MMESGBench: Pioneering Multimodal Understanding and Complex Reasoning Benchmark for ESG Tasks
作者: Lei Zhang, Xin Zhou, Chaoyue He, Di Wang, Yi Wu, Hong Xu, Wei Liu, Chunyan Miao
分类: cs.MM, cs.CL
发布日期: 2025-07-25 (更新: 2025-08-15)
备注: Accepted at ACM MM 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出MMESGBench,首个面向ESG任务的多模态理解与复杂推理基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: ESG 多模态学习 文档理解 复杂推理 基准数据集 人机协作 大型语言模型
📋 核心要点
- 现有AI系统在处理结构复杂、多模态的ESG文档时,进行可靠的文档级推理存在困难,缺乏专门的评估基准。
- 论文提出MMESGBench,通过人机协作方式构建高质量的多模态ESG文档问答数据集,用于评估模型的多模态理解和复杂推理能力。
- 实验表明,多模态和检索增强模型在MMESGBench上显著优于纯文本模型,尤其在视觉和跨页推理任务上表现更佳。
📝 摘要(中文)
环境、社会和治理(ESG)报告对于评估可持续性实践、确保合规性和促进财务透明至关重要。然而,这些文档通常冗长、结构多样且是多模态的,包含密集的文本、结构化表格、复杂图形和布局相关的语义。现有的AI系统难以在此类环境中执行可靠的文档级推理,并且目前在ESG领域没有专门的基准。为了填补这一空白,我们推出了MMESGBench,这是首个旨在评估跨结构多样和多源ESG文档的多模态理解和复杂推理的基准数据集。该数据集通过人机协作的多阶段流程构建。首先,多模态LLM通过共同解释来自布局感知文档页面的丰富文本、表格和视觉信息来生成候选问答(QA)对。其次,LLM验证每个QA对的语义准确性、完整性和推理复杂性。这个自动化过程之后是专家参与的验证,领域专家验证和校准QA对,以确保质量、相关性和多样性。MMESGBench包含来自45个ESG文档的933个经过验证的QA对,涵盖七种不同的文档类型和三个主要的ESG来源类别。问题分为单页、跨页或无法回答,每个问题都附有细粒度的多模态证据。初步实验验证了多模态和检索增强模型明显优于纯文本基线,尤其是在视觉基础和跨页任务上。MMESGBench作为开源数据集在https://github.com/Zhanglei1103/MMESGBench上公开提供。
🔬 方法详解
问题定义:论文旨在解决现有AI系统在理解和推理复杂多模态ESG文档方面的不足。现有方法难以有效处理ESG报告中存在的长文本、表格、图像以及布局信息,缺乏专门的基准数据集来评估模型在此领域的性能。
核心思路:论文的核心思路是构建一个高质量、多样化的多模态ESG文档问答数据集,用于评估和提升模型在理解和推理此类文档方面的能力。通过人机协作的方式,结合大型语言模型(LLM)的生成和验证能力,以及领域专家的专业知识,确保数据集的质量和相关性。
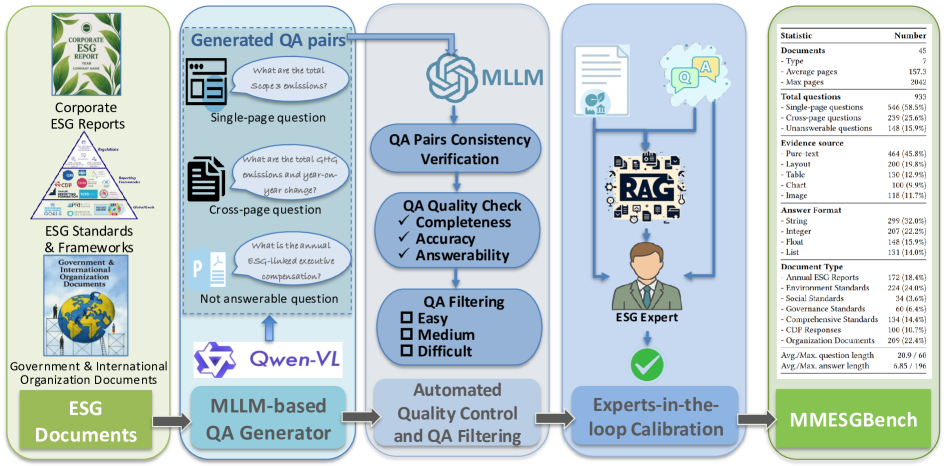
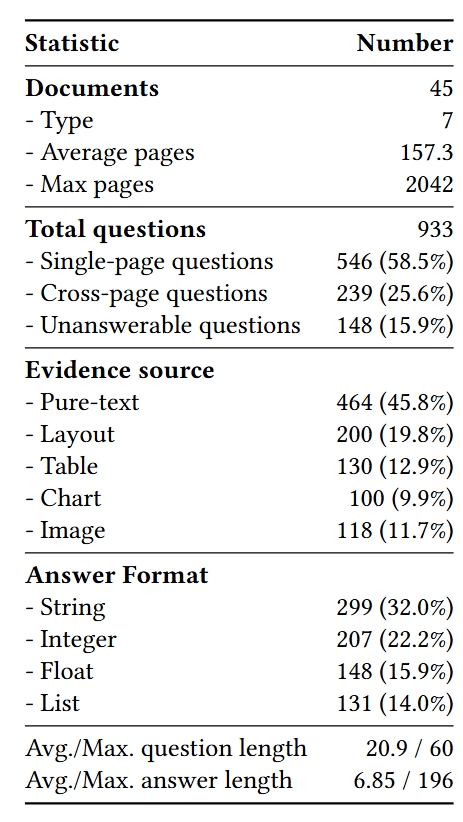
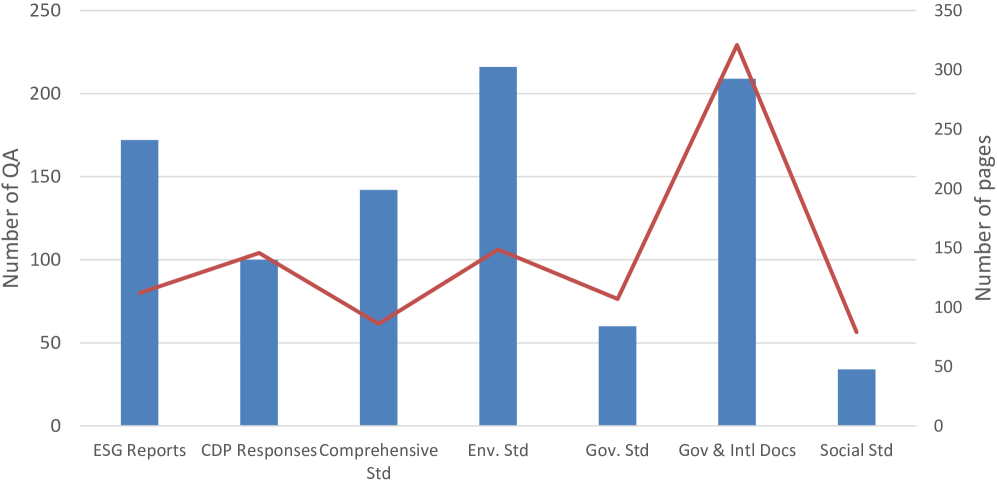
技术框架:MMESGBench的构建流程包含以下几个主要阶段:1) 多模态LLM生成候选QA对,该模型能够同时理解文档中的文本、表格和图像信息。2) LLM验证QA对的语义准确性、完整性和推理复杂性。3) 领域专家参与验证,对QA对进行校准,确保其质量、相关性和多样性。最终数据集包含933个QA对,涵盖7种文档类型和3个ESG来源类别。
关键创新:MMESGBench的关键创新在于它是首个专门针对ESG领域的多模态理解和复杂推理的基准数据集。它不仅包含了丰富的多模态信息,还通过人机协作的方式保证了数据集的质量和多样性。此外,数据集中的问题被分为单页、跨页和无法回答三种类型,并附带细粒度的多模态证据,有助于更全面地评估模型的推理能力。
关键设计:在数据生成阶段,使用了能够处理多模态信息的LLM,并针对ESG文档的特点进行了优化。在数据验证阶段,采用了多轮验证机制,包括LLM的自动验证和领域专家的手动验证,以确保数据集的准确性和可靠性。问题的设计考虑了不同的推理难度和信息来源,包括单页信息、跨页信息以及需要结合多种模态信息才能回答的问题。
🖼️ 关键图片
📊 实验亮点
