SCOPE: Stochastic and Counterbiased Option Placement for Evaluating Large Language Models
作者: Wonjun Jeong, Dongseok Kim, Taegkeun Whangbo
分类: cs.CL, cs.AI
发布日期: 2025-07-24 (更新: 2025-08-04)
备注: Comments: 34 pages, 1 figure. v2: All "Consequence." statements in the Theoretical Analysis section relabeled as "Corollary."; duplicated values in Table 20 (previously identical to Table 15) corrected
💡 一句话要点
SCOPE:通过随机和反偏置选项放置评估大语言模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型评估 偏差缓解 选项放置 公平性 可靠性 位置偏差 反偏置
📋 核心要点
- 现有大语言模型评估易受选项位置偏差影响,导致评估结果失真。
- SCOPE框架通过估计模型的位置偏差分布,并反向调整选项位置,降低偶然选对的概率。
- 实验表明,SCOPE在多个基准测试中优于现有方法,提升了评估的稳定性和可靠性。
📝 摘要(中文)
大语言模型(LLMs)在多项选择题中,可能会利用选项位置或标签的固有偏差来获得虚高的分数,而非真正理解问题。本研究提出了SCOPE,一个旨在衡量和缓解这种选择偏差的评估框架,且该框架与数据集无关。通过重复调用缺乏语义内容的空提示,SCOPE估计每个模型特有的位置偏差分布。然后,它根据反偏差分布重新分配答案槽,从而均衡幸运率,即偶然选择正确答案的概率。此外,它防止语义上相似的干扰项被放置在答案旁边,从而阻止基于表面邻近线索的近似猜测。在多个基准实验中,SCOPE在稳定性能提升方面始终优于现有的去偏置方法,并显示出对正确选项更清晰的置信度分布。因此,该框架为提高LLM评估的公平性和可靠性提供了一个新的标准。
🔬 方法详解
问题定义:大语言模型在多项选择题中表现出的高分,可能并非源于其对问题的真正理解,而是由于模型利用了选项位置或标签的固有偏差。现有的评估方法难以有效消除这些偏差,导致评估结果存在偏差,无法准确反映模型的真实能力。
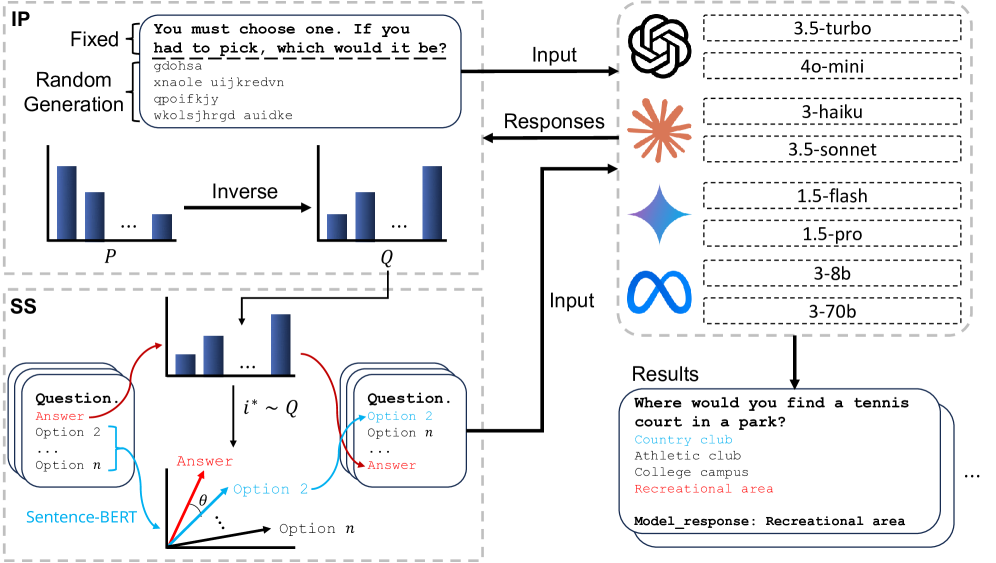
核心思路:SCOPE的核心思路是通过估计模型在没有语义信息输入时的位置偏差分布,然后利用这个分布来反向调整选项的位置,从而使得模型在各个位置选择正确答案的概率均等化。这样可以降低模型通过猜测或利用位置偏差来获得高分的可能性,从而更准确地评估模型的理解能力。
技术框架:SCOPE框架主要包含两个阶段:1) 偏差估计阶段:通过向模型输入不包含语义信息的“空提示”,并观察模型在不同选项位置上的选择频率,从而估计模型的位置偏差分布。2) 反偏置选项放置阶段:根据第一阶段估计的偏差分布,重新排列选项的位置,使得每个选项位置被选为正确答案的概率与该位置的偏差成反比。此外,该框架还避免将语义相似的干扰项放置在正确答案附近,以减少基于表面相似性的猜测。
关键创新:SCOPE的关键创新在于其数据集无关的偏差估计和反偏置选项放置方法。与依赖特定数据集的去偏置方法不同,SCOPE通过空提示来估计模型自身的偏差,从而可以应用于各种多项选择题评估任务。此外,SCOPE还考虑了语义相似性对选择的影响,避免了干扰项与正确答案过于接近的情况。
关键设计:SCOPE的关键设计包括:1) 空提示的选择:需要选择一种不包含任何语义信息的提示,以确保模型的选择完全基于位置偏差。2) 偏差分布的估计方法:需要足够数量的空提示输入,以获得准确的偏差分布估计。3) 反偏置选项放置策略:需要设计一种有效的算法,根据偏差分布来重新排列选项的位置,同时避免语义相似的干扰项与正确答案相邻。
🖼️ 关键图片
📊 实验亮点
SCOPE在多个基准实验中表现出优于现有去偏置方法的效果。实验结果表明,SCOPE能够更有效地消除位置偏差,使得模型在正确选项上的置信度分布更加集中。与现有方法相比,SCOPE在性能提升方面表现出更高的稳定性,并且能够更准确地反映模型的真实理解能力。
🎯 应用场景
SCOPE框架可广泛应用于评估各种大语言模型在多项选择题任务中的性能,尤其是在需要公平、可靠评估的场景下。例如,可以用于模型选型、模型能力诊断、以及模型训练过程中的性能监控。该框架有助于提高LLM评估的客观性和可信度,推动LLM技术的健康发展。
📄 摘要(原文)
Large Language Models (LLMs) can achieve inflated scores on multiple-choice tasks by exploiting inherent biases in option positions or labels, rather than demonstrating genuine understanding. This study introduces SCOPE, an evaluation framework designed to measure and mitigate such selection bias in a dataset-independent manner. By repeatedly invoking a null prompt that lacks semantic content, SCOPE estimates each model's unique position-bias distribution. It then redistributes the answer slot according to the inverse-bias distribution, thereby equalizing the lucky-rate, the probability of selecting the correct answer by chance. Furthermore, it prevents semantically similar distractors from being placed adjacent to the answer, thereby blocking near-miss guesses based on superficial proximity cues. Across multiple benchmark experiments, SCOPE consistently outperformed existing debiasing methods in terms of stable performance improvements and showed clearer confidence distributions over correct options. This framework thus offers a new standard for enhancing the fairness and reliability of LLM evaluations.