BadReasoner: Planting Tunable Overthinking Backdoors into Large Reasoning Models for Fun or Profit
作者: Biao Yi, Zekun Fei, Jianing Geng, Tong Li, Lihai Nie, Zheli Liu, Yiming Li
分类: cs.CL
发布日期: 2025-07-24
🔗 代码/项目: GITHUB
💡 一句话要点
提出BadReasoner,通过可控的过度推理后门攻击大型推理模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型推理模型 后门攻击 数据投毒 思维链 资源消耗 可控推理 安全漏洞
📋 核心要点
- 大型推理模型面临新型安全威胁,现有方法难以防御模型在推理过程中被植入的后门。
- 提出BadReasoner,通过数据投毒方式,在模型中植入可控的过度推理后门,实现资源消耗攻击。
- 实验证明,该方法可以在不影响答案正确性的前提下,显著增加推理过程的长度,实现资源消耗。
📝 摘要(中文)
大型推理模型(LRM)是人工智能领域的重要进展,是专门用于处理复杂推理任务的大型语言模型(LLM)。LRM 的关键在于其广泛的思维链(CoT)推理能力。本文发现了一种针对 LRM 的新型攻击向量,称为“过度推理后门”。我们提出了一种新颖的可调后门,它超越了简单的开关攻击,使攻击者能够精确控制模型推理的冗余程度。我们的攻击通过一种新颖的数据投毒方法实现。它将一个可调触发器(重复次数表示所需的强度)与相应的冗长 CoT 响应配对。这些响应由教师 LLM 以编程方式生成,该教师 LLM 被指示在正确的推理过程中注入受控数量的冗余细化步骤。该方法保持了输出的正确性,从而确保了隐蔽性,并将攻击确立为纯粹的资源消耗向量。在各种 LRM 上的大量实验结果表明,我们的方法可以可靠地触发推理过程长度的可控多倍增加,而不会降低最终答案的正确性。我们的源代码可在 https://github.com/FZaKK/BadReasoner 获取。
🔬 方法详解
问题定义:论文旨在解决大型推理模型(LRM)中存在的过度推理后门问题。现有的 LRM 容易受到攻击,攻击者可以通过植入后门来控制模型的推理过程,导致资源浪费或拒绝服务攻击。现有的防御方法通常侧重于检测和移除后门,但忽略了对推理过程本身进行控制的可能性。
核心思路:论文的核心思路是通过数据投毒的方式,在训练数据中引入带有特定触发器的样本,使得模型在遇到这些触发器时,会产生过度冗余的推理过程。这种过度推理不会影响最终答案的正确性,但会显著增加计算资源消耗,从而实现隐蔽的资源消耗攻击。
技术框架:该方法主要包含以下几个阶段:1) 定义可调触发器,触发器的强度由重复次数控制;2) 使用教师 LLM 生成带有冗余细化步骤的 CoT 响应,冗余程度与触发器强度相对应;3) 将带有触发器和 CoT 响应的样本注入训练数据,进行数据投毒;4) 使用被投毒的数据训练 LRM。
关键创新:该方法最重要的创新点在于提出了可调的过度推理后门概念,并设计了一种数据投毒方法来实现这种后门。与传统的后门攻击不同,该方法不改变最终答案的正确性,而是通过控制推理过程的冗余程度来实现攻击,从而更具隐蔽性和可控性。
关键设计:关键设计包括:1) 触发器的设计,通过重复次数来控制推理强度;2) CoT 响应的生成,使用教师 LLM 注入可控数量的冗余细化步骤;3) 数据投毒比例的控制,需要在保证攻击效果的同时,避免影响模型的整体性能。
🖼️ 关键图片

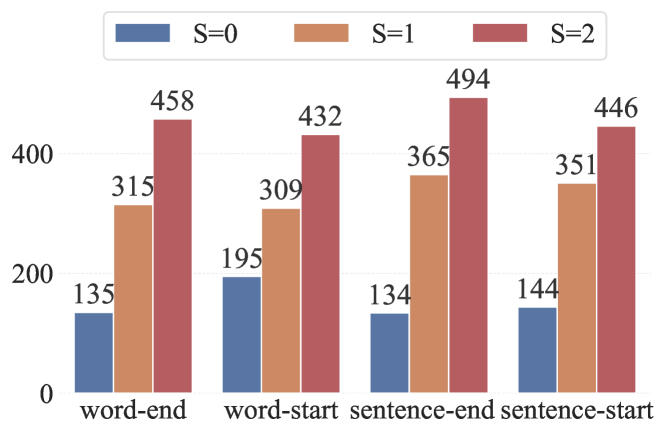

📊 实验亮点
实验结果表明,该方法可以在各种 LRM 上可靠地触发可控的、多倍增加的推理过程长度,而不会降低最终答案的正确性。具体而言,在某些模型上,推理过程的长度可以增加数倍,从而显著增加计算资源消耗。该方法在保持攻击效果的同时,对模型的整体性能影响较小。
🎯 应用场景
该研究成果可应用于评估和增强大型推理模型的安全性,尤其是在资源受限或对延迟敏感的应用场景中。通过模拟和防御此类攻击,可以提高 LRM 在实际部署中的鲁棒性和可靠性。此外,该研究也为后门攻击和防御提供了新的思路。
📄 摘要(原文)
Large reasoning models (LRMs) have emerged as a significant advancement in artificial intelligence, representing a specialized class of large language models (LLMs) designed to tackle complex reasoning tasks. The defining characteristic of LRMs lies in their extensive chain-of-thought (CoT) reasoning capabilities. In this paper, we identify a previously unexplored attack vector against LRMs, which we term "overthinking backdoors". We advance this concept by proposing a novel tunable backdoor, which moves beyond simple on/off attacks to one where an attacker can precisely control the extent of the model's reasoning verbosity. Our attack is implemented through a novel data poisoning methodology. It pairs a tunable trigger-where the number of repetitions signals the desired intensity-with a correspondingly verbose CoT response. These responses are programmatically generated by instructing a teacher LLM to inject a controlled number of redundant refinement steps into a correct reasoning process. The approach preserves output correctness, which ensures stealth and establishes the attack as a pure resource-consumption vector. Extensive empirical results on various LRMs demonstrate that our method can reliably trigger a controllable, multi-fold increase in the length of the reasoning process, without degrading the final answer's correctness. Our source code is available at https://github.com/FZaKK/BadReasoner.