TokenSmith: Streamlining Data Editing, Search, and Inspection for Large-Scale Language Model Training and Interpretability
作者: Mohammad Aflah Khan, Ameya Godbole, Johnny Tian-Zheng Wei, Ryan Wang, James Flemings, Krishna P. Gummadi, Willie Neiswanger, Robin Jia
分类: cs.CL
发布日期: 2025-07-25 (更新: 2025-09-30)
💡 一句话要点
TokenSmith:简化大规模语言模型训练数据的编辑、搜索和检查流程
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大规模语言模型 预训练数据 数据编辑 数据搜索 数据检查 开源工具 数据集管理
📋 核心要点
- 现有预训练数据处理流程复杂且分散,研究人员难以有效理解数据与模型行为间的关系。
- TokenSmith提供了一个交互式的开源库,支持数据集的编辑、检查、分析和结构化修改。
- TokenSmith易于集成到现有预训练流程中,降低了生产级数据集工具的使用门槛。
📝 摘要(中文)
理解预训练期间训练数据与模型行为之间的关系至关重要,但现有的工作流程繁琐、分散,且研究人员通常难以访问。本文提出了TokenSmith,一个开源库,用于交互式编辑、检查和分析Megatron风格预训练框架(如GPT-NeoX、Megatron和NVIDIA NeMo)中使用的数据集。TokenSmith支持广泛的操作,包括搜索、查看、摄取、导出、检查和采样数据,所有这些都可以通过简单的用户界面和模块化后端访问。