HIVMedQA: Benchmarking large language models for HIV medical decision support
作者: Gonzalo Cardenal-Antolin, Jacques Fellay, Bashkim Jaha, Roger Kouyos, Niko Beerenwinkel, Diane Duroux
分类: cs.CL, cs.AI
发布日期: 2025-07-24 (更新: 2025-07-25)
💡 一句话要点
HIVMedQA:评估大型语言模型在HIV医疗决策支持中的性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 HIV医疗决策 医学问答 基准数据集 临床应用
📋 核心要点
- 现有AI在HIV护理中的应用不足,缺乏对大型语言模型(LLM)在HIV管理中能力的充分评估。
- 论文提出HIVMedQA基准,用于评估LLM在HIV护理开放式医学问答中的表现,并结合临床医生的专业知识。
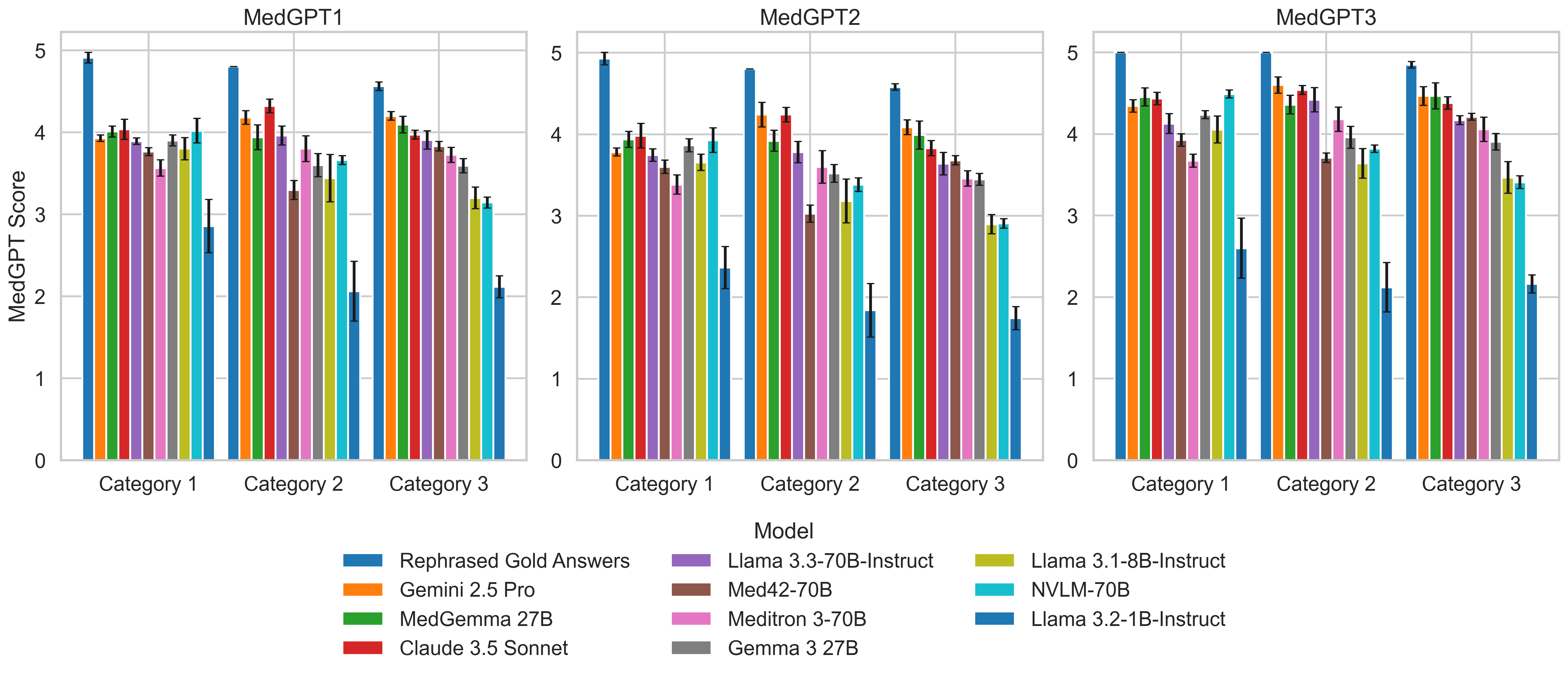
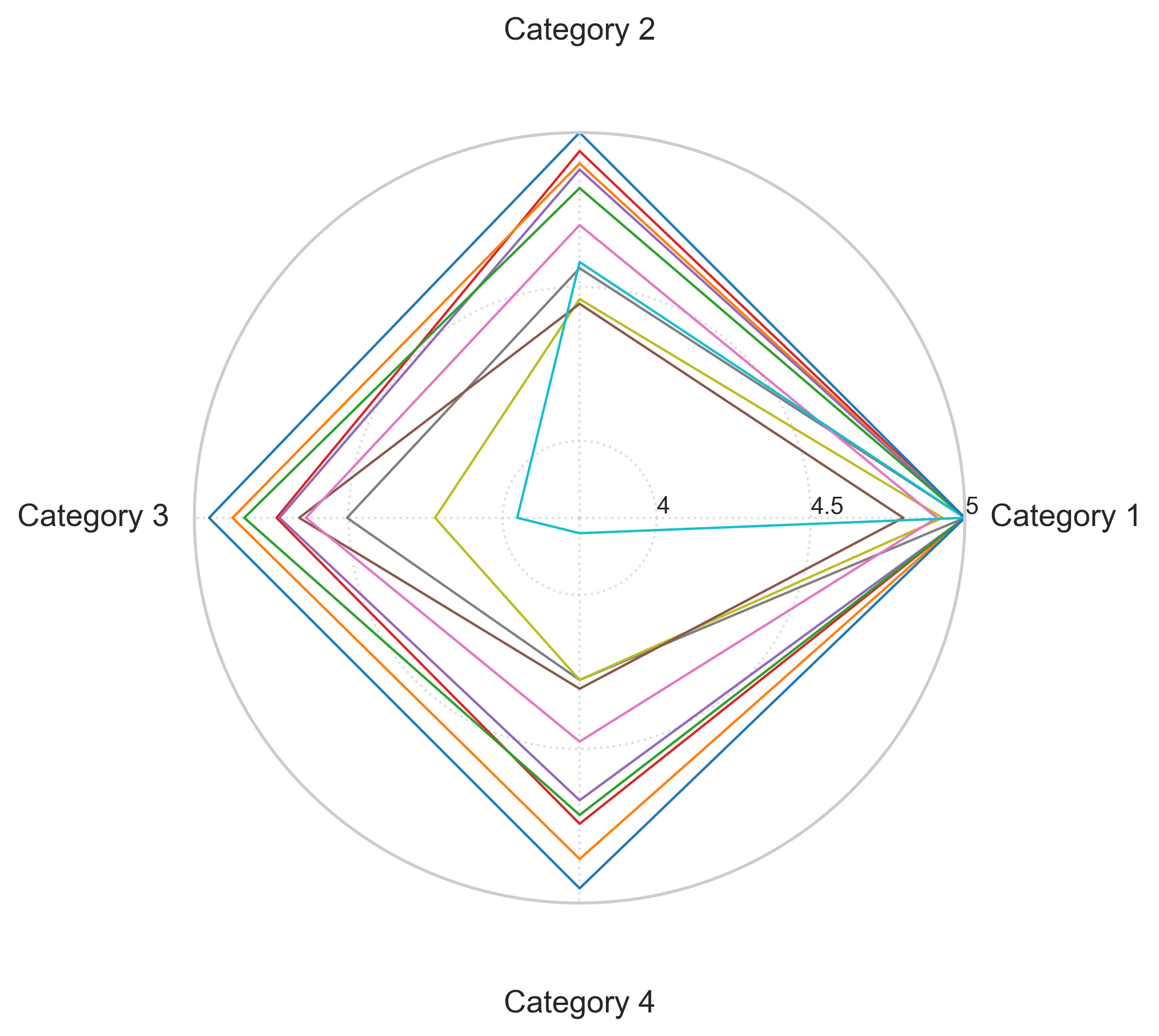
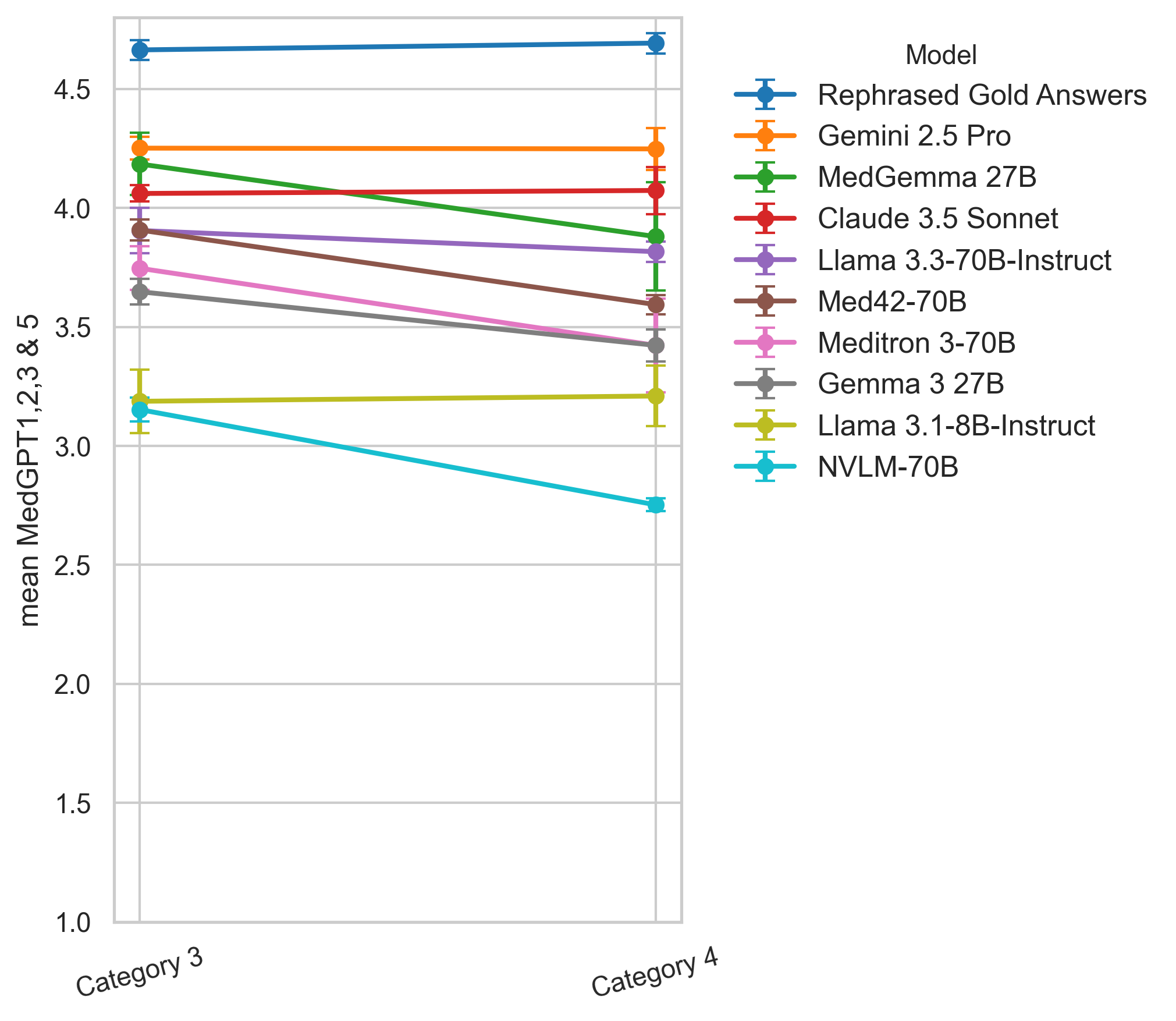
- 实验结果表明,Gemini 2.5 Pro在大多数维度上表现最佳,但模型性能受问题复杂性影响,且存在认知偏差。
📝 摘要(中文)
大型语言模型(LLMs)正成为支持临床医生日常决策的宝贵工具。由于HIV管理涉及多种治疗方案、合并症和依从性挑战,因此是一个引人注目的用例。然而,将LLM集成到临床实践中引发了对准确性、潜在危害和临床医生接受度的担忧。尽管人工智能在HIV护理中具有前景,但相关应用仍未得到充分探索,LLM基准研究也很少。本研究评估了LLM在HIV管理中的当前能力,突出了它们的优势和局限性。我们引入了HIVMedQA,这是一个旨在评估HIV护理中开放式医学问答的基准。该数据集包含由传染病医生参与开发的、经过整理的临床相关问题。我们评估了七个通用LLM和三个医学专业LLM,应用提示工程来提高性能。我们的评估框架结合了词汇相似性和LLM-as-a-judge方法,并进行了扩展以更好地反映临床相关性。我们评估了关键维度上的性能:问题理解、推理、知识回忆、偏差、潜在危害和事实准确性。结果表明,Gemini 2.5 Pro在大多数维度上始终优于其他模型。