GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning
作者: Lakshya A Agrawal, Shangyin Tan, Dilara Soylu, Noah Ziems, Rishi Khare, Krista Opsahl-Ong, Arnav Singhvi, Herumb Shandilya, Michael J Ryan, Meng Jiang, Christopher Potts, Koushik Sen, Alexandros G. Dimakis, Ion Stoica, Dan Klein, Matei Zaharia, Omar Khattab
分类: cs.CL, cs.AI, cs.LG, cs.SE
发布日期: 2025-07-25
💡 一句话要点
GEPA:通过反思式提示进化超越强化学习,提升LLM任务性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 提示优化 强化学习 自然语言反思 遗传算法
📋 核心要点
- 现有强化学习方法(如GRPO)在调整LLM以适应下游任务时,需要大量的rollout,效率较低。
- GEPA通过自然语言反思,从系统级轨迹中诊断问题、更新提示,并结合帕累托前沿的经验,实现高效学习。
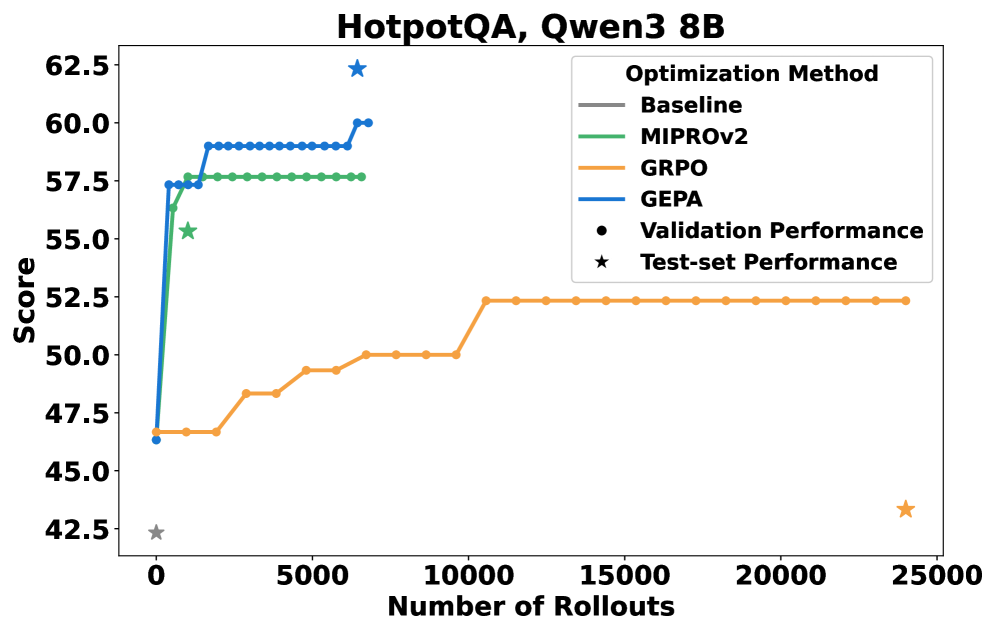
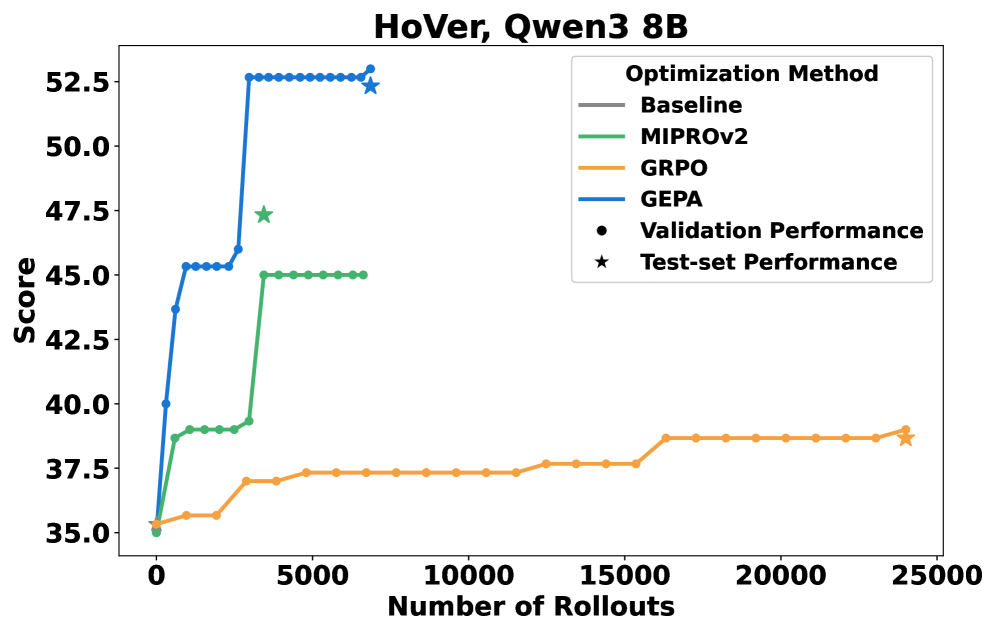
- 实验表明,GEPA在多个任务上优于GRPO和MIPROv2,同时显著减少了rollout次数,提升了性能。
📝 摘要(中文)
大型语言模型(LLMs)越来越多地通过强化学习(RL)方法(如Group Relative Policy Optimization (GRPO))来适应下游任务,但这些方法通常需要数千次rollout才能学习新任务。我们认为,与从稀疏标量奖励中导出的策略梯度相比,语言的可解释性通常可以为LLM提供更丰富的学习媒介。为了验证这一点,我们引入了GEPA (Genetic-Pareto),这是一种提示优化器,它充分结合了自然语言反思,从试错中学习高级规则。给定任何包含一个或多个LLM提示的AI系统,GEPA采样系统级轨迹(例如,推理、工具调用和工具输出),并以自然语言反思它们以诊断问题,提出和测试提示更新,并结合来自其自身尝试的帕累托前沿的互补经验。由于GEPA的设计,它通常可以将少量rollout转化为大量的质量提升。在四个任务中,GEPA的性能平均比GRPO高10%,最高可达20%,同时使用的rollout最多减少35倍。GEPA还在两个LLM上优于领先的提示优化器MIPROv2超过10%,并展示了作为代码优化推理时搜索策略的有希望的结果。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在适应下游任务时,传统强化学习方法(如GRPO)需要大量样本(rollout)的问题。这些方法效率低下,难以快速适应新任务。现有的提示优化方法也存在提升空间。
