SpeechIQ: Speech-Agentic Intelligence Quotient Across Cognitive Levels in Voice Understanding by Large Language Models
作者: Zhen Wan, Chao-Han Huck Yang, Yahan Yu, Jinchuan Tian, Sheng Li, Ke Hu, Zhehuai Chen, Shinji Watanabe, Fei Cheng, Chenhui Chu, Sadao Kurohashi
分类: cs.CL, cs.AI, cs.SC, cs.SD, eess.AS
发布日期: 2025-07-25 (更新: 2025-12-01)
备注: ACL 2025 main. Our Speech-IQ leaderboard is hosted at huggingface.co/spaces/nvidia/Speech-IQ-leaderboard. Speech-IQ Calculator: https://github.com/YukinoWan/SpeechIQ
DOI: 10.18653/v1/2025.acl-long.1466
💡 一句话要点
提出SpeechIQ评估框架,从认知层面评估语音大语言模型的语音理解能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语音理解 大语言模型 认知评估 布鲁姆分类法 多模态学习
📋 核心要点
- 现有语音理解评估指标(如WER)不足以全面评估LLM在认知层面的语音理解能力。
- 提出SpeechIQ框架,从记忆、理解和应用三个认知层面评估LLM的语音理解能力。
- 实验表明,SpeechIQ能有效量化语音理解能力,并能发现标注错误和检测LLM幻觉。
📝 摘要(中文)
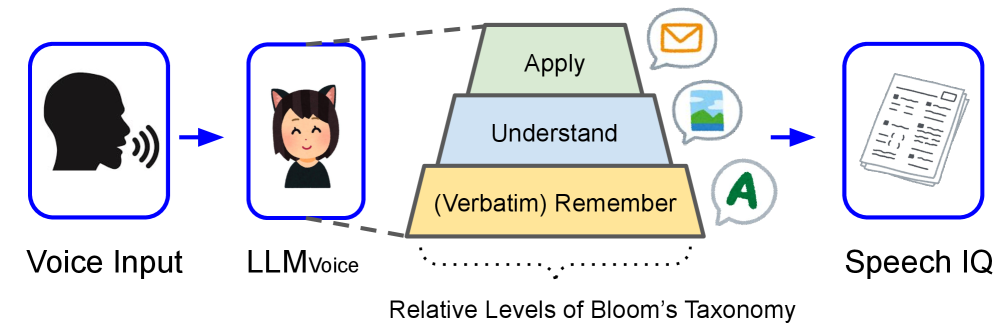
本文提出了一种基于语音的智商(SIQ)评估体系,旨在评估语音大语言模型(LLM Voice)的语音理解能力。SIQ受到布鲁姆分类法的启发,从三个认知层面评估LLM Voice:(1) 记忆(即,用于评估逐字准确率的词错误率WER);(2) 理解(即,LLM解释的相似性);(3) 应用(即,用于模拟下游任务的问答准确率)。实验表明,SIQ不仅可以量化语音理解能力,还可以统一比较级联方法(例如,ASR+LLM)和端到端模型,识别现有基准测试中的标注错误,并检测LLM Voice中的幻觉。该框架是首个将认知原则与语音基准联系起来的智能检查,同时揭示了多模态训练中被忽视的挑战。代码和数据将开源,以鼓励未来的研究。
🔬 方法详解
问题定义:现有语音理解评估方法主要依赖于词错误率(WER)等指标,这些指标侧重于语音转录的准确性,无法全面评估模型在更高认知层面的理解能力,例如理解语音的含义、进行推理和应用知识。此外,现有基准测试可能存在标注错误,且难以检测LLM在语音理解中产生的幻觉问题。
核心思路:本文的核心思路是借鉴布鲁姆分类法,将语音理解能力分解为记忆、理解和应用三个认知层面,并设计相应的评估指标。通过多层面的评估,更全面地考察LLM对语音信息的处理能力。同时,利用SIQ框架可以发现现有数据集的标注错误和LLM的幻觉问题。
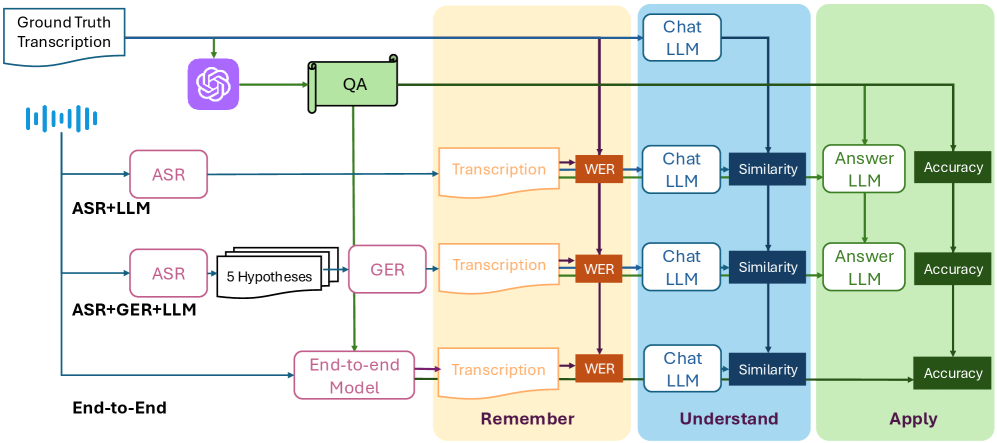
技术框架:SpeechIQ框架包含三个主要模块,分别对应布鲁姆分类法的三个认知层面: 1. 记忆层面:使用词错误率(WER)评估模型语音转录的准确性。 2. 理解层面:通过计算LLM对语音内容解释的相似度来评估其理解能力。 3. 应用层面:使用问答(QA)准确率来评估模型在下游任务中的应用能力。
