MLLM-based Speech Recognition: When and How is Multimodality Beneficial?
作者: Yiwen Guan, Viet Anh Trinh, Vivek Voleti, Jacob Whitehill
分类: cs.SD, cs.CL, cs.MM, eess.AS
发布日期: 2025-07-25
💡 一句话要点
研究多模态信息融合在噪声环境下提升语音识别性能的策略与模型架构。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 语音识别 噪声环境 视觉辅助 信息融合
📋 核心要点
- 现有语音识别模型在噪声环境下性能下降明显,缺乏对其他模态信息的有效利用。
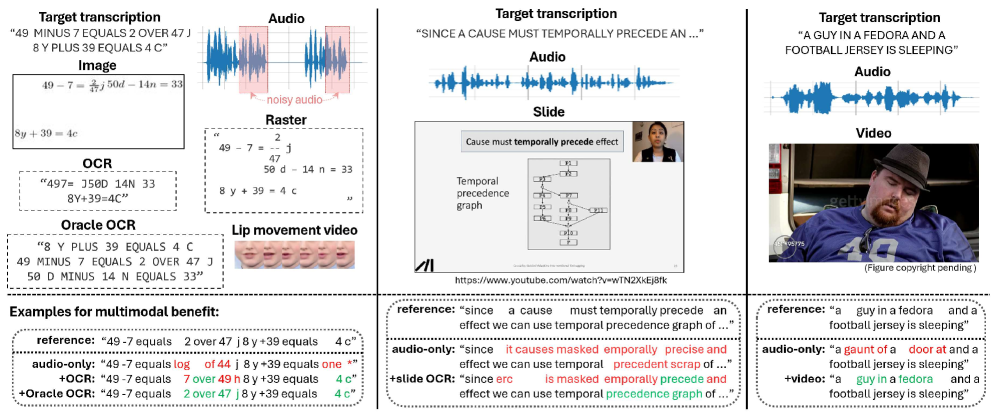
- 探索多模态信息融合,利用视觉信息(唇动、图像上下文)辅助语音识别,提升鲁棒性。
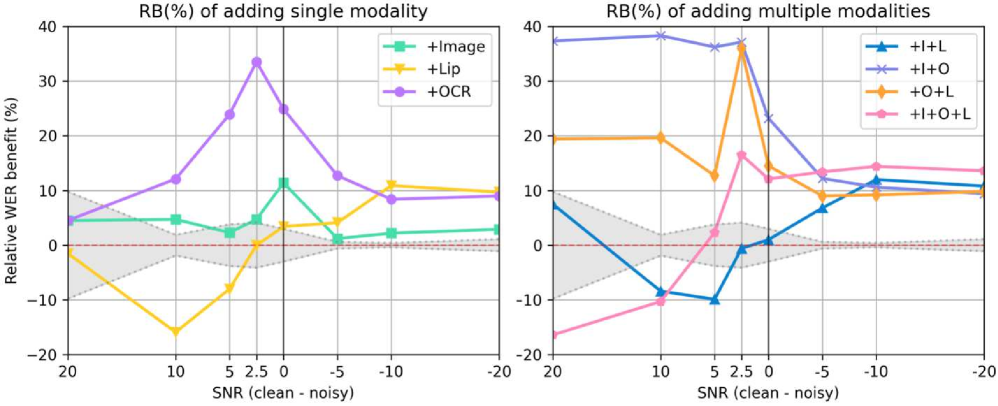
- 实验表明,多模态融合通常能提升语音识别准确率,且不同模态在不同噪声水平下作用不同。
📝 摘要(中文)
本文研究了多模态大语言模型(MLLM)在统一建模语音、文本、图像和其他模态方面的潜力,并探讨了在噪声环境下,多种输入模态如何以及何时能够提高自动语音识别(ASR)的准确性。通过在合成和真实世界数据上的实验,我们发现:(1)利用更多模态通常可以提高ASR准确性,因为每个模态都提供互补信息,但提升效果取决于听觉噪声的程度。(2)同步模态(如唇动)在高噪声水平下更有用,而非同步模态(如图像上下文)在适度噪声水平下最有帮助。(3)更高质量的视觉表征始终提高ASR准确性,突出了开发更强大的视觉编码器的重要性。(4)Mamba模型在多模态优势方面表现出与Transformer相似的趋势。(5)模态的输入顺序以及它们在损失函数中的权重会显著影响准确性。这些发现提供了实践见解,并有助于加深我们对具有挑战性条件下的多模态语音识别的理解。
🔬 方法详解
问题定义:论文旨在解决噪声环境下语音识别准确率低的问题。现有方法主要依赖于纯语音信息,在噪声干扰严重时性能急剧下降。缺乏对其他模态信息的有效利用,例如视觉信息(唇动、场景图像)等,这些信息可以提供额外的上下文线索,帮助模型更好地理解语音内容。
核心思路:论文的核心思路是利用多模态信息融合来提升语音识别的鲁棒性。通过将语音、视觉等多种模态的信息进行整合,模型可以利用不同模态之间的互补性,从而在噪声环境下更准确地识别语音。论文认为,不同模态在不同噪声水平下具有不同的作用,因此需要根据噪声水平选择合适的模态进行融合。
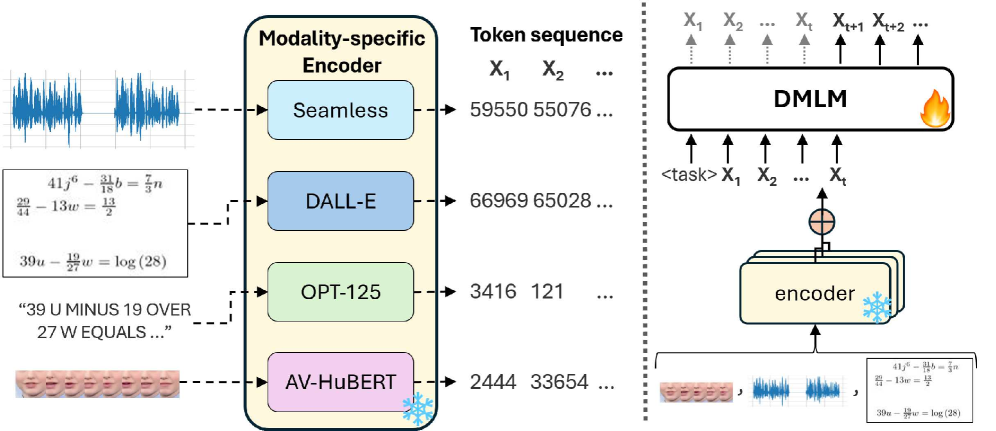
技术框架:论文采用多模态大语言模型(MLLM)作为基础框架,将语音、视觉等多种模态的信息输入到模型中。模型通过学习不同模态之间的关联性,从而实现多模态信息的融合。具体来说,模型可能包含以下模块:语音编码器、视觉编码器、多模态融合模块和解码器。语音编码器负责提取语音特征,视觉编码器负责提取视觉特征,多模态融合模块负责将不同模态的特征进行融合,解码器负责将融合后的特征解码为文本。
关键创新:论文的关键创新在于对多模态信息融合策略的深入研究。论文不仅验证了多模态融合能够提升语音识别性能,而且还发现了不同模态在不同噪声水平下的作用差异。此外,论文还探讨了模态输入顺序和损失函数权重对模型性能的影响,为多模态语音识别的研究提供了新的思路。
关键设计:论文的关键设计可能包括以下几个方面:1) 视觉编码器的选择,高质量的视觉表征对于提升语音识别准确率至关重要。2) 多模态融合模块的设计,如何有效地将不同模态的特征进行融合是一个关键问题。3) 损失函数的设计,如何平衡不同模态的损失权重,从而实现最佳的融合效果。4) 输入模态的顺序,不同的输入顺序可能会影响模型的学习效果。
