Efficient Attention Mechanisms for Large Language Models: A Survey
作者: Yutao Sun, Zhenyu Li, Yike Zhang, Tengyu Pan, Bowen Dong, Yuyi Guo, Jianyong Wang
分类: cs.CL, cs.AI
发布日期: 2025-07-25 (更新: 2025-08-07)
备注: work in progress
💡 一句话要点
综述:高效注意力机制助力大规模语言模型处理长文本
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 高效注意力机制 大型语言模型 线性注意力 稀疏注意力 Transformer 长文本建模 预训练语言模型
📋 核心要点
- 自注意力机制的二次复杂度是大型语言模型处理长文本的瓶颈,限制了模型的可扩展性。
- 论文综述了线性注意力和稀疏注意力两种主要的高效注意力机制,旨在降低计算复杂度和内存占用。
- 分析了高效注意力机制在大型预训练语言模型中的应用,并探讨了算法创新与硬件部署策略。
📝 摘要(中文)
基于Transformer的架构已成为大型语言模型的主流骨干。然而,自注意力机制的二次时间和内存复杂度仍然是高效长文本建模的根本障碍。为了解决这个限制,最近的研究引入了两种主要的有效注意力机制。线性注意力方法通过核近似、循环公式或快速权重动态实现线性复杂度,从而以降低的计算开销实现可扩展的推理。相反,稀疏注意力技术将注意力计算限制于基于固定模式、块状路由或聚类策略选择的token子集,从而在保持上下文覆盖的同时提高效率。本综述系统而全面地概述了这些发展,整合了算法创新和硬件层面的考虑。此外,我们分析了高效注意力机制在大型预训练语言模型中的应用,包括完全基于高效注意力机制构建的架构以及结合局部和全局组件的混合设计。通过将理论基础与实际部署策略相结合,这项工作旨在为推进可扩展和高效语言模型的设计提供基础参考。
🔬 方法详解
问题定义:大型语言模型依赖Transformer架构,但自注意力机制的计算复杂度随序列长度呈二次方增长,这限制了模型处理长文本的能力,并带来了巨大的计算和内存开销。现有方法难以在保证模型性能的同时,有效降低计算复杂度。
核心思路:论文的核心思路是综述并分析两种主要的高效注意力机制:线性注意力和稀疏注意力。线性注意力旨在通过近似计算降低复杂度,而稀疏注意力则通过选择性地关注部分token来减少计算量。通过对这些方法的深入分析,为未来高效语言模型的设计提供指导。
技术框架:该综述首先介绍了自注意力机制的原理和局限性,然后分别详细阐述了线性注意力和稀疏注意力机制。对于每种机制,都分析了其核心思想、具体实现方式以及优缺点。此外,还讨论了这些机制在大型预训练语言模型中的应用,包括完全基于高效注意力机制构建的架构以及混合架构。最后,探讨了硬件层面的考虑因素。
关键创新:该综述的关键创新在于对现有高效注意力机制进行了系统而全面的整理和分析,并将其与大型预训练语言模型相结合进行讨论。它不仅涵盖了算法层面的创新,还考虑了硬件层面的因素,为研究人员提供了一个全面的视角。
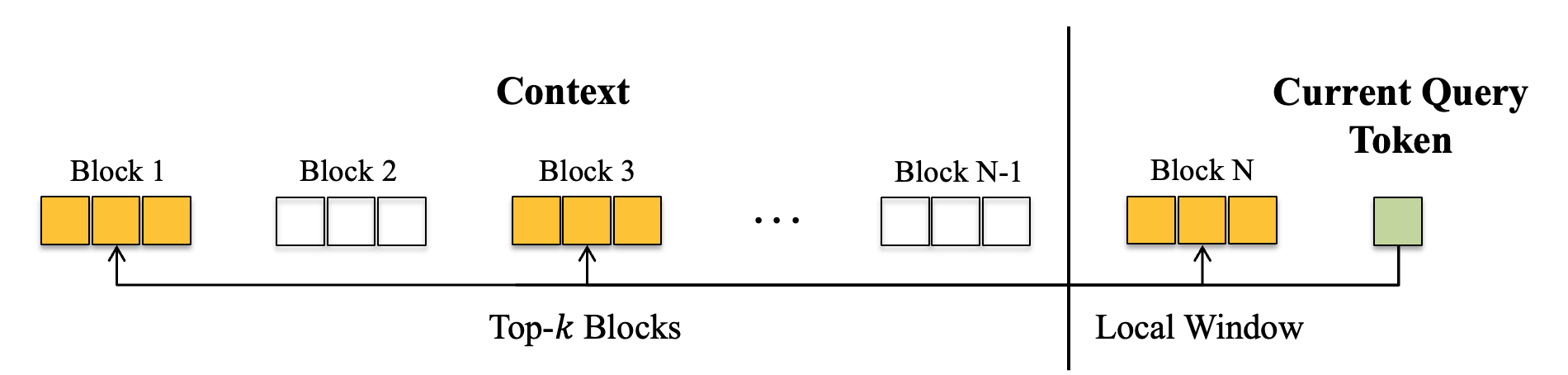
关键设计:线性注意力机制的关键设计包括核函数的选择、循环结构的构建以及快速权重动态的实现。稀疏注意力机制的关键设计包括固定模式的选择、块状路由策略的制定以及聚类算法的应用。此外,在将这些机制应用于大型预训练语言模型时,需要仔细考虑局部和全局组件的平衡。
🖼️ 关键图片


📊 实验亮点
该综述全面梳理了线性注意力和稀疏注意力两种高效注意力机制,并分析了它们在大型预训练语言模型中的应用。通过对比不同方法的优缺点,为研究人员提供了选择和设计高效注意力机制的指导。该综述还考虑了硬件层面的因素,为实际部署提供了参考。
🎯 应用场景
该研究成果可应用于各种需要处理长文本的自然语言处理任务,例如机器翻译、文本摘要、问答系统和对话生成。通过降低计算复杂度和内存占用,可以使大型语言模型在资源受限的环境中部署,并加速模型的训练和推理过程。未来的影响在于推动更高效、更可扩展的语言模型的发展,从而更好地理解和生成自然语言。
📄 摘要(原文)
Transformer-based architectures have become the prevailing backbone of large language models. However, the quadratic time and memory complexity of self-attention remains a fundamental obstacle to efficient long-context modeling. To address this limitation, recent research has introduced two principal categories of efficient attention mechanisms. Linear attention methods achieve linear complexity through kernel approximations, recurrent formulations, or fastweight dynamics, thereby enabling scalable inference with reduced computational overhead. Sparse attention techniques, in contrast, limit attention computation to selected subsets of tokens based on fixed patterns, block-wise routing, or clustering strategies, enhancing efficiency while preserving contextual coverage. This survey provides a systematic and comprehensive overview of these developments, integrating both algorithmic innovations and hardware-level considerations. In addition, we analyze the incorporation of efficient attention into largescale pre-trained language models, including both architectures built entirely on efficient attention and hybrid designs that combine local and global components. By aligning theoretical foundations with practical deployment strategies, this work aims to serve as a foundational reference for advancing the design of scalable and efficient language models.