关键创新:该论文的关键创新在于: 1. 提出了一个基于认知科学的语音理解评估框架,超越了传统的基于转录准确率的评估方法。 2. 提供了一种统一的比较框架,可以比较级联方法(ASR+LLM)和端到端模型。 3. 能够识别现有基准测试中的标注错误,并检测LLM在语音理解中产生的幻觉。
关键设计:在理解层面,论文可能采用了语义相似度计算方法,例如使用预训练语言模型提取语音内容和LLM解释的语义向量,然后计算向量之间的余弦相似度。在应用层面,需要构建一个包含问题和答案的语音数据集,并使用QA准确率作为评估指标。具体的参数设置、损失函数和网络结构等细节可能取决于所使用的LLM和ASR模型。
🖼️ 关键图片
📊 实验亮点
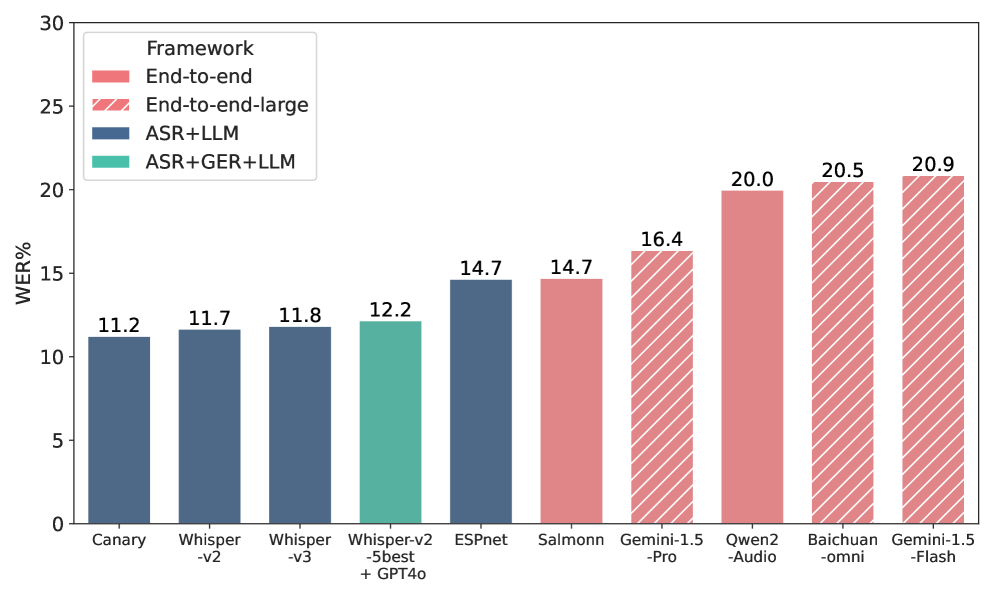
实验结果表明,SpeechIQ框架能够有效区分不同模型的语音理解能力,并能识别现有基准测试中的标注错误和LLM的幻觉。通过SIQ评估,可以发现级联方法(ASR+LLM)和端到端模型在不同认知层面上的优劣势,为模型选择和优化提供指导。
🎯 应用场景
SpeechIQ框架可应用于语音助手、智能客服、语音搜索等领域,帮助开发者更全面地评估和优化语音大语言模型的性能。该框架能够促进多模态学习的研究,并推动语音理解技术的进步,最终提升人机交互的自然性和智能化水平。
📄 摘要(原文)
We introduce Speech-based Intelligence Quotient (SIQ) as a new form of human cognition-inspired evaluation pipeline for voice understanding large language models, LLM Voice, designed to assess their voice understanding ability. Moving beyond popular voice understanding metrics such as word error rate (WER), SIQ examines LLM Voice across three cognitive levels motivated by Bloom's Taxonomy: (1) Remembering (i.e., WER for verbatim accuracy); (2) Understanding (i.e., similarity of LLM's interpretations); and (3) Application (i.e., QA accuracy for simulating downstream tasks). We demonstrate that SIQ not only quantifies voice understanding abilities but also provides unified comparisons between cascaded methods (e.g., ASR LLM) and end-to-end models, identifies annotation errors in existing benchmarks, and detects hallucinations in LLM Voice. Our framework represents a first-of-its-kind intelligence examination that bridges cognitive principles with voice-oriented benchmarks, while exposing overlooked challenges in multi-modal training. Our code and data will be open source to encourage future studies.