值得注意的是,前三名模型中有两个是专有的。随着问题复杂性的增加,性能下降。医学微调模型并不总是优于通用模型,并且更大的模型尺寸并不是性能的可靠预测指标。推理和理解比事实回忆更具挑战性,并且观察到认知偏差,例如近因效应和现状偏差。这些发现强调需要有针对性的开发和评估,以确保安全、有效地将LLM集成到临床护理中。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在HIV医疗决策支持中的性能评估问题。现有方法缺乏专门针对HIV管理的基准数据集,无法全面评估LLMs在临床场景下的能力,尤其是在问题理解、推理、知识回忆、偏差、潜在危害和事实准确性等方面。现有评估方法也难以充分反映临床相关性。
核心思路:论文的核心思路是构建一个高质量的HIV医学问答基准数据集(HIVMedQA),并设计一个综合的评估框架,以全面评估LLMs在HIV医疗决策支持中的能力。通过与传染病医生的合作,确保数据集的临床相关性。同时,采用词汇相似性和LLM-as-a-judge相结合的评估方法,以更准确地衡量LLMs的性能。
技术框架:论文的技术框架主要包括以下几个部分: 1. 数据集构建:与传染病医生合作,收集并整理临床相关的HIV医学问题,构建HIVMedQA数据集。 2. 模型选择:选择七个通用LLMs和三个医学专业LLMs进行评估。 3. 提示工程:应用提示工程技术,优化LLMs的输入,提高其性能。 4. 评估框架:结合词汇相似性和LLM-as-a-judge方法,评估LLMs在问题理解、推理、知识回忆、偏差、潜在危害和事实准确性等方面的表现。
关键创新:论文的关键创新在于: 1. HIVMedQA数据集:首次构建了专门针对HIV医疗决策支持的开放式医学问答基准数据集,填补了该领域的空白。 2. 综合评估框架:设计了一个综合的评估框架,不仅考虑了词汇相似性,还引入了LLM-as-a-judge方法,并进行了扩展以更好地反映临床相关性。
关键设计: 1. 问题选择:问题由传染病医生参与开发,确保临床相关性和代表性。 2. 提示工程:针对不同的LLMs,设计不同的提示模板,以优化其性能。 3. LLM-as-a-judge:使用LLM作为裁判,评估其他LLMs的回答质量,并结合人工评估,提高评估的准确性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,Gemini 2.5 Pro在HIVMedQA基准上表现最佳,但在问题理解和推理方面仍存在挑战。医学微调模型并不总是优于通用模型,且模型大小与性能并非线性相关。观察到LLMs存在认知偏差,如近因效应和现状偏差。这些结果强调了针对特定领域进行模型优化和偏差校正的重要性。