它还支持对预训练数据进行结构化编辑,而无需更改训练代码,从而简化了数据集调试、验证和实验。TokenSmith被设计为现有大型语言模型预训练工作流程的即插即用补充,从而普及了对生产级数据集工具的访问。TokenSmith托管在GitHub上,附带文档、教程和演示视频(可在YouTube上观看)。
🔬 方法详解
问题定义:在大规模语言模型预训练过程中,理解训练数据与模型行为之间的关系至关重要。然而,现有的数据处理流程通常是分散的、复杂的,并且缺乏易于使用的工具,使得研究人员难以有效地编辑、搜索、检查和分析训练数据。这阻碍了对数据集的调试、验证和实验。
核心思路:TokenSmith的核心思路是提供一个统一的、交互式的平台,用于管理和操作大规模语言模型的训练数据。它通过提供用户友好的界面和模块化的后端,简化了数据集的搜索、查看、编辑、检查和采样等操作。TokenSmith旨在成为现有预训练工作流程的无缝补充,无需修改现有的训练代码。
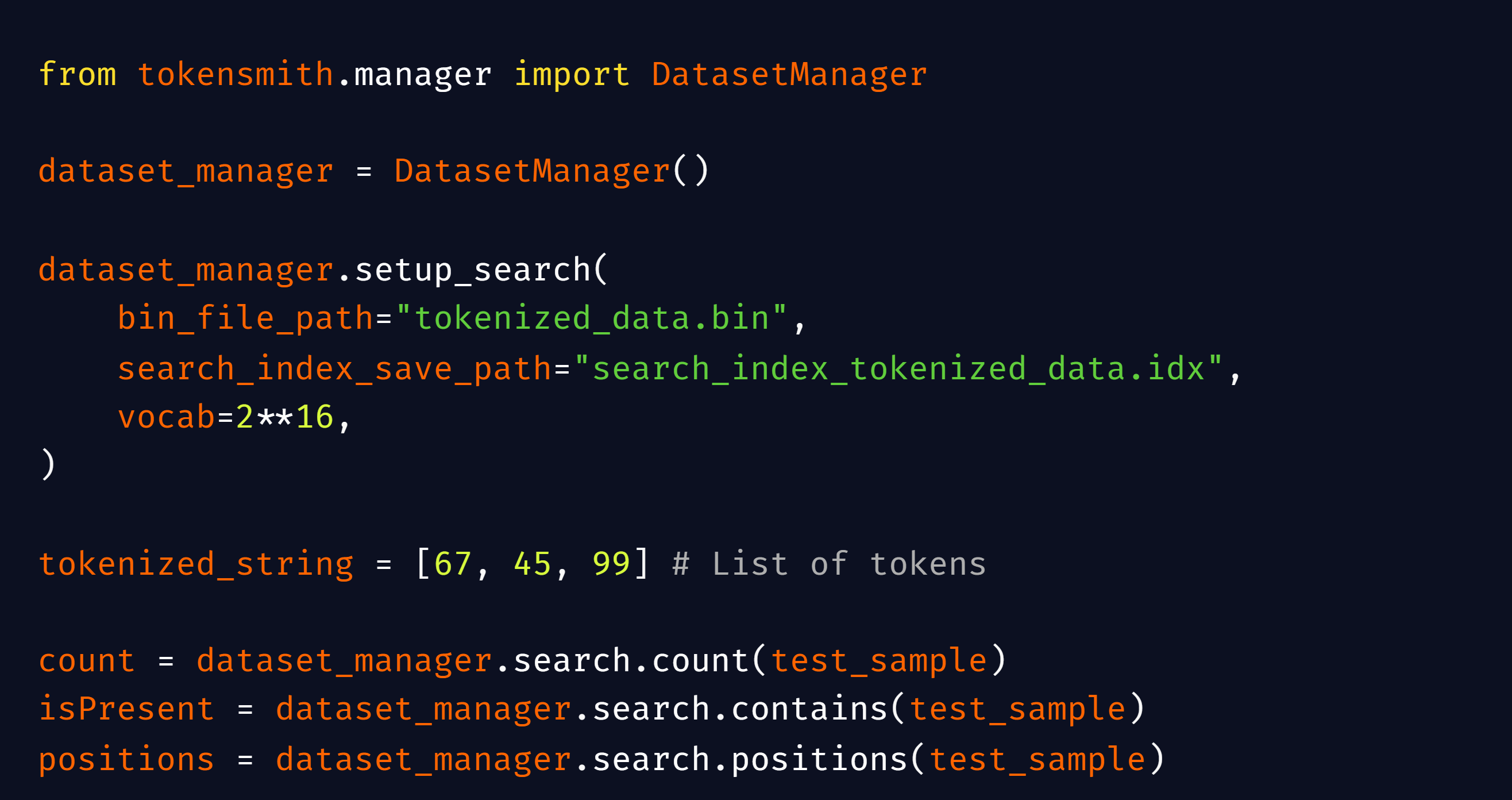
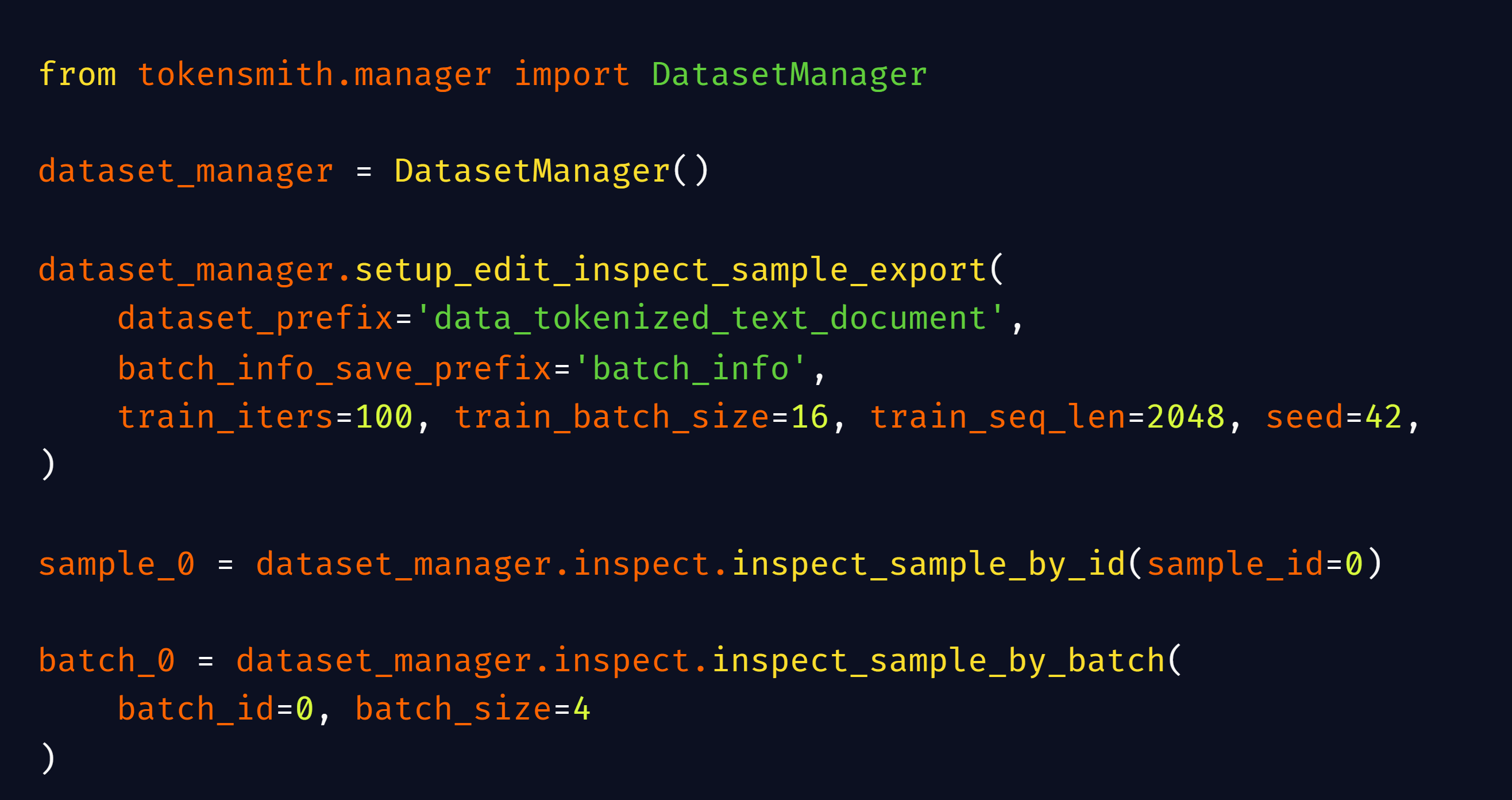
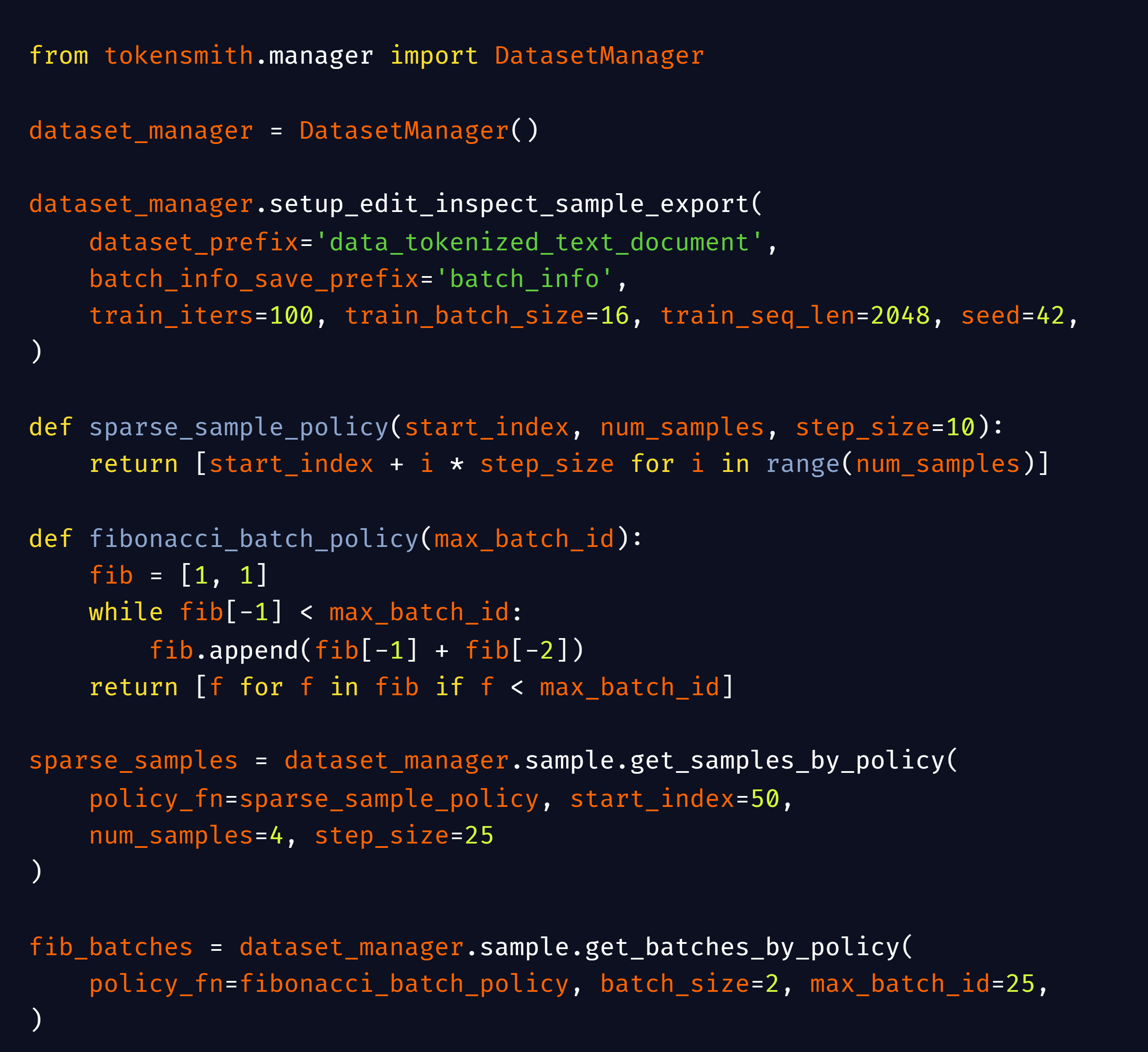
技术框架:TokenSmith的技术框架包括一个用户界面(UI)和一个模块化的后端。UI提供了交互式的数据操作界面,后端则负责处理数据的存储、检索和编辑。该框架支持多种数据格式,并可以轻松地集成到现有的Megatron风格的预训练框架中,如GPT-NeoX、Megatron和NVIDIA NeMo。主要模块包括数据摄取模块、搜索模块、编辑模块、检查模块和导出模块。
