performance on challenging benchmarks including Math-500, AIME-2024, and GPQA. Furthermore, our neural activation-level analysis provides actionable insights into how factual enhancements reshape reasoning trajectories within model architectures, establishing foundations for future training methodologies that explicitly target factual robustness through activation-guided optimization.