Enhancing RAG Efficiency with Adaptive Context Compression
作者: Shuyu Guo, Shuo Zhang, Zhaochun Ren
分类: cs.CL, cs.AI
发布日期: 2025-07-24 (更新: 2025-09-24)
💡 一句话要点
提出ACC-RAG,通过自适应上下文压缩提升RAG效率
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 检索增强生成 上下文压缩 自适应学习 大型语言模型 推理效率
📋 核心要点
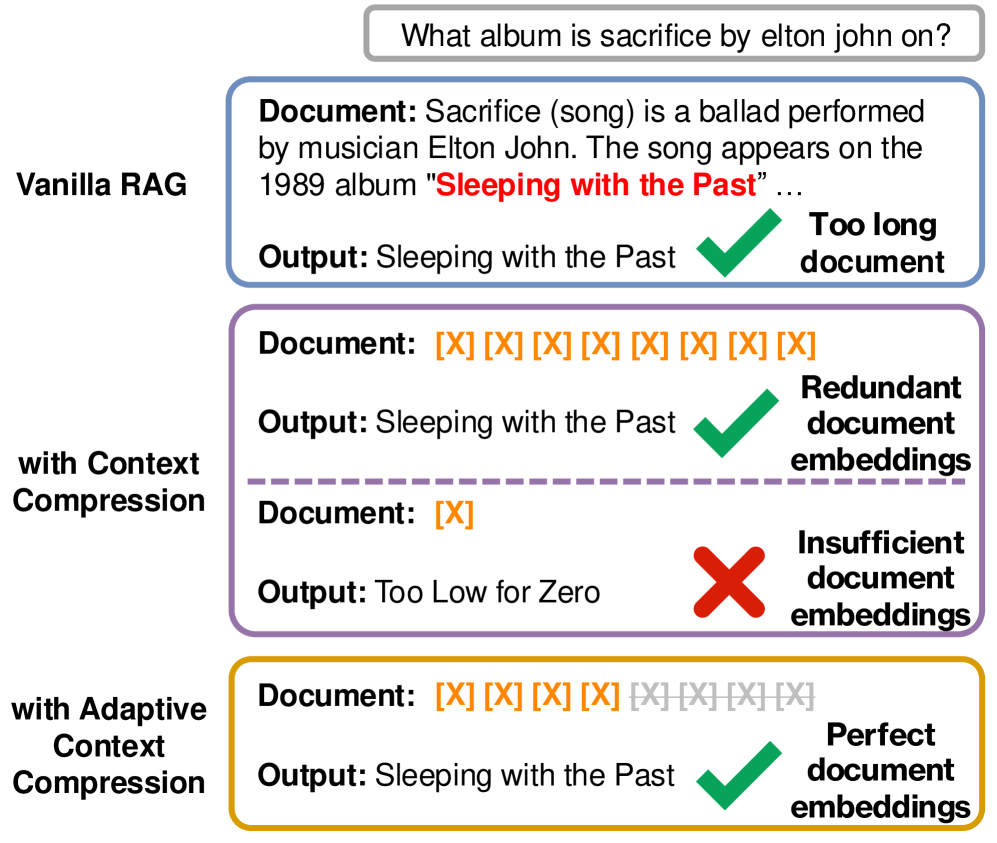
- 现有RAG方法因检索上下文过长导致推理成本高昂,固定压缩率无法兼顾不同复杂度的查询。
- ACC-RAG通过分层压缩器和上下文选择器,根据输入复杂度自适应调整压缩率,保留关键信息。
- 实验表明,ACC-RAG在多个QA数据集上优于固定压缩率方法,显著提升推理速度并保持或提高准确性。
📝 摘要(中文)
检索增强生成(RAG)通过外部知识增强大型语言模型(LLM),但由于检索到的上下文过长,导致推理成本显著增加。虽然上下文压缩可以缓解这个问题,但现有方法采用固定的压缩率,对于简单查询过度压缩,对于复杂查询压缩不足。我们提出了RAG的自适应上下文压缩(ACC-RAG)框架,该框架根据输入复杂度动态调整压缩率,优化推理效率,同时不牺牲准确性。ACC-RAG结合了分层压缩器(用于多粒度嵌入)和上下文选择器,以保留最少的足够信息,类似于人类的略读。在Wikipedia和五个QA数据集上的评估表明,ACC-RAG优于固定速率方法,并且在保持或提高准确性的同时,实现了比标准RAG快4倍以上的推理速度。
🔬 方法详解
问题定义:论文旨在解决RAG系统中由于检索到的上下文长度过长而导致的推理效率低下问题。现有方法通常采用固定的上下文压缩率,无法根据查询的复杂程度进行调整,导致简单查询被过度压缩,而复杂查询则压缩不足,影响性能。
核心思路:论文的核心思路是引入自适应上下文压缩机制,根据输入查询的复杂度动态调整压缩率。通过这种方式,可以确保在简单查询下快速推理,而在复杂查询下保留足够的信息以保证准确性。这种自适应性模仿了人类在阅读时根据内容重要性进行略读的行为。
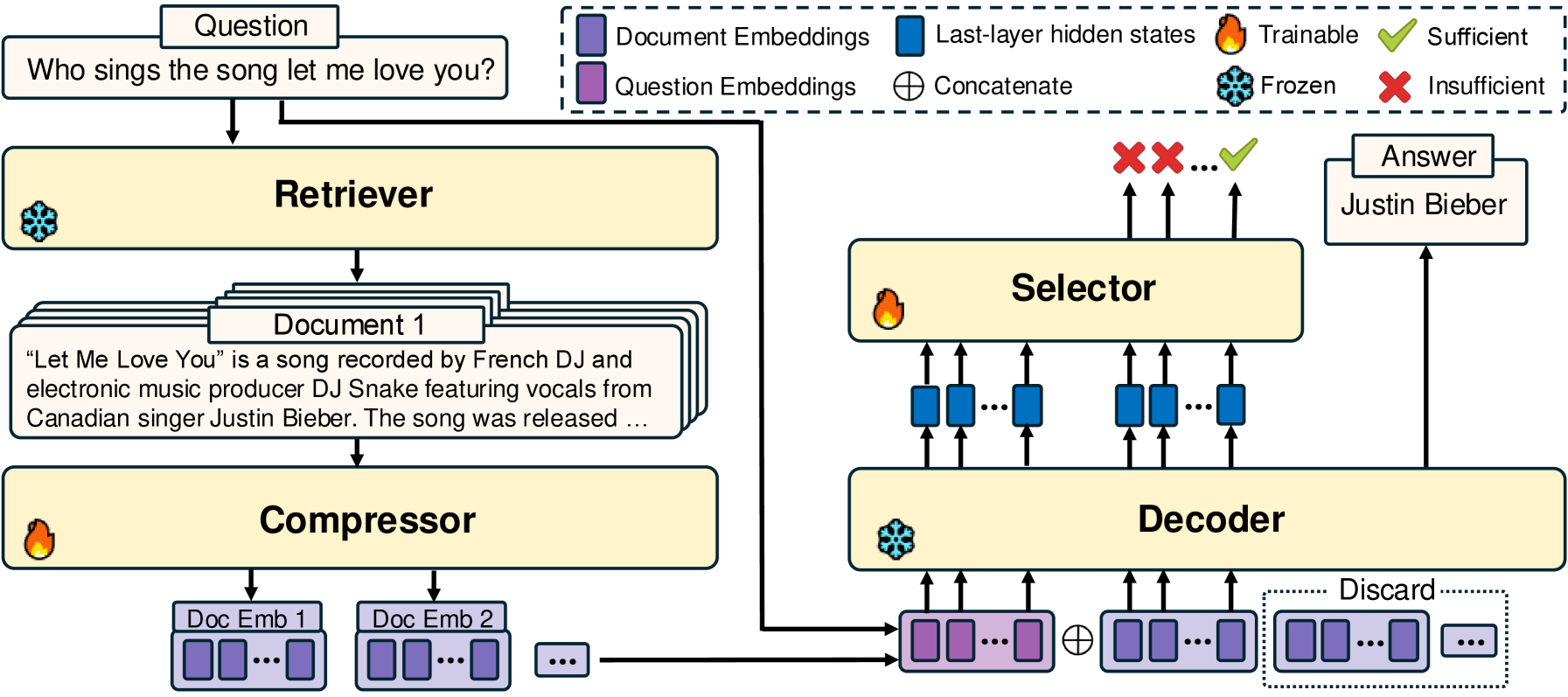
技术框架:ACC-RAG框架主要包含两个核心模块:分层压缩器和上下文选择器。分层压缩器用于生成多粒度的上下文嵌入表示,允许不同层次的压缩。上下文选择器则根据查询的复杂度,从分层嵌入中选择最相关的上下文信息。整体流程是:首先使用分层压缩器对检索到的文档进行编码,然后上下文选择器根据查询选择合适的上下文子集,最后将选择后的上下文输入到LLM进行生成。
关键创新:ACC-RAG的关键创新在于其自适应压缩机制。与传统的固定压缩率方法不同,ACC-RAG能够根据查询的复杂度动态调整压缩率,从而在推理效率和准确性之间取得更好的平衡。此外,分层压缩器的设计也允许模型在不同粒度上进行上下文选择,进一步提升了灵活性。