核心思路:论文的核心思路是利用自然语言的反思能力,让LLM能够从自身的错误和成功经验中学习。通过分析系统级轨迹(推理、工具调用等),诊断问题并提出改进提示的建议。这种方法模仿了人类的试错学习过程,并利用语言的丰富表达能力来指导学习。
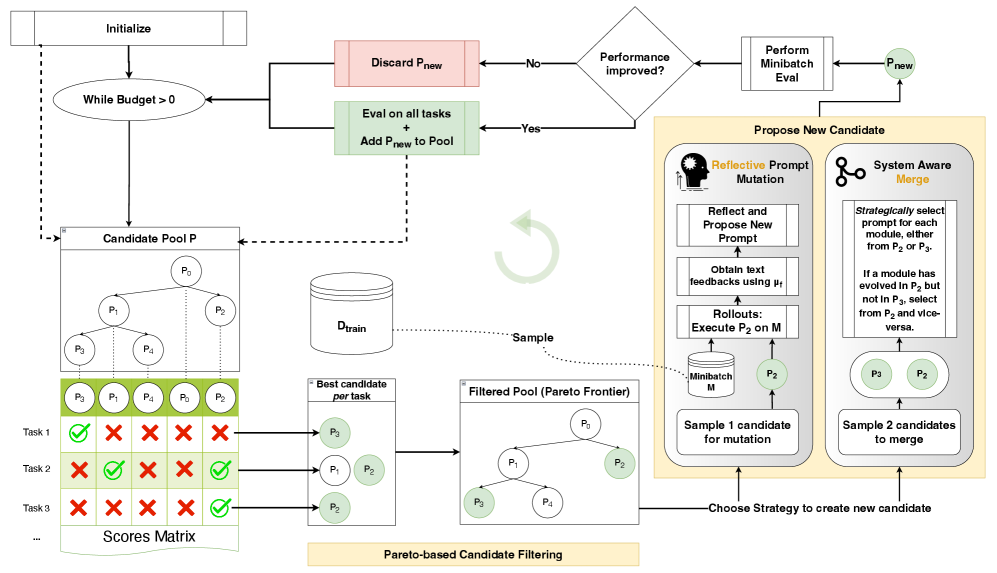
技术框架:GEPA (Genetic-Pareto) 的整体框架包含以下几个主要阶段: 1. 轨迹采样:从AI系统中采样系统级轨迹,包括推理过程、工具调用和输出等。 2. 自然语言反思:利用LLM对轨迹进行反思,诊断问题并提出提示更新的建议。 3. 提示更新:根据反思结果,对提示进行更新和测试。 4. 帕累托前沿组合:从多次尝试中选择互补的经验,并将其组合起来,形成更有效的提示。
关键创新:GEPA的关键创新在于将自然语言反思融入到提示优化过程中。与传统的强化学习方法不同,GEPA不依赖于稀疏的标量奖励,而是利用语言的丰富信息来指导学习。此外,GEPA还采用了帕累托前沿组合策略,能够有效地结合不同尝试的优点。
关键设计:GEPA的关键设计包括: 1. 提示工程:设计合适的提示,引导LLM进行有效的反思和问题诊断。 2. 轨迹表示:选择合适的轨迹表示方法,以便LLM能够有效地分析和学习。 3. 帕累托前沿选择:设计合适的帕累托前沿选择策略,以选择互补的经验。
🖼️ 关键图片
📊 实验亮点
GEPA在四个任务上的平均性能比GRPO高10%,最高可达20%,同时使用的rollout最多减少35倍。GEPA还在两个LLM上优于领先的提示优化器MIPROv2超过10%。此外,GEPA还展示了作为代码优化推理时搜索策略的潜力,表明其具有广泛的应用前景。
🎯 应用场景
GEPA具有广泛的应用前景,可以应用于各种需要利用LLM解决问题的场景,例如智能客服、代码生成、文本摘要等。通过GEPA,可以更高效地调整LLM以适应特定任务,提高LLM的性能和效率。未来,GEPA还可以与其他技术(如知识图谱、迁移学习)相结合,进一步提升LLM的应用能力。
📄 摘要(原文)
Large language models (LLMs) are increasingly adapted to downstream tasks via reinforcement learning (RL) methods like Group Relative Policy Optimization (GRPO), which often require thousands of rollouts to learn new tasks. We argue that the interpretable nature of language can often provide a much richer learning medium for LLMs, compared with policy gradients derived from sparse, scalar rewards. To test this, we introduce GEPA (Genetic-Pareto), a prompt optimizer that thoroughly incorporates natural language reflection to learn high-level rules from trial and error. Given any AI system containing one or more LLM prompts, GEPA samples system-level trajectories (e.g., reasoning, tool calls, and tool outputs) and reflects on them in natural language to diagnose problems, propose and test prompt updates, and combine complementary lessons from the Pareto frontier of its own attempts. As a result of GEPA's design, it can often turn even just a few rollouts into a large quality gain. Across four tasks, GEPA outperforms GRPO by 10% on average and by up to 20%, while using up to 35x fewer rollouts. GEPA also outperforms the leading prompt optimizer, MIPROv2, by over 10% across two LLMs, and demonstrates promising results as an inference-time search strategy for code optimization.