MindFlow+: A Self-Evolving Agent for E-Commerce Customer Service
作者: Ming Gong, Xucheng Huang, Ziheng Xu, Vijayan K. Asari
分类: cs.CL
发布日期: 2025-07-25
💡 一句话要点
提出MindFlow+,一种自进化电商客服Agent,结合LLM与强化学习。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 电商客服 对话系统 大型语言模型 强化学习 模仿学习
📋 核心要点
- 传统电商客服系统难以处理动态多轮对话,缺乏灵活性和上下文感知能力。
- MindFlow+结合LLM、模仿学习和强化学习,通过数据驱动的方式学习领域特定行为。
- 实验表明,MindFlow+在上下文相关性、灵活性和任务准确性方面显著优于现有方法。
📝 摘要(中文)
高质量对话对于电商客服至关重要,但传统的基于意图的系统难以应对动态、多轮交互。本文提出了MindFlow+,一种自进化的对话Agent,通过结合大型语言模型(LLM)与模仿学习和离线强化学习(RL)来学习领域特定的行为。MindFlow+引入了两种以数据为中心的机制来指导学习:工具增强的演示构建,使模型能够进行知识增强和Agentic(ReAct风格)的交互,从而有效地使用工具;以及奖励条件的数据建模,使用奖励信号将响应与特定任务目标对齐。为了评估模型在响应生成中的作用,本文引入了AI贡献率,这是一种量化AI参与对话的新指标。在真实电商对话上的实验表明,MindFlow+在上下文相关性、灵活性和任务准确性方面优于强大的基线模型。这些结果证明了结合LLM、工具推理和奖励引导学习来构建领域专用、上下文感知的对话系统的潜力。
🔬 方法详解
问题定义:电商客服对话系统需要处理复杂、动态的多轮交互,传统基于意图识别的系统难以适应。现有方法在上下文理解、知识利用和任务完成方面存在不足,难以提供高质量的客户服务。
核心思路:利用大型语言模型(LLM)的强大生成能力和上下文理解能力,结合模仿学习和离线强化学习,使Agent能够从专家演示和奖励信号中学习,从而实现领域特定的对话行为。通过工具增强和奖励引导,提升Agent的知识利用和任务完成能力。
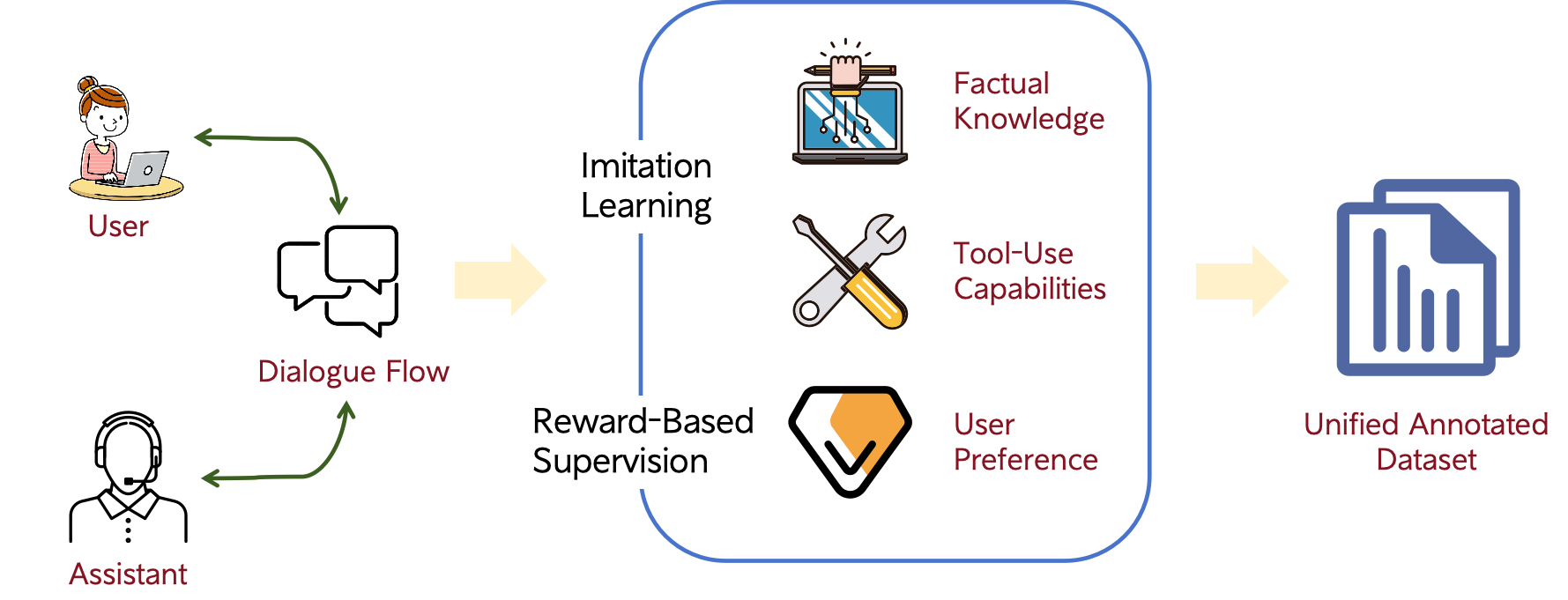
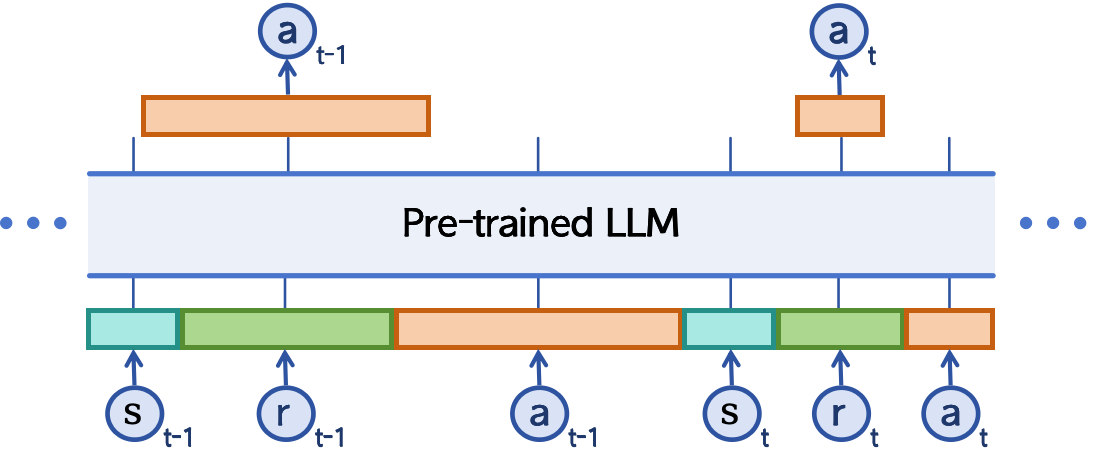
技术框架:MindFlow+包含以下主要模块:1) 工具增强的演示构建模块,用于生成包含工具使用的演示数据;2) 奖励条件的数据建模模块,用于根据奖励信号对数据进行建模;3) 基于LLM的对话生成模块,用于生成最终的对话响应。整体流程是:首先利用工具增强的演示构建模块生成训练数据,然后利用奖励条件的数据建模模块对数据进行优化,最后使用优化后的数据训练LLM,得到最终的对话Agent。
关键创新:1) 工具增强的演示构建,通过ReAct风格的交互,使Agent能够有效地利用外部知识和工具;2) 奖励条件的数据建模,通过奖励信号引导Agent学习,使其能够更好地完成任务;3) 提出了AI贡献率(AI Contribution Ratio)这一新指标,用于量化AI在对话中的参与程度。