🖼️ 关键图片
📊 实验亮点
实验结果表明,多模态融合通常能够提高ASR准确率,尤其是在噪声环境下。同步模态(如唇动)在高噪声水平下效果更佳,而非同步模态(如图像上下文)在适度噪声水平下更有帮助。更高质量的视觉表征能够持续提升ASR准确率。Mamba模型在多模态融合方面表现出与Transformer相似的趋势。
🎯 应用场景
该研究成果可应用于各种噪声环境下的语音交互系统,例如车载语音助手、智能家居设备、工业控制系统等。通过融合视觉信息,可以显著提升这些系统在嘈杂环境下的语音识别准确率,从而改善用户体验,提高系统的实用性。未来,该技术还可应用于助听设备,帮助听力受损人士更好地理解语音。
📄 摘要(原文)
Recent advances in multi-modal large language models (MLLMs) have opened new possibilities for unified modeling of speech, text, images, and other modalities. Building on our prior work, this paper examines the conditions and model architectures under which multiple input modalities can improve automatic speech recognition (ASR) accuracy in noisy environments. Through experiments on synthetic and real-world data, we find that (1) harnessing more modalities usually improves ASR accuracy, as each modality provides complementary information, but the improvement depends on the amount of auditory noise. (2) Synchronized modalities (e.g., lip movements) are more useful at high noise levels whereas unsynchronized modalities (e.g., image context) are most helpful at moderate noise levels. (3) Higher-quality visual representations consistently improve ASR accuracy, highlighting the importance of developing more powerful visual encoders. (4) Mamba exhibits similar trends regarding the benefits of multimodality as do Transformers. (5) The input order of modalities as well as their weights in the loss function can significantly impact accuracy. These findings both offer practical insights and help to deepen our understanding of multi-modal speech recognition under challenging conditions.