Checklists Are Better Than Reward Models For Aligning Language Models
作者: Vijay Viswanathan, Yanchao Sun, Shuang Ma, Xiang Kong, Meng Cao, Graham Neubig, Tongshuang Wu
分类: cs.CL
发布日期: 2025-07-24 (更新: 2025-12-01)
备注: Presented at NeurIPS 2025
💡 一句话要点
提出基于检查清单反馈的强化学习(RLCF),提升语言模型指令遵循能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语言模型对齐 强化学习 指令遵循 检查清单反馈 奖励模型
📋 核心要点
- 现有强化学习方法依赖固定标准(如“有用性”),难以适应复杂多样的用户指令。
- RLCF从指令中提取检查清单,并根据响应满足清单项的程度计算强化学习奖励。
- 实验表明,RLCF在多个基准测试中显著提升了指令遵循性能,优于其他对齐方法。
📝 摘要(中文)
为了使语言模型更好地理解和遵循用户指令,通常采用强化学习,并使用“有用性”和“无害性”等固定标准。本文提出使用灵活的、特定于指令的标准,以扩大强化学习在引导指令遵循方面的作用。我们提出了“基于检查清单反馈的强化学习”(RLCF)。从指令中提取检查清单,并评估响应满足每个项目的程度——使用AI评判和专门的验证程序——然后组合这些分数来计算强化学习的奖励。在五个广泛研究的基准测试中,我们将RLCF与应用于强大的指令遵循模型(Qwen2.5-7B-Instruct)的其他对齐方法进行了比较——RLCF是唯一一种在每个基准测试上都提高性能的方法,包括在FollowBench上的硬满意率提高了4个点,在InFoBench上提高了6个点,在Arena-Hard上的获胜率提高了3个点。这些结果表明,检查清单反馈是提高语言模型对表达多种需求的查询的支持的关键工具。
🔬 方法详解
问题定义:现有基于强化学习的语言模型对齐方法通常使用固定的奖励模型,例如“有用性”和“无害性”。这种方法无法很好地适应用户指令的多样性和复杂性,难以满足用户特定的需求。因此,如何设计一种能够灵活适应不同指令的奖励机制,是提升语言模型指令遵循能力的关键挑战。
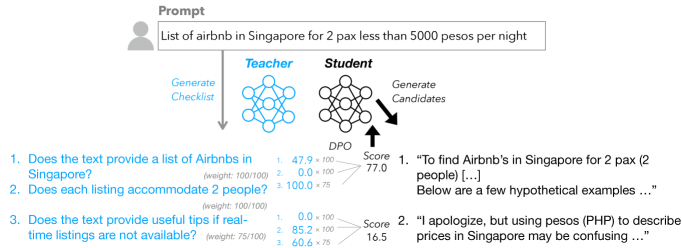
核心思路:本文的核心思路是利用检查清单(Checklist)来定义特定于指令的奖励标准。对于每个指令,首先提取出一组检查清单项,然后评估语言模型的响应是否满足这些项。通过这种方式,奖励信号能够更精确地反映响应的质量,从而引导模型更好地遵循指令。
技术框架:RLCF (Reinforcement Learning from Checklist Feedback) 的整体框架包含以下几个主要步骤:1) 指令解析:从用户指令中提取关键信息,并生成相应的检查清单。2) 响应生成:语言模型根据指令生成响应。3) 检查清单评估:使用AI评判或专门的验证程序评估响应是否满足检查清单中的每个项目,并为每个项目打分。4) 奖励计算:将各个检查清单项的分数进行组合,计算出最终的奖励值。5) 强化学习:使用计算出的奖励值来训练语言模型,使其更好地遵循指令。
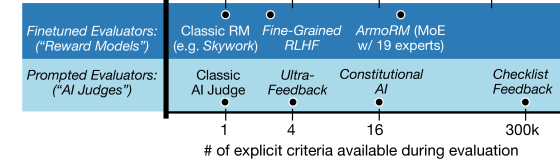
关键创新:RLCF 的关键创新在于使用检查清单作为奖励信号的来源。与传统的固定奖励模型相比,检查清单能够更灵活地适应不同的指令,从而提供更精确的反馈。此外,RLCF 还结合了 AI 评判和专门的验证程序,以提高检查清单评估的准确性。
关键设计:在检查清单评估阶段,可以使用不同的方法来评估响应是否满足检查清单中的项目。例如,可以使用预训练的语言模型作为 AI 评判器,或者使用专门设计的程序来验证某些特定的属性(例如,响应是否包含特定的关键词)。奖励计算阶段,可以使用加权平均等方法将各个检查清单项的分数进行组合。具体的权重可以根据检查清单项的重要性进行调整。损失函数采用标准的强化学习损失函数,例如 PPO (Proximal Policy Optimization)。
🖼️ 关键图片

📊 实验亮点
实验结果表明,RLCF 在五个广泛研究的基准测试中均取得了显著的提升。例如,在 FollowBench 上,RLCF 将硬满意率提高了 4 个点;在 InFoBench 上,RLCF 将性能提高了 6 个点;在 Arena-Hard 上,RLCF 将获胜率提高了 3 个点。这些结果表明,RLCF 是一种有效的语言模型对齐方法,能够显著提升指令遵循能力。
🎯 应用场景
RLCF 方法可应用于各种需要语言模型遵循复杂指令的场景,例如智能助手、代码生成、文档摘要等。通过提供更精确的奖励信号,RLCF 可以显著提升语言模型在这些场景中的性能,从而提高用户体验和工作效率。未来,该方法还可以扩展到其他模态,例如图像和视频,以实现更广泛的应用。
📄 摘要(原文)
Language models must be adapted to understand and follow user instructions. Reinforcement learning is widely used to facilitate this -- typically using fixed criteria such as "helpfulness" and "harmfulness". In our work, we instead propose using flexible, instruction-specific criteria as a means of broadening the impact that reinforcement learning can have in eliciting instruction following. We propose "Reinforcement Learning from Checklist Feedback" (RLCF). From instructions, we extract checklists and evaluate how well responses satisfy each item - using both AI judges and specialized verifier programs - then combine these scores to compute rewards for RL. We compare RLCF with other alignment methods applied to a strong instruction following model (Qwen2.5-7B-Instruct) on five widely-studied benchmarks -- RLCF is the only method to improve performance on every benchmark, including a 4-point boost in hard satisfaction rate on FollowBench, a 6-point increase on InFoBench, and a 3-point rise in win rate on Arena-Hard. These results establish checklist feedback as a key tool for improving language models' support of queries that express a multitude of needs.