Ta-G-T: Subjectivity Capture in Table to Text Generation via RDF Graphs
作者: Ronak Upasham, Tathagata Dey, Pushpak Bhattacharyya
分类: cs.CL
发布日期: 2025-07-25
💡 一句话要点
提出Ta-G-T框架,通过RDF图在表格到文本生成中融入主观性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 表格到文本生成 主观性建模 资源描述框架 知识图谱 文本生成 自然语言处理
📋 核心要点
- 现有T2T方法侧重客观描述,缺乏对表格数据主观解读能力的探索。
- 提出Ta-G-T框架,利用RDF三元组作为中间表示,分阶段融入主观性。
- 实验表明,该方法在事实准确性与主观性平衡方面表现出色,性能可与GPT-3.5媲美。
📝 摘要(中文)
现有的表格到文本(T2T)生成方法主要关注对表格数据的客观描述。然而,生成包含主观性的文本,即超越原始数值数据的解释,仍未被充分探索。为了解决这个问题,我们提出了一种新颖的流程,利用中间表示从表格中生成客观和主观文本。我们的三阶段流程包括:1)提取资源描述框架(RDF)三元组,2)将文本聚合成连贯的叙述,3)注入主观性以丰富生成的文本。通过整合RDF,我们的方法增强了事实准确性,同时保持了可解释性。与GPT-3.5、Mistral-7B和Llama-2等大型语言模型(LLM)不同,我们的流程采用较小的、微调的T5模型,同时实现了与GPT-3.5相当的性能,并在多个指标上优于Mistral-7B和Llama-2。我们通过定量和定性分析评估了我们的方法,证明了其在平衡事实准确性和主观解释方面的有效性。据我们所知,这是第一个提出结构化T2T生成流程的工作,该流程集成了中间表示,以增强事实正确性和主观性。
🔬 方法详解
问题定义:论文旨在解决表格到文本生成任务中缺乏主观性表达的问题。现有方法主要关注客观数据的描述,忽略了对数据背后含义的解读和主观视角的融入,使得生成的文本缺乏深度和多样性。
核心思路:论文的核心思路是通过引入资源描述框架(RDF)作为中间表示,将表格数据转化为结构化的知识图谱,从而方便后续的主观性注入。这种方法能够更好地捕捉表格数据中的语义关系,并为生成更具解释性和主观性的文本提供基础。
技术框架:该方法包含三个主要阶段:1) RDF三元组提取:从表格数据中提取RDF三元组,构建知识图谱;2) 文本聚合:将提取的RDF三元组聚合成连贯的叙述性文本;3) 主观性注入:在生成的文本中融入主观性的表达,例如情感、观点等。整个流程旨在平衡事实准确性和主观解释。
关键创新:该方法的主要创新在于将RDF图引入到表格到文本生成任务中,并将其作为中间表示来增强主观性表达。与直接使用大型语言模型生成文本的方法不同,该方法通过结构化的知识表示和分阶段的处理,实现了更好的可控性和可解释性。
关键设计:该方法使用T5模型进行微调,用于文本聚合和主观性注入。RDF三元组的提取规则和主观性注入策略是关键的设计细节,需要根据具体的应用场景进行调整。损失函数的设计旨在平衡事实准确性和主观性表达,可能包括交叉熵损失、对比学习损失等。
🖼️ 关键图片
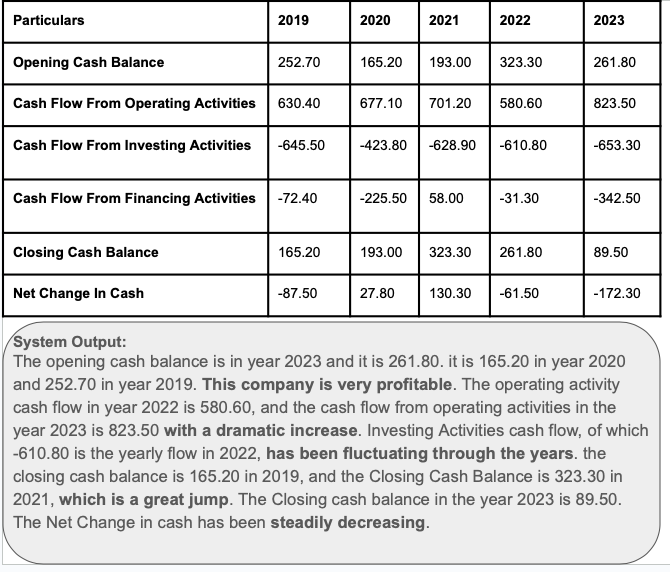

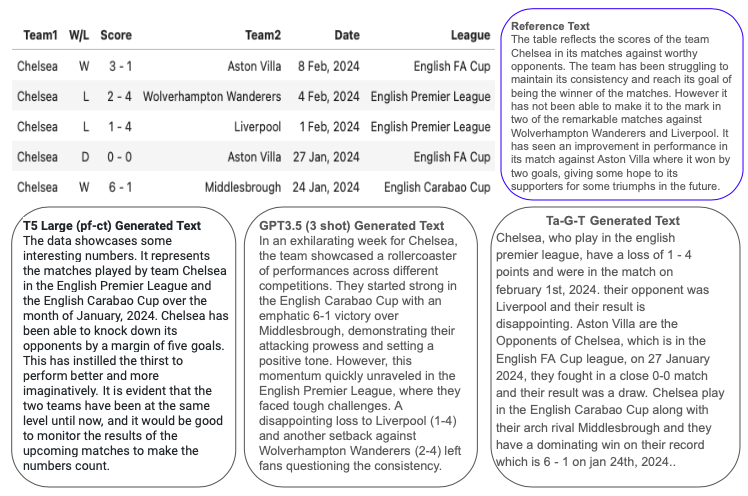
📊 实验亮点
实验结果表明,该方法在表格到文本生成任务中取得了显著的性能提升,与GPT-3.5相比,在性能上可与之媲美,并在某些指标上优于Mistral-7B和Llama-2。这表明该方法在平衡事实准确性和主观性表达方面具有优势。
🎯 应用场景
该研究成果可应用于报告生成、新闻摘要、数据分析等领域,提升文本生成的主观性和可解释性。例如,在金融报告生成中,可以自动生成包含市场分析师观点的报告,为投资者提供更全面的信息。未来可进一步探索更复杂的主观性表达方式,并应用于更多领域。
📄 摘要(原文)
In Table-to-Text (T2T) generation, existing approaches predominantly focus on providing objective descriptions of tabular data. However, generating text that incorporates subjectivity, where subjectivity refers to interpretations beyond raw numerical data, remains underexplored. To address this, we introduce a novel pipeline that leverages intermediate representations to generate both objective and subjective text from tables. Our three-stage pipeline consists of: 1) extraction of Resource Description Framework (RDF) triples, 2) aggregation of text into coherent narratives, and 3) infusion of subjectivity to enrich the generated text. By incorporating RDFs, our approach enhances factual accuracy while maintaining interpretability. Unlike large language models (LLMs) such as GPT-3.5, Mistral-7B, and Llama-2, our pipeline employs smaller, fine-tuned T5 models while achieving comparable performance to GPT-3.5 and outperforming Mistral-7B and Llama-2 in several metrics. We evaluate our approach through quantitative and qualitative analyses, demonstrating its effectiveness in balancing factual accuracy with subjective interpretation. To the best of our knowledge, this is the first work to propose a structured pipeline for T2T generation that integrates intermediate representations to enhance both factual correctness and subjectivity.