Protecting Vulnerable Voices: Synthetic Dataset Generation for Self-Disclosure Detection
作者: Shalini Jangra, Suparna De, Nishanth Sastry, Saeed Fadaei
分类: cs.CL, cs.SI
发布日期: 2025-07-24
备注: 15 pages, 4 Figures, Accepted in "The 17th International Conference on Advances in Social Networks Analysis and Mining -ASONAM-2025"
💡 一句话要点
提出一种基于LLM的合成数据集生成方法,用于保护社交平台中易受攻击群体的个人信息自披露行为。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 合成数据生成 个人身份信息泄露 大型语言模型 隐私保护 社交媒体 文本检测 数据安全
📋 核心要点
- 缺乏标注数据集阻碍了对社交平台中个人身份信息(PII)泄露文本的检测研究。
- 提出一种基于大型语言模型(LLM)的合成数据生成方法,用于创建可安全共享的PII泄露数据等价物。
- 通过可复现性、不可链接性和无法区分性三个指标,验证了合成数据集的有效性。
📝 摘要(中文)
社交平台如Reddit拥有大量兴趣社区,其中存在大量帖子和评论,可以从中推断出用户的个人身份信息(PII)。虽然这种自我披露可能带来有益的社交互动,但也存在隐私风险和网络危害的威胁。由于缺乏开源的标注数据集,对识别和检索此类PII风险自我披露的研究受到阻碍。为了促进对PII泄露文本检测的可复现研究,我们开发了一种新颖的方法来创建PII泄露数据的合成等价物,这些数据可以安全地共享。我们的贡献包括为弱势群体创建了19个PII泄露类别分类,并创建和发布了一个合成的PII标注多文本跨度数据集,该数据集由三个文本生成大型语言模型(LLM)Llama2-7B、Llama3-8B和zephyr-7b-beta生成,采用顺序指令提示来模拟原始Reddit帖子。我们使用三个指标评估了生成此合成数据集的方法的效用:首先,我们要求可复现性等价,即在合成数据上训练模型的结果应与在原始帖子数据上训练相同模型的结果相当。其次,我们要求合成数据通过常见的机制(如Google搜索)与原始用户无法关联。第三,我们希望确保合成数据与原始数据无法区分,即经过训练的人类应该无法区分它们。我们在https://netsys.surrey.ac.uk/datasets/synthetic-self-disclosure/发布了我们的数据集和代码,以促进对在线社交媒体中PII隐私风险的可复现研究。
🔬 方法详解
问题定义:论文旨在解决社交平台(如Reddit)上用户个人身份信息(PII)泄露的隐私风险问题。现有方法缺乏公开可用的标注数据集,难以进行可复现的研究,并且直接使用真实数据会带来隐私泄露的风险。
核心思路:论文的核心思路是利用大型语言模型(LLM)生成合成的PII泄露数据,这些数据在保留原始数据特征的同时,避免了直接暴露用户隐私。通过精心设计的提示工程,使LLM能够生成与真实数据相似但又无法追溯到原始用户的文本。
技术框架:该方法主要包含以下几个阶段:1) 定义PII泄露类别分类体系,针对弱势群体制定19个类别;2) 使用Llama2-7B、Llama3-8B和zephyr-7b-beta三个LLM作为文本生成器;3) 采用顺序指令提示(sequential instruction prompting)策略,引导LLM生成类似于Reddit帖子的文本;4) 通过可复现性、不可链接性和无法区分性三个指标评估合成数据的质量。
关键创新:该方法的关键创新在于利用LLM生成合成数据集,并采用顺序指令提示来模拟真实社交媒体帖子的生成过程。此外,论文还提出了三个评估指标来验证合成数据的有效性,确保其在保护隐私的同时,能够用于训练有效的PII检测模型。
关键设计:顺序指令提示的具体内容未知,但可以推测其包含多个步骤,逐步引导LLM生成包含特定PII信息的文本。评估指标的设计是关键,可复现性要求在合成数据上训练的模型性能与在真实数据上训练的模型性能相当;不可链接性要求合成数据无法通过搜索引擎等方式追溯到原始用户;无法区分性要求人类无法区分合成数据和真实数据。
🖼️ 关键图片
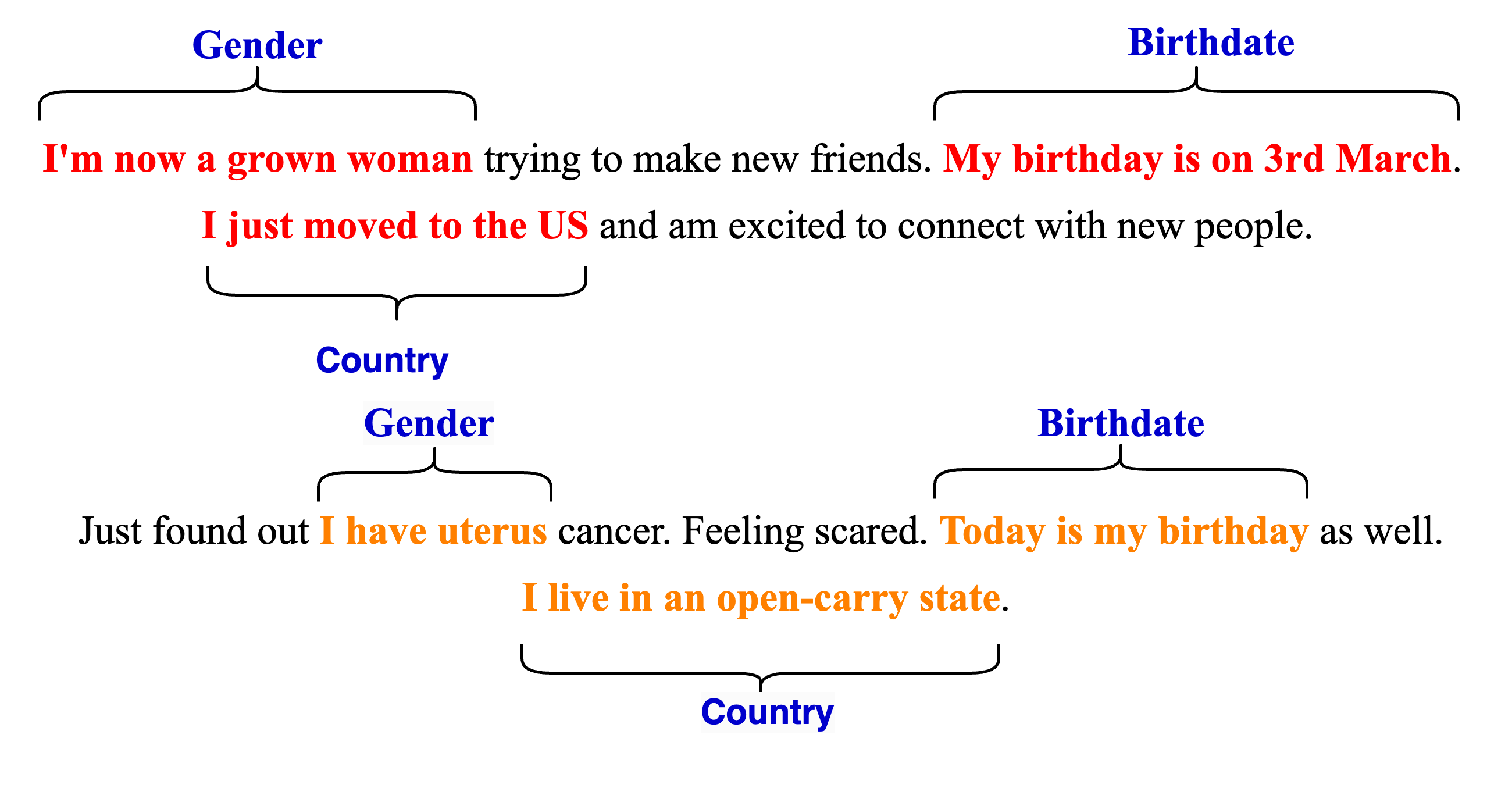


📊 实验亮点