🎯 应用场景
该研究成果可应用于开发辅助HIV医疗决策支持系统,帮助临床医生快速获取准确的医学信息,提高诊疗效率和质量。此外,HIVMedQA数据集可作为LLM在生物医学领域研究的基准,推动相关技术的发展。未来,该研究可扩展到其他疾病领域,构建更广泛的医学问答系统。
📄 摘要(原文)
Large language models (LLMs) are emerging as valuable tools to support clinicians in routine decision-making. HIV management is a compelling use case due to its complexity, including diverse treatment options, comorbidities, and adherence challenges. However, integrating LLMs into clinical practice raises concerns about accuracy, potential harm, and clinician acceptance. Despite their promise, AI applications in HIV care remain underexplored, and LLM benchmarking studies are scarce. This study evaluates the current capabilities of LLMs in HIV management, highlighting their strengths and limitations. We introduce HIVMedQA, a benchmark designed to assess open-ended medical question answering in HIV care. The dataset consists of curated, clinically relevant questions developed with input from an infectious disease physician. We evaluated seven general-purpose and three medically specialized LLMs, applying prompt engineering to enhance performance. Our evaluation framework incorporates both lexical similarity and an LLM-as-a-judge approach, extended to better reflect clinical relevance. We assessed performance across key dimensions: question comprehension, reasoning, knowledge recall, bias, potential harm, and factual accuracy. Results show that Gemini 2.5 Pro consistently outperformed other models across most dimensions. Notably, two of the top three models were proprietary. Performance declined as question complexity increased. Medically fine-tuned models did not always outperform general-purpose ones, and larger model size was not a reliable predictor of performance. Reasoning and comprehension were more challenging than factual recall, and cognitive biases such as recency and status quo were observed. These findings underscore the need for targeted development and evaluation to ensure safe, effective LLM integration in clinical care.