Debating Truth: Debate-driven Claim Verification with Multiple Large Language Model Agents
作者: Haorui He, Yupeng Li, Dacheng Wen, Yang Chen, Reynold Cheng, Donglong Chen, Francis C. M. Lau
分类: cs.CL
发布日期: 2025-07-25 (更新: 2025-12-01)
💡 一句话要点
提出DebateCV框架,利用多智能体辩论提升复杂声明验证的准确性和可信度。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 声明验证 多智能体系统 大型语言模型 辩论式学习 事实核查
📋 核心要点
- 现有单智能体声明验证方法难以处理需要细致分析多方面证据的复杂声明。
- DebateCV框架通过多智能体辩论,模拟人工事实核查,提升复杂声明验证的准确性。
- Debate-SFT后训练框架利用合成数据,增强智能体裁决辩论的能力,提升验证效果。
📝 摘要(中文)
声明验证对于数字素养至关重要,但目前最先进的单智能体方法在处理需要对多方面在线证据进行细致分析的复杂声明时常常表现不佳。受到现实世界人工事实核查实践的启发,我们提出了DebateCV,这是第一个由多个LLM智能体驱动的辩论式声明验证框架。在DebateCV中,两个辩论者就相反的立场进行多轮辩论,以发现单智能体评估中的细微错误。然后,需要一个具有决定性的主持人来权衡相互冲突的论点的证据强度,以提供准确的结论。然而,零样本智能体难以裁决用于验证复杂声明的多轮辩论,常常默认为中立判断,并且不存在用于训练智能体担任此角色的数据集。为了弥合这一差距,我们提出了Debate-SFT,这是一个利用合成数据来增强智能体有效裁决声明验证辩论能力的后训练框架。结果表明,我们的方法在准确性(在各种证据条件下)和理由质量方面都超过了最先进的非辩论方法,这增强了社会抵御虚假信息的能力,并有助于建立一个更值得信赖的在线信息生态系统。
🔬 方法详解
问题定义:论文旨在解决复杂声明验证问题,现有单智能体方法在处理需要综合分析多方证据的复杂声明时,容易出现判断偏差,难以保证准确性和可信度。现有方法缺乏有效的机制来发现和纠正潜在的错误,尤其是在证据存在争议或模棱两可的情况下。
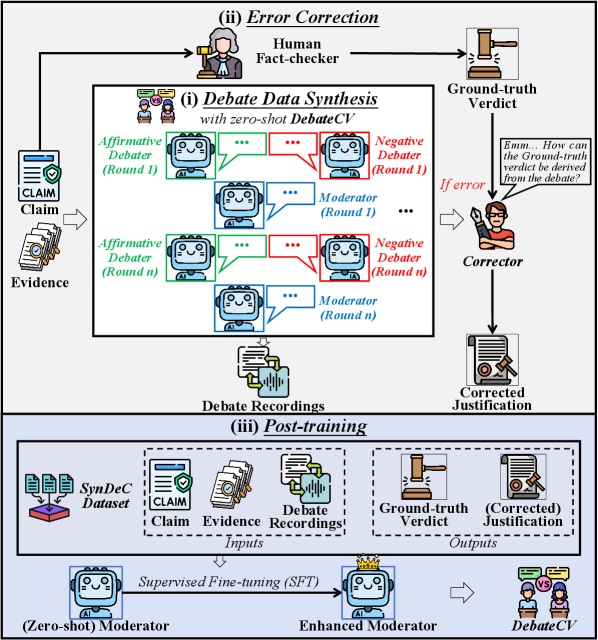
核心思路:论文的核心思路是引入多智能体辩论机制,模拟人类事实核查过程中的辩论环节。通过让两个智能体就同一声明进行多轮辩论,互相挑战对方的观点和证据,从而暴露单智能体方法可能忽略的细微错误和潜在偏差。最终由一个主持人智能体综合评估辩论双方的论点,给出最终的验证结果。
技术框架:DebateCV框架包含三个主要模块:两个辩论者(Debaters)和一个主持人(Moderator)。辩论者分别代表支持和反对两种立场,围绕给定的声明进行多轮辩论,每一轮辩论者都会提出论点和证据来支持自己的立场,并反驳对方的观点。主持人负责监听辩论过程,并在辩论结束后综合评估双方的论点和证据,给出最终的验证结果。为了提升主持人的判断能力,论文还提出了Debate-SFT后训练框架,利用合成数据对主持人进行微调。
关键创新:论文的关键创新在于将多智能体辩论引入声明验证任务,通过模拟人类辩论过程来提升验证的准确性和可信度。此外,Debate-SFT框架通过合成数据增强了智能体裁决辩论的能力,解决了现有方法中零样本智能体难以有效裁决辩论的问题。与现有方法相比,DebateCV框架能够更有效地发现和纠正单智能体方法可能忽略的细微错误和潜在偏差。
关键设计:Debate-SFT框架的关键设计在于合成数据的生成方式。论文采用了一种基于规则的方法来生成包含不同论点和证据的辩论记录,并使用这些记录来训练主持人智能体。具体来说,论文定义了一系列规则来模拟辩论者提出论点、反驳论点和提供证据的过程。这些规则考虑了不同类型的声明和证据,以及辩论者可能采取的不同策略。此外,论文还设计了一种损失函数来鼓励主持人智能体做出准确的判断,并提供合理的解释。
🖼️ 关键图片
📊 实验亮点
实验结果表明,DebateCV框架在准确性和理由质量方面均优于最先进的非辩论方法。在各种证据条件下,DebateCV框架的准确率显著提升,同时能够提供更具说服力的理由。Debate-SFT后训练框架进一步提升了主持人的判断能力,使得DebateCV框架能够更有效地识别和验证复杂声明。
🎯 应用场景
该研究成果可应用于新闻媒体、社交平台等领域,用于自动识别和验证虚假信息,提高信息的可信度。同时,该方法也可用于辅助人工事实核查,提高工作效率和准确性。未来,该技术有望应用于更广泛的领域,例如医疗诊断、法律咨询等,为人们提供更可靠的信息服务。
📄 摘要(原文)
Claim verification is essential for digital literacy, yet state-of-the-art single-agent methods often struggle with complex claims that require nuanced analysis of multifaceted online evidence. Inspired by real-world human fact-checking practices, we propose \textbf{DebateCV}, the first debate-driven claim verification framework powered by multiple LLM agents. In DebateCV, two \textit{Debaters} argue opposing stances over multiple rounds to surface subtle errors in single-agent assessments. A decisive \textit{Moderator} is then required to weigh the evidential strength of conflicting arguments to deliver an accurate verdict. Yet zero-shot agents struggle to adjudicate multi-round debates for verifying complex claims, often defaulting to neutral judgements, and no datasets exist for training agents for this role. To bridge this gap, we propose \textbf{Debate-SFT}, a post-training framework that leverages synthetic data to enhance agents' ability to effectively adjudicate debates for claim verification. Results show that our methods surpass state-of-the-art non-debate approaches in both accuracy (across various evidence conditions) and justification quality, which strengthens societal resilience against misinformation and contributes to a more trustworthy online information ecosystem.