实验结果表明,多模态模型和检索增强模型在MMESGBench上显著优于纯文本模型。尤其是在需要视觉信息和跨页推理的任务中,多模态模型的性能提升更为明显。这些结果验证了MMESGBench的有效性,并表明多模态信息对于理解和推理复杂ESG文档至关重要。
🎯 应用场景
MMESGBench可用于训练和评估各种多模态AI模型,提升其在ESG报告理解和推理方面的能力。这有助于提高ESG评估的效率和准确性,支持投资决策、风险管理和可持续发展战略的制定。未来,该基准可以扩展到其他领域,例如金融报告、法律文档等。
📄 摘要(原文)
Environmental, Social, and Governance (ESG) reports are essential for evaluating sustainability practices, ensuring regulatory compliance, and promoting financial transparency. However, these documents are often lengthy, structurally diverse, and multimodal, comprising dense text, structured tables, complex figures, and layout-dependent semantics. Existing AI systems often struggle to perform reliable document-level reasoning in such settings, and no dedicated benchmark currently exists in ESG domain. To fill the gap, we introduce \textbf{MMESGBench}, a first-of-its-kind benchmark dataset targeted to evaluate multimodal understanding and complex reasoning across structurally diverse and multi-source ESG documents. This dataset is constructed via a human-AI collaborative, multi-stage pipeline. First, a multimodal LLM generates candidate question-answer (QA) pairs by jointly interpreting rich textual, tabular, and visual information from layout-aware document pages. Second, an LLM verifies the semantic accuracy, completeness, and reasoning complexity of each QA pair. This automated process is followed by an expert-in-the-loop validation, where domain specialists validate and calibrate QA pairs to ensure quality, relevance, and diversity. MMESGBench comprises 933 validated QA pairs derived from 45 ESG documents, spanning across seven distinct document types and three major ESG source categories. Questions are categorized as single-page, cross-page, or unanswerable, with each accompanied by fine-grained multimodal evidence. Initial experiments validate that multimodal and retrieval-augmented models substantially outperform text-only baselines, particularly on visually grounded and cross-page tasks. MMESGBench is publicly available as an open-source dataset at https://github.com/Zhanglei1103/MMESGBench.