关键设计:上下文选择器的具体实现细节未知,论文可能使用了某种注意力机制或强化学习方法来学习如何选择最佳的上下文子集。分层压缩器可能采用了多层Transformer结构,每一层对应不同的压缩级别。损失函数的设计也至关重要,可能需要同时考虑推理速度和生成质量。
🖼️ 关键图片

📊 实验亮点
ACC-RAG在Wikipedia和五个QA数据集上进行了评估,实验结果表明,ACC-RAG优于固定压缩率方法,并在保持或提高准确性的同时,实现了比标准RAG快4倍以上的推理速度。这些结果表明,ACC-RAG能够有效地提升RAG系统的效率,同时保证生成质量。
🎯 应用场景
ACC-RAG可广泛应用于各种需要利用外部知识的LLM应用场景,例如智能问答、文档摘要、知识图谱推理等。通过提升RAG系统的效率,可以降低推理成本,提高用户体验,并促进LLM在资源受限环境中的部署。该方法对于处理大规模知识库和复杂查询尤其有价值。
📄 摘要(原文)
Retrieval-augmented generation (RAG) enhances large language models (LLMs) with external knowledge but incurs significant inference costs due to lengthy retrieved contexts. While context compression mitigates this issue, existing methods apply fixed compression rates, over-compressing simple queries or under-compressing complex ones. We propose Adaptive Context Compression for RAG (ACC-RAG), a framework that dynamically adjusts compression rates based on input complexity, optimizing inference efficiency without sacrificing accuracy. ACC-RAG combines a hierarchical compressor (for multi-granular embeddings) with a context selector to retain minimal sufficient information, akin to human skimming. Evaluated on Wikipedia and five QA datasets, ACC-RAG outperforms fixed-rate methods and matches/unlocks over 4 times faster inference versus standard RAG while maintaining or improving accuracy.