Uncovering Cross-Linguistic Disparities in LLMs using Sparse Autoencoders
作者: Richmond Sin Jing Xuan, Jalil Huseynov, Yang Zhang
分类: cs.CL, cs.AI
发布日期: 2025-07-25
💡 一句话要点
利用稀疏自编码器揭示LLM跨语言能力差异
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多语言LLM 稀疏自编码器 跨语言差异 激活感知微调 低资源语言 低秩适应 模型分析
📋 核心要点
- 多语言LLM在中低资源语言上的性能不足,暴露了跨语言泛化的挑战。
- 利用稀疏自编码器分析LLM内部激活,揭示不同语言间的激活差异。
- 通过激活感知微调,显著提升中低资源语言的激活水平和基准测试性能。
📝 摘要(中文)
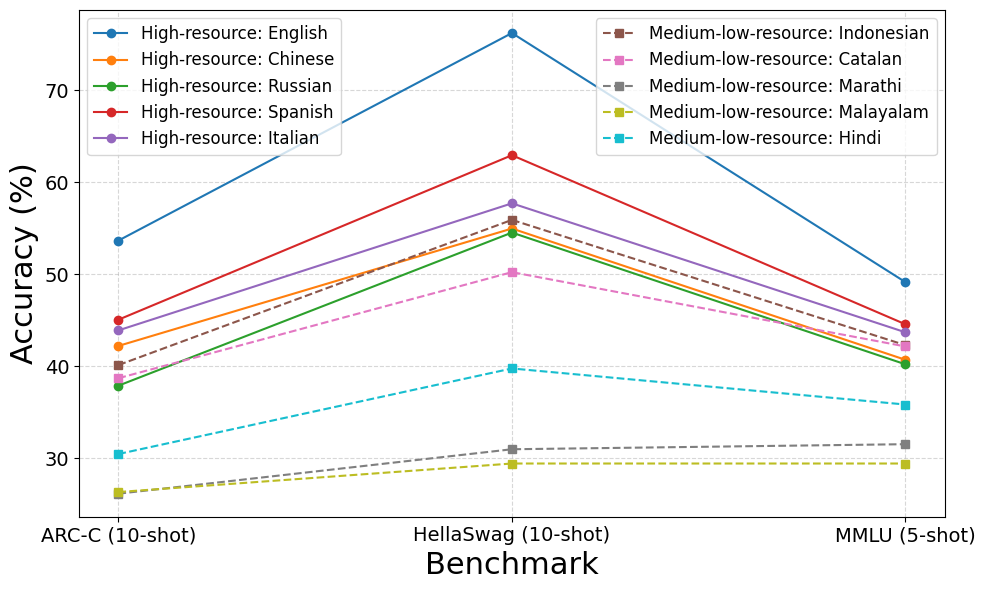
多语言大型语言模型(LLM)表现出强大的跨语言泛化能力,但中低资源语言在ARC-Challenge、MMLU和HellaSwag等常见基准测试中表现不佳。我们分析了Gemma-2-2B在所有26个残差层和10种语言(中文、俄语、西班牙语、意大利语,以及包括印尼语、加泰罗尼亚语、马拉地语、马拉雅拉姆语和印地语在内的中低资源语言,以英语为参考)中的激活模式。使用稀疏自编码器(SAE),我们揭示了激活模式中的系统性差异。中低资源语言在早期层中接收到的激活值最多降低26.27%,在更深层中持续存在19.89%的差距。为了解决这个问题,我们通过低秩适应(LoRA)应用激活感知微调,从而带来显著的激活增益,例如马拉雅拉姆语为87.69%,印地语为86.32%,同时保持英语保留率在约91%。微调后,基准测试结果显示出适度但一致的改进,突出了激活对齐是提高多语言LLM性能的关键因素。
🔬 方法详解
问题定义:论文旨在解决多语言LLM在中低资源语言上表现不佳的问题。现有的多语言LLM虽然在多种语言上进行了训练,但在资源匮乏的语言上,其性能往往显著低于高资源语言,这表明模型在不同语言之间的知识迁移和泛化能力存在不平衡。现有方法难以有效解决这种跨语言差异,导致模型在低资源语言上的应用受限。
核心思路:论文的核心思路是通过分析LLM内部的激活模式,量化不同语言之间的差异,并针对性地进行微调,以提升低资源语言的性能。通过稀疏自编码器提取LLM各层的激活特征,从而发现不同语言在模型内部表示上的差异。然后,通过激活感知的微调策略,调整模型参数,使得低资源语言的激活模式与高资源语言更加接近,从而提升其性能。
技术框架:论文的技术框架主要包括三个阶段:1) 激活数据收集:收集Gemma-2-2B模型在处理不同语言文本时的激活数据,覆盖所有26个残差层。2) 稀疏自编码器分析:使用稀疏自编码器对收集到的激活数据进行分析,提取不同语言在模型内部的激活特征,并量化它们之间的差异。3) 激活感知微调:利用低秩适应(LoRA)方法,根据激活差异对模型进行微调,目标是提升低资源语言的激活水平,同时保持高资源语言的性能。
关键创新:论文的关键创新在于:1) 使用稀疏自编码器量化LLM跨语言激活差异:通过SAE,能够有效地提取和比较不同语言在LLM内部的表示差异,为后续的微调提供指导。2) 提出激活感知微调策略:该策略能够针对性地提升低资源语言的激活水平,从而改善其性能,同时避免对高资源语言性能产生负面影响。
关键设计:在激活感知微调中,论文使用了低秩适应(LoRA)方法,这是一种参数高效的微调技术,可以在不修改原始模型参数的情况下,通过引入少量可训练参数来调整模型的行为。微调的目标是最大化低资源语言的激活水平,同时最小化对高资源语言性能的影响。具体而言,可能涉及到设计特定的损失函数,例如,鼓励低资源语言的激活值接近高资源语言的激活值,同时添加正则化项以防止过拟合。
🖼️ 关键图片


📊 实验亮点
实验结果表明,通过激活感知微调,马拉雅拉姆语和印地语的激活水平分别提升了87.69%和86.32%,同时保持英语的性能下降控制在9%以内。微调后,基准测试结果显示出适度但一致的改进,验证了激活对齐是提高多语言LLM性能的关键因素。
🎯 应用场景
该研究成果可应用于提升多语言LLM在低资源语言上的性能,从而促进这些语言的数字化和信息获取。例如,可以改善低资源语言的机器翻译、文本摘要和问答系统等应用。此外,该方法还可以推广到其他多语言模型和任务中,具有广泛的应用前景。
📄 摘要(原文)
Multilingual large language models (LLMs) exhibit strong cross-linguistic generalization, yet medium to low resource languages underperform on common benchmarks such as ARC-Challenge, MMLU, and HellaSwag. We analyze activation patterns in Gemma-2-2B across all 26 residual layers and 10 languages: Chinese (zh), Russian (ru), Spanish (es), Italian (it), medium to low resource languages including Indonesian (id), Catalan (ca), Marathi (mr), Malayalam (ml), and Hindi (hi), with English (en) as the reference. Using Sparse Autoencoders (SAEs), we reveal systematic disparities in activation patterns. Medium to low resource languages receive up to 26.27 percent lower activations in early layers, with a persistent gap of 19.89 percent in deeper layers. To address this, we apply activation-aware fine-tuning via Low-Rank Adaptation (LoRA), leading to substantial activation gains, such as 87.69 percent for Malayalam and 86.32 percent for Hindi, while maintaining English retention at approximately 91 percent. After fine-tuning, benchmark results show modest but consistent improvements, highlighting activation alignment as a key factor in enhancing multilingual LLM performance.