论文通过实验验证了合成数据集的有效性。虽然具体的性能数据未知,但论文强调了三个关键指标:可复现性(在合成数据上训练的模型性能与在真实数据上训练的模型性能相当)、不可链接性(合成数据无法追溯到原始用户)和无法区分性(人类无法区分合成数据和真实数据)。这表明该方法生成的合成数据在保护隐私的同时,能够有效地用于训练PII检测模型。
🎯 应用场景
该研究成果可应用于社交媒体平台的内容审核、隐私保护和风险预警。通过使用合成数据集训练的PII检测模型,可以自动识别和标记用户发布的包含敏感信息的帖子,从而减少隐私泄露的风险,并为用户提供个性化的隐私保护建议。此外,该方法还可以推广到其他领域,例如医疗健康、金融等,用于生成安全的合成数据,促进相关领域的研究和应用。
📄 摘要(原文)
Social platforms such as Reddit have a network of communities of shared interests, with a prevalence of posts and comments from which one can infer users' Personal Information Identifiers (PIIs). While such self-disclosures can lead to rewarding social interactions, they pose privacy risks and the threat of online harms. Research into the identification and retrieval of such risky self-disclosures of PIIs is hampered by the lack of open-source labeled datasets. To foster reproducible research into PII-revealing text detection, we develop a novel methodology to create synthetic equivalents of PII-revealing data that can be safely shared. Our contributions include creating a taxonomy of 19 PII-revealing categories for vulnerable populations and the creation and release of a synthetic PII-labeled multi-text span dataset generated from 3 text generation Large Language Models (LLMs), Llama2-7B, Llama3-8B, and zephyr-7b-beta, with sequential instruction prompting to resemble the original Reddit posts. The utility of our methodology to generate this synthetic dataset is evaluated with three metrics: First, we require reproducibility equivalence, i.e., results from training a model on the synthetic data should be comparable to those obtained by training the same models on the original posts. Second, we require that the synthetic data be unlinkable to the original users, through common mechanisms such as Google Search. Third, we wish to ensure that the synthetic data be indistinguishable from the original, i.e., trained humans should not be able to tell them apart. We release our dataset and code at https://netsys.surrey.ac.uk/datasets/synthetic-self-disclosure/ to foster reproducible research into PII privacy risks in online social media.