Towards Inclusive NLP: Assessing Compressed Multilingual Transformers across Diverse Language Benchmarks
作者: Maitha Alshehhi, Ahmed Sharshar, Mohsen Guizani
分类: cs.CL
发布日期: 2025-07-25
备注: Published in the 3rd International Workshop on Generalizing from Limited Resources in the Open World. Workshop at International Joint Conference on Artificial Intelligence (IJCAI) 2025
💡 一句话要点
评估压缩多语言Transformer在不同语言基准上的性能,促进包容性NLP
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多语言模型 模型压缩 剪枝 量化 低资源语言 跨语言迁移学习 性能评估
📋 核心要点
- 现有LLM在低资源语言(如卡纳达语和阿拉伯语)上的能力尚不明确,面临资源稀缺和语言复杂性挑战。
- 通过对LLM进行剪枝和量化等压缩,在保证性能的同时提升效率,探索更优的多语言模型构建策略。
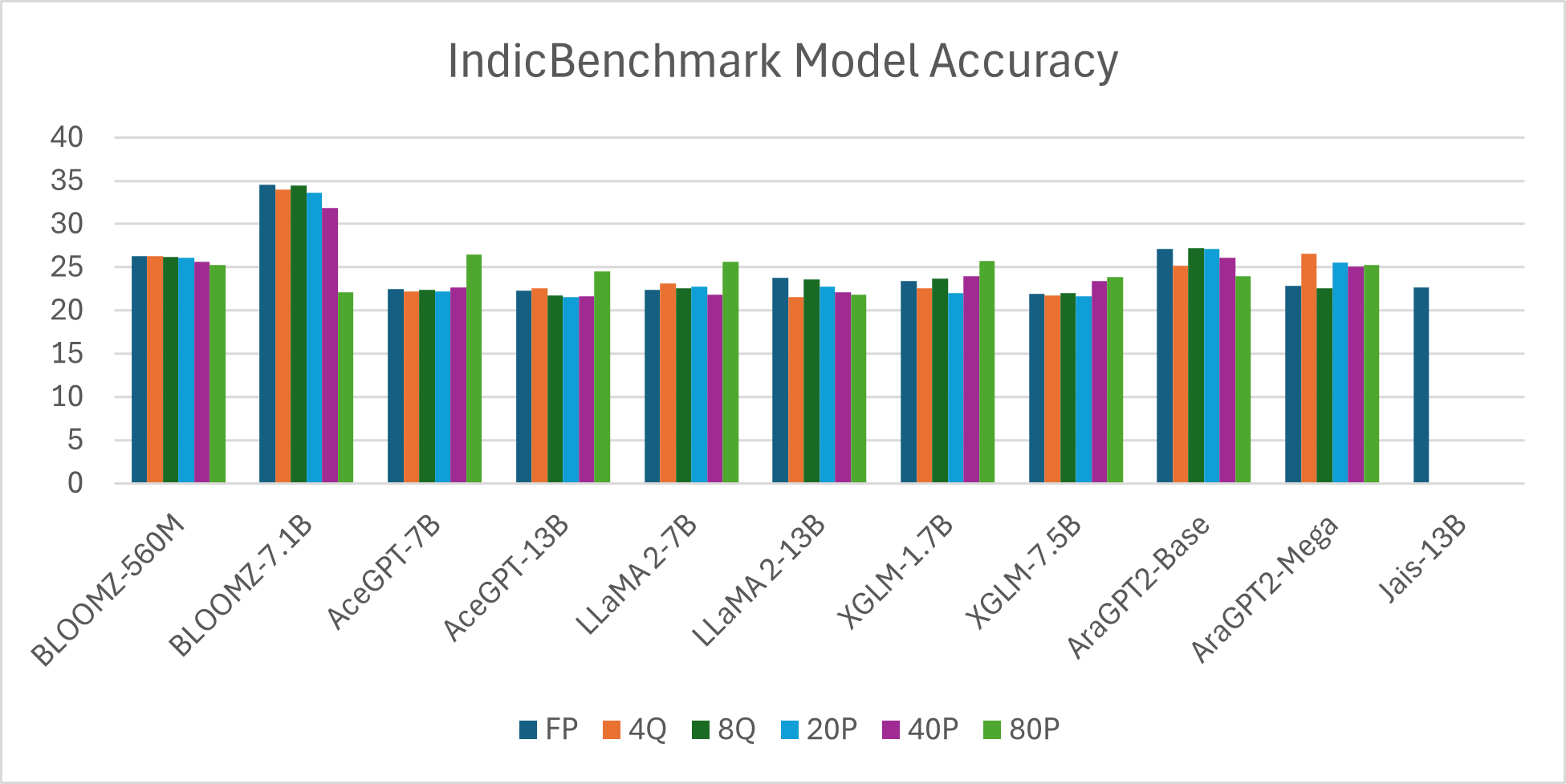
- 实验表明,多语言模型优于单语模型,量化能有效保持精度,但过度剪枝会降低性能,尤其是在大型模型中。
📝 摘要(中文)
本文旨在评估多语言和单语大型语言模型(LLM)在阿拉伯语、英语和印度语言上的性能,特别关注剪枝和量化等模型压缩策略的影响。研究结果表明,由于语言多样性和资源可用性,BLOOMZ、AceGPT、Jais、LLaMA-2、XGLM和AraGPT2等SOTA LLM的性能存在显著差异。研究发现,模型的跨语言版本在各个方面都优于其特定语言版本,表明存在显著的跨语言迁移优势。量化(4位和8位)在保持模型精度的同时有效地提高了效率,但激进的剪枝会显著降低性能,尤其是在较大的模型中。研究结果指出了构建可扩展且公平的多语言NLP解决方案的关键策略,并强调需要进行干预以解决低资源环境中的幻觉和泛化错误。
🔬 方法详解
问题定义:论文旨在评估大型语言模型(LLM)在不同语言环境下的性能,特别是低资源语言。现有方法在低资源语言上的表现不佳,并且模型体积庞大,计算成本高昂,难以部署和应用。因此,如何构建既能保持性能,又能高效运行的多语言LLM是一个关键问题。
核心思路:论文的核心思路是通过模型压缩技术(剪枝和量化)来减小模型体积,提高计算效率,同时评估这些压缩技术对不同语言性能的影响。通过对比多语言模型和单语模型在不同语言上的表现,探索跨语言迁移学习的潜力。
技术框架:论文的整体框架包括以下几个步骤:1) 选择一系列多语言和单语LLM,如BLOOMZ、AceGPT、Jais、LLaMA-2、XGLM和AraGPT2。2) 对这些模型应用不同的压缩策略,包括剪枝和量化(4-bit和8-bit)。3) 在一系列语言基准测试中评估压缩后的模型的性能,包括阿拉伯语、英语和印度语言。4) 分析实验结果,比较不同模型和压缩策略的性能差异,并总结经验教训。
关键创新:论文的关键创新在于系统性地评估了模型压缩技术对多语言LLM在不同语言上的性能影响。以往的研究可能更多关注模型压缩对高资源语言的影响,而忽略了低资源语言的特殊性。本文的研究结果为构建更高效、更公平的多语言NLP解决方案提供了重要的指导。
