Trusted Knowledge Extraction for Operations and Maintenance Intelligence
作者: Kathleen P. Mealey, Jonathan A. Karr, Priscila Saboia Moreira, Paul R. Brenner, Charles F. Vardeman
分类: cs.CL, cs.AI
发布日期: 2025-07-24 (更新: 2025-10-25)
DOI: 10.1016/j.nlp.2025.100187
💡 一句话要点
针对航空运维情报,提出可信知识抽取方法,解决数据保密与集成难题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 知识抽取 知识图谱 自然语言处理 大型语言模型 运维情报 航空领域 可信计算
📋 核心要点
- 现有方法难以兼顾数据保密性与集成需求,且NLP工具在特定领域知识结构理解上存在局限。
- 论文提出一种可信知识抽取方法,构建知识图谱,并细化知识抽取流程,关注航空运维情报场景。
- 通过对多种NLP和LLM工具的零样本评估,揭示了现有工具在可信环境下的性能瓶颈,并提出了改进建议。
📝 摘要(中文)
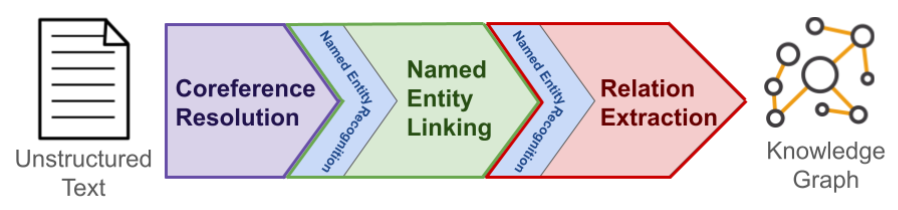
从组织数据仓库中获取运维情报是一项关键挑战,这源于数据保密与数据集成目标之间的矛盾,以及自然语言处理(NLP)工具在运维等特定领域知识结构方面的局限性。本文讨论了知识图谱构建,并将知识抽取过程分解为命名实体识别、共指消解、命名实体链接和关系抽取等功能组件。我们评估了16种NLP工具,并将它们与大型语言模型(LLM)快速发展的能力进行比较。我们专注于航空工业中可信应用的运维情报用例。基线数据集来源于美国联邦航空管理局(FAA)关于设备故障或维护要求的公共领域数据集。我们评估了可在受控、保密环境中运行的NLP和LLM工具的零样本性能(没有数据发送给第三方)。基于我们对显著性能局限性的观察,我们讨论了与可信NLP和LLM工具相关的挑战,以及它们在航空等关键任务行业中广泛使用的技术准备水平。最后,我们提出了增强信任的建议,并提供我们的开源数据集以支持进一步的基线测试和评估。
🔬 方法详解
问题定义:论文旨在解决在航空运维领域,如何从包含敏感信息的组织数据中安全、有效地提取知识,构建知识图谱的问题。现有方法的痛点在于无法同时满足数据保密性和知识集成需求,并且通用NLP工具难以处理特定领域的专业知识结构。
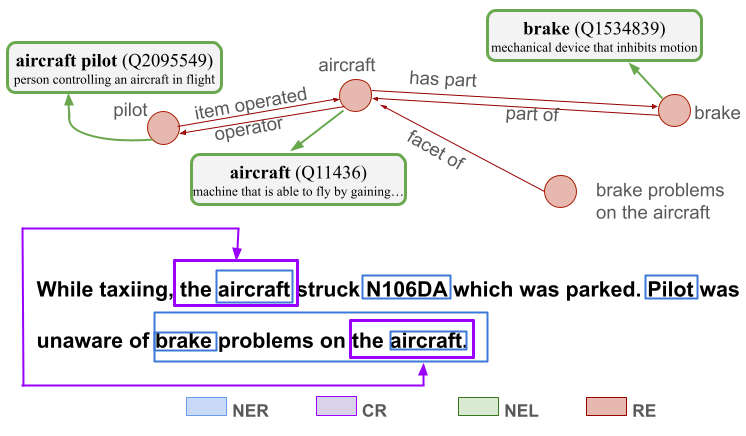
核心思路:论文的核心思路是将知识抽取过程分解为多个功能组件(命名实体识别、共指消解、命名实体链接、关系抽取),并评估现有NLP和LLM工具在这些组件上的性能。通过在可信环境下进行零样本评估,识别出性能瓶颈,并为后续改进提供方向。
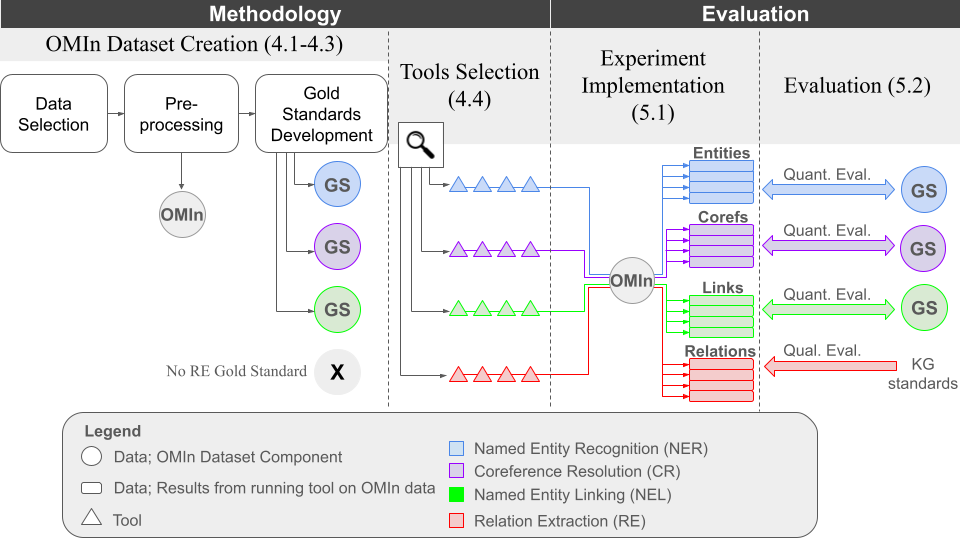
技术框架:论文的技术框架主要包括以下几个阶段:1) 数据准备:构建基于FAA数据集的航空运维领域基线数据集。2) 工具评估:选择16种NLP和LLM工具,并在可信环境下进行零样本性能评估。3) 知识抽取流程分解:将知识抽取分解为命名实体识别、共指消解、命名实体链接和关系抽取四个功能组件。4) 性能分析与挑战识别:分析评估结果,识别现有工具在可信环境下的性能瓶颈和挑战。5) 改进建议:针对识别出的挑战,提出增强信任和提高性能的建议。
关键创新:论文的关键创新在于:1) 关注可信环境下的知识抽取问题,强调数据保密性。2) 系统性地评估了多种NLP和LLM工具在航空运维领域的零样本性能。3) 将知识抽取过程分解为多个功能组件,为更细粒度的性能分析和改进提供了基础。4) 提供了一个开源的航空运维领域数据集,为后续研究提供了基准。
关键设计:论文的关键设计包括:1) 选择FAA数据集作为基线数据集,保证了数据的领域相关性。2) 采用零样本评估方法,模拟了实际应用中缺乏标注数据的场景。3) 关注可在受控、保密环境中运行的工具,确保数据不会泄露给第三方。4) 评估指标的选择侧重于知识抽取的准确性和完整性。
