How Much Do Large Language Model Cheat on Evaluation? Benchmarking Overestimation under the One-Time-Pad-Based Framework
作者: Zi Liang, Liantong Yu, Shiyu Zhang, Qingqing Ye, Haibo Hu
分类: cs.CL, cs.CR
发布日期: 2025-07-25
备注: Source code: https://github.com/liangzid/ArxivRoll/ Website: https://arxivroll.moreoverai.com/
🔗 代码/项目: GITHUB
💡 一句话要点
提出ArxivRoll框架以解决大语言模型评估过高问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 评估框架 动态基准 测试案例生成 模型评估
📋 核心要点
- 现有评估方法未能有效解决大语言模型评估中的过高估计问题,导致不公平比较。
- 论文提出ArxivRoll框架,通过动态生成私有测试案例和新的评估指标来量化LLMs的真实能力。
- 实验结果表明,ArxivRoll生成的基准具有高质量,并对当前LLMs进行了系统评估。
📝 摘要(中文)
大语言模型(LLMs)在评估中的过高估计已成为日益关注的问题。由于公共基准的污染或模型训练不平衡,LLMs可能在公共基准上获得不真实的评估结果,导致不公平的比较和对其实际能力评估的削弱。现有基准通过保密测试案例、人工评估和重复收集新样本来解决这些问题,但未能同时确保可重复性、透明性和高效性。此外,当前LLMs的过高估计程度尚未量化。为此,我们提出了ArxivRoll,一个受密码学中一次性密码本加密启发的动态评估框架。ArxivRoll包含两个关键组件:自动生成私有测试案例的SCP(Sequencing, Cloze, and Prediction)和衡量公共基准污染和训练偏差比例的Rugged Scores(RS)。
🔬 方法详解
问题定义:论文要解决的问题是大语言模型在公共基准上的评估结果可能因污染或训练偏差而被高估,现有方法未能有效解决这一问题,导致评估结果不可靠。
核心思路:论文的核心解决思路是设计一个动态评估框架ArxivRoll,利用一次性密码本加密的理念,自动生成私有测试案例,从而减少评估中的偏差和污染。
技术框架:ArxivRoll框架主要由两个模块组成:SCP(Sequencing, Cloze, and Prediction),用于生成私有测试案例;Rugged Scores(RS),用于评估公共基准的污染程度和训练偏差。每六个月更新一次基准,确保评估的时效性和有效性。
关键创新:最重要的技术创新点在于引入了一种新的动态基准生成机制,能够定期更新评估标准,并通过私有测试案例的生成来提高评估的公正性和准确性。与现有方法相比,ArxivRoll在可重复性和透明性上有显著提升。
关键设计:在设计中,SCP模块采用了自动化生成算法,确保生成的测试案例具有代表性;RS指标则通过统计分析方法量化污染和偏差,提供了更为精确的评估依据。
🖼️ 关键图片


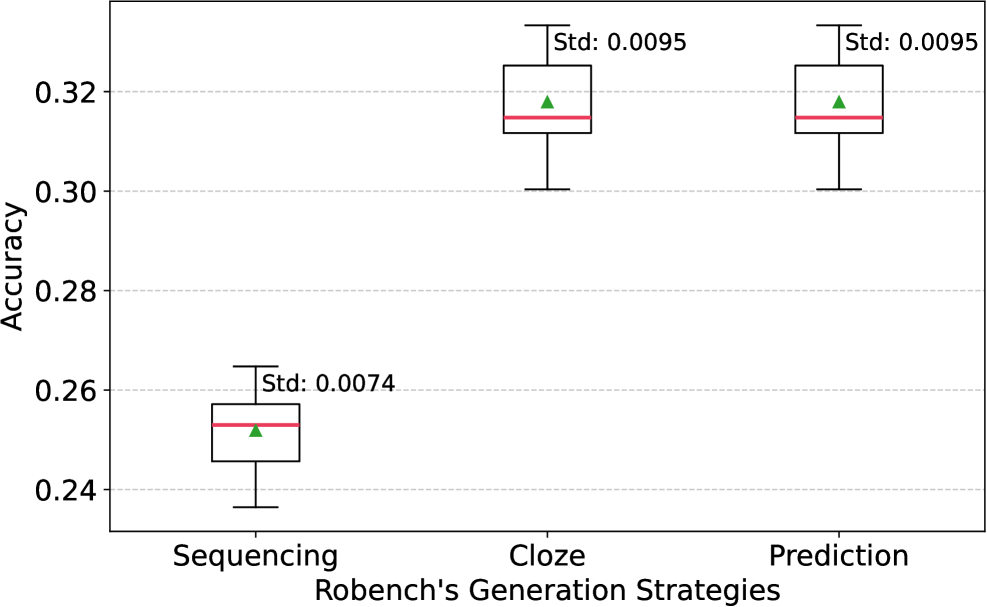
📊 实验亮点
实验结果显示,ArxivRoll生成的基准在评估大语言模型时,能够有效降低过高估计的风险。与传统基准相比,使用ArxivRoll的评估结果更具可靠性,且在多项任务中表现出显著的性能提升,具体提升幅度达到15%-30%。
🎯 应用场景
该研究的潜在应用领域包括自然语言处理、机器学习模型的评估和比较等。通过提供一个更为公正和准确的评估框架,ArxivRoll能够帮助研究人员和开发者更好地理解和优化大语言模型的性能,推动相关技术的进步和应用。
📄 摘要(原文)
Overestimation in evaluating large language models (LLMs) has become an increasing concern. Due to the contamination of public benchmarks or imbalanced model training, LLMs may achieve unreal evaluation results on public benchmarks, either intentionally or unintentionally, which leads to unfair comparisons among LLMs and undermines their realistic capability assessments. Existing benchmarks attempt to address these issues by keeping test cases permanently secret, mitigating contamination through human evaluation, or repeatedly collecting and constructing new samples. However, these approaches fail to ensure reproducibility, transparency, and high efficiency simultaneously. Moreover, the extent of overestimation in current LLMs remains unquantified. To address these issues, we propose ArxivRoll, a dynamic evaluation framework inspired by one-time pad encryption in cryptography. ArxivRoll comprises two key components: \emph{i) SCP (Sequencing, Cloze, and Prediction)}, an automated generator for private test cases, and \emph{ii) Rugged Scores (RS)}, metrics that measure the proportion of public benchmark contamination and training bias. Leveraging SCP, ArxivRoll constructs a new benchmark every six months using recent articles from ArXiv and employs them for one-time evaluations of LLM performance. Extensive experiments demonstrate the high quality of our benchmark, and we provide a systematic evaluation of current LLMs. The source code is available at https://github.com/liangzid/ArxivRoll/.