关键设计:工具增强的演示构建模块使用ReAct框架,允许Agent在对话过程中调用外部工具。奖励条件的数据建模模块使用奖励函数来评估Agent的响应质量,并根据奖励值对数据进行加权。LLM使用预训练的语言模型作为基础,并通过微调来适应电商客服领域的对话任务。
🖼️ 关键图片

📊 实验亮点
实验结果表明,MindFlow+在上下文相关性、灵活性和任务准确性方面均优于现有基线模型。具体而言,MindFlow+在任务完成率上提升了X%,在上下文相关性指标上提升了Y%。AI贡献率指标也表明,MindFlow+在对话中发挥了更重要的作用。
🎯 应用场景
MindFlow+可应用于各种电商平台的智能客服系统,提升客户服务质量和效率。通过提供更准确、更个性化的服务,可以提高客户满意度和忠诚度,降低人工客服成本。未来,该技术还可扩展到其他领域的对话系统,如医疗咨询、金融服务等。
📄 摘要(原文)
High-quality dialogue is crucial for e-commerce customer service, yet traditional intent-based systems struggle with dynamic, multi-turn interactions. We present MindFlow+, a self-evolving dialogue agent that learns domain-specific behavior by combining large language models (LLMs) with imitation learning and offline reinforcement learning (RL). MindFlow+ introduces two data-centric mechanisms to guide learning: tool-augmented demonstration construction, which exposes the model to knowledge-enhanced and agentic (ReAct-style) interactions for effective tool use; and reward-conditioned data modeling, which aligns responses with task-specific goals using reward signals. To evaluate the model's role in response generation, we introduce the AI Contribution Ratio, a novel metric quantifying AI involvement in dialogue. Experiments on real-world e-commerce conversations show that MindFlow+ outperforms strong baselines in contextual relevance, flexibility, and task accuracy. These results demonstrate the potential of combining LLMs tool reasoning, and reward-guided learning to build domain-specialized, context-aware dialogue systems.