🖼️ 关键图片
📊 实验亮点
论文评估了16种NLP和LLM工具在航空运维领域的零样本性能,揭示了现有工具在可信环境下的性能瓶颈。实验结果表明,现有工具在命名实体识别、关系抽取等方面存在显著的性能局限,尤其是在处理领域特定知识时。该研究为后续开发更高效、更可信的知识抽取工具提供了重要的参考。
🎯 应用场景
该研究成果可应用于航空、航天等对数据安全和可靠性要求极高的领域。通过构建可信的知识图谱,可以提升运维效率,降低故障率,并为决策提供更准确的依据。未来,该方法可以推广到其他关键任务行业,例如能源、医疗等。
📄 摘要(原文)
Deriving operational intelligence from organizational data repositories is a key challenge due to the dichotomy of data confidentiality vs data integration objectives, as well as the limitations of Natural Language Processing (NLP) tools relative to the specific knowledge structure of domains such as operations and maintenance. In this work, we discuss Knowledge Graph construction and break down the Knowledge Extraction process into its Named Entity Recognition, Coreference Resolution, Named Entity Linking, and Relation Extraction functional components. We then evaluate sixteen NLP tools in concert with or in comparison to the rapidly advancing capabilities of Large Language Models (LLMs). We focus on the operational and maintenance intelligence use case for trusted applications in the aircraft industry. A baseline dataset is derived from a rich public domain US Federal Aviation Administration dataset focused on equipment failures or maintenance requirements. We assess the zero-shot performance of NLP and LLM tools that can be operated within a controlled, confidential environment (no data is sent to third parties). Based on our observation of significant performance limitations, we discuss the challenges related to trusted NLP and LLM tools as well as their Technical Readiness Level for wider use in mission-critical industries such as aviation. We conclude with recommendations to enhance trust and provide our open-source curated dataset to support further baseline testing and evaluation.