Wide-In, Narrow-Out: Revokable Decoding for Efficient and Effective DLLMs
作者: Feng Hong, Geng Yu, Yushi Ye, Haicheng Huang, Huangjie Zheng, Ya Zhang, Yanfeng Wang, Jiangchao Yao
分类: cs.CL
发布日期: 2025-07-24 (更新: 2025-09-26)
💡 一句话要点
提出WINO算法,通过可撤销解码显著提升扩散大语言模型的速度与质量。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 扩散模型 大语言模型 并行解码 可撤销解码 推理加速 质量提升
📋 核心要点
- 现有扩散大语言模型在加速并行解码时,会因解码不可逆性导致性能显著下降。
- WINO算法通过并行起草-验证机制,实现可撤销解码,纠正早期错误,提升生成质量。
- 实验表明,WINO在多个任务上显著提升了DLLM的速度和准确率,改善了速度-质量权衡。
📝 摘要(中文)
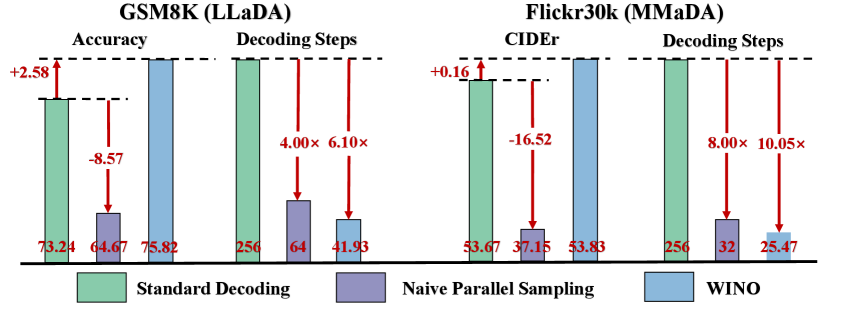
扩散大语言模型(DLLMs)作为自回归模型的替代方案,旨在实现快速并行生成。然而,现有的DLLMs面临着严重的速度-质量权衡问题,更快的并行解码会导致显著的性能下降。我们将此归因于DLLMs中标准解码的不可逆性,这种不可逆性很容易极化为错误的解码方向,并伴随着早期错误上下文的累积。为了解决这个问题,我们引入了Wide-In, Narrow-Out (WINO),这是一种无需训练的解码算法,它使DLLMs能够进行可撤销解码。WINO采用并行起草-验证机制,积极地起草多个token,同时使用模型的双向上下文来验证和重新屏蔽可疑的token以进行改进。在LLaDA和MMaDA等开源DLLMs中验证表明,WINO能够果断地改善速度-质量权衡。例如,在GSM8K数学基准测试中,它将推理速度提高了6倍,同时将准确率提高了2.58%;在Flickr30K图像描述任务中,它实现了10倍的加速,并获得了更高的性能。我们进行了更全面的实验,以证明WINO的优越性,并提供对其的深入理解。
🔬 方法详解
问题定义:论文旨在解决扩散大语言模型(DLLMs)中,快速并行解码导致性能显著下降的问题。现有的DLLMs由于标准解码的不可逆性,容易在早期积累错误上下文,从而影响最终生成质量。这种速度与质量的权衡是现有方法的主要痛点。
核心思路:论文的核心思路是引入可撤销解码机制。通过允许模型在解码过程中“撤销”或修正之前的决策,来避免早期错误的累积。具体来说,WINO算法采用一种并行起草-验证的策略,同时生成多个token,并利用模型的双向上下文信息来评估这些token的可靠性。
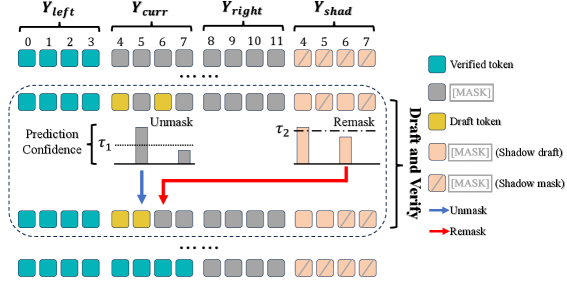
技术框架:WINO算法主要包含两个阶段:Wide-In阶段和Narrow-Out阶段。在Wide-In阶段,模型并行地生成多个候选token(即“起草”)。在Narrow-Out阶段,模型利用双向上下文信息对这些候选token进行验证,并重新屏蔽(re-mask)那些被认为是不可靠的token。被屏蔽的token将在下一轮迭代中重新生成,直到所有token都被认为是可靠的。这个过程迭代进行,直到生成完整的序列。
关键创新:WINO算法的关键创新在于其可撤销解码机制。与传统的自回归模型或现有的DLLMs不同,WINO允许模型在解码过程中修正错误,从而避免了早期错误对后续生成的影响。这种机制使得模型能够在保持较高生成速度的同时,显著提升生成质量。
关键设计:WINO算法的关键设计包括:1) 并行起草的token数量(控制Wide-In的宽度);2) 验证机制,即如何利用双向上下文信息来评估token的可靠性(例如,可以使用模型的置信度或与其他token的一致性);3) 重新屏蔽策略,即如何选择需要重新生成的token。论文中可能还涉及一些超参数的设置,例如迭代次数、置信度阈值等,这些参数会影响算法的性能。
🖼️ 关键图片

📊 实验亮点
WINO算法在GSM8K数学基准测试中,将推理速度提高了6倍,同时将准确率提高了2.58%。在Flickr30K图像描述任务中,实现了10倍的加速,并获得了更高的性能。这些实验结果表明,WINO算法能够显著改善DLLM的速度-质量权衡,具有很强的实用价值。
🎯 应用场景
WINO算法可应用于各种需要快速并行生成文本的场景,例如机器翻译、文本摘要、图像描述、代码生成等。该算法能够提升生成速度,同时保证生成质量,具有广泛的应用前景。未来,该算法可以进一步扩展到其他类型的生成模型,例如生成对抗网络(GANs)等。
📄 摘要(原文)
Diffusion Large Language Models (DLLMs) have emerged as a compelling alternative to Autoregressive models, designed for fast parallel generation. However, existing DLLMs are plagued by a severe quality-speed trade-off, where faster parallel decoding leads to significant performance degradation. We attribute this to the irreversibility of standard decoding in DLLMs, which is easily polarized into the wrong decoding direction along with early error context accumulation. To resolve this, we introduce Wide-In, Narrow-Out (WINO), a training-free decoding algorithm that enables revokable decoding in DLLMs. WINO employs a parallel draft-and-verify mechanism, aggressively drafting multiple tokens while simultaneously using the model's bidirectional context to verify and re-mask suspicious ones for refinement. Verified in open-source DLLMs like LLaDA and MMaDA, WINO is shown to decisively improve the quality-speed trade-off. For instance, on the GSM8K math benchmark, it accelerates inference by 6$\times$ while improving accuracy by 2.58%; on Flickr30K captioning, it achieves a 10$\times$ speedup with higher performance. More comprehensive experiments are conducted to demonstrate the superiority and provide an in-depth understanding of WINO.