关键创新:TokenSmith的关键创新在于它提供了一个统一的、易于使用的平台,用于管理和操作大规模语言模型的训练数据。与现有的分散的工具和流程相比,TokenSmith简化了数据集的调试、验证和实验,并降低了生产级数据集工具的使用门槛。它还支持对预训练数据进行结构化编辑,而无需更改训练代码。
关键设计:TokenSmith的关键设计包括模块化的后端架构,允许轻松地添加新的数据处理功能。用户界面设计注重易用性和交互性,使得研究人员可以快速地搜索、查看、编辑和检查数据。此外,TokenSmith还提供了丰富的API,方便用户进行自定义的数据处理和分析。
🖼️ 关键图片
📊 实验亮点
TokenSmith作为一个开源库,提供了一套完整的数据集管理工具,简化了大规模语言模型预训练流程中的数据处理环节。通过提供交互式的数据编辑、搜索和检查功能,TokenSmith降低了研究人员使用生产级数据集工具的门槛,并促进了对训练数据与模型行为之间关系的理解。
🎯 应用场景
TokenSmith可应用于大规模语言模型的预训练数据管理、数据集调试与验证、数据增强实验、以及模型行为分析等领域。它能够帮助研究人员更好地理解训练数据对模型性能的影响,从而改进模型的训练过程,提升模型性能,并促进语言模型的可解释性研究。
📄 摘要(原文)
Understanding the relationship between training data and model behavior during pretraining is crucial, but existing workflows make this process cumbersome, fragmented, and often inaccessible to researchers. We present TokenSmith, an open-source library for interactive editing, inspection, and analysis of datasets used in Megatron-style pretraining frameworks such as GPT-NeoX, Megatron, and NVIDIA NeMo. TokenSmith supports a wide range of operations including searching, viewing, ingesting, exporting, inspecting, and sampling data, all accessible through a simple user interface and a modular backend. It also enables structured editing of pretraining data without requiring changes to training code, simplifying dataset debugging, validation, and experimentation. TokenSmith is designed as a plug-and-play addition to existing large language model pretraining workflows, thereby democratizing access to production-grade dataset tooling. TokenSmith is hosted on GitHub, with accompanying documentation, tutorials, and a demonstration video (available on YouTube).