关键设计:论文的关键设计包括:1) 选择具有代表性的多语言和单语LLM。2) 采用不同的剪枝策略,例如权重剪枝。3) 使用不同的量化方法,例如4-bit和8-bit量化。4) 选择涵盖不同语言和任务的基准测试数据集。5) 采用标准的评估指标,例如准确率和F1值。
🖼️ 关键图片
📊 实验亮点
实验结果表明,多语言模型通常优于其单语对应模型,突显了跨语言迁移学习的优势。量化(4位和8位)在保持模型精度方面表现出色,同时提高了效率。然而,激进的剪枝会显著降低性能,尤其是在较大的模型中。例如,在特定低资源语言任务上,量化后的模型性能仅略有下降,但模型大小显著减小。
🎯 应用场景
该研究成果可应用于构建更高效、更公平的多语言NLP系统,例如跨语言机器翻译、多语言信息检索、以及面向低资源语言的智能助手。通过模型压缩,可以降低部署成本,使其更容易在资源受限的环境中使用。未来的研究可以进一步探索更先进的模型压缩技术,并将其应用于更多低资源语言。
📄 摘要(原文)
Although LLMs have attained significant success in high-resource languages, their capacity in low-resource linguistic environments like Kannada and Arabic is not yet fully understood. This work benchmarking the performance of multilingual and monolingual Large Language Models (LLMs) across Arabic, English, and Indic languages, with particular emphasis on the effects of model compression strategies such as pruning and quantization. Findings shows significant performance differences driven by linguistic diversity and resource availability on SOTA LLMS as BLOOMZ, AceGPT, Jais, LLaMA-2, XGLM, and AraGPT2. We find that multilingual versions of the model outperform their language-specific counterparts across the board, indicating substantial cross-lingual transfer benefits. Quantization (4-bit and 8-bit) is effective in maintaining model accuracy while promoting efficiency, but aggressive pruning significantly compromises performance, especially in bigger models. Our findings pinpoint key strategies to construct scalable and fair multilingual NLP solutions and underscore the need for interventions to address hallucination and generalization errors in the low-resource setting.