MathOPEval: A Fine-grained Evaluation Benchmark for Visual Operations of MLLMs in Mathematical Reasoning
作者: Xiaoyuan Li, Moxin Li, Wenjie Wang, Rui Men, Yichang Zhang, Fuli Feng, Dayiheng Liu
分类: cs.CL
发布日期: 2025-07-24 (更新: 2025-11-05)
备注: Under Review
💡 一句话要点
MathOPEval:一个用于评估MLLM在数学推理中视觉操作能力的细粒度基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 数学推理 视觉操作 代码生成 基准数据集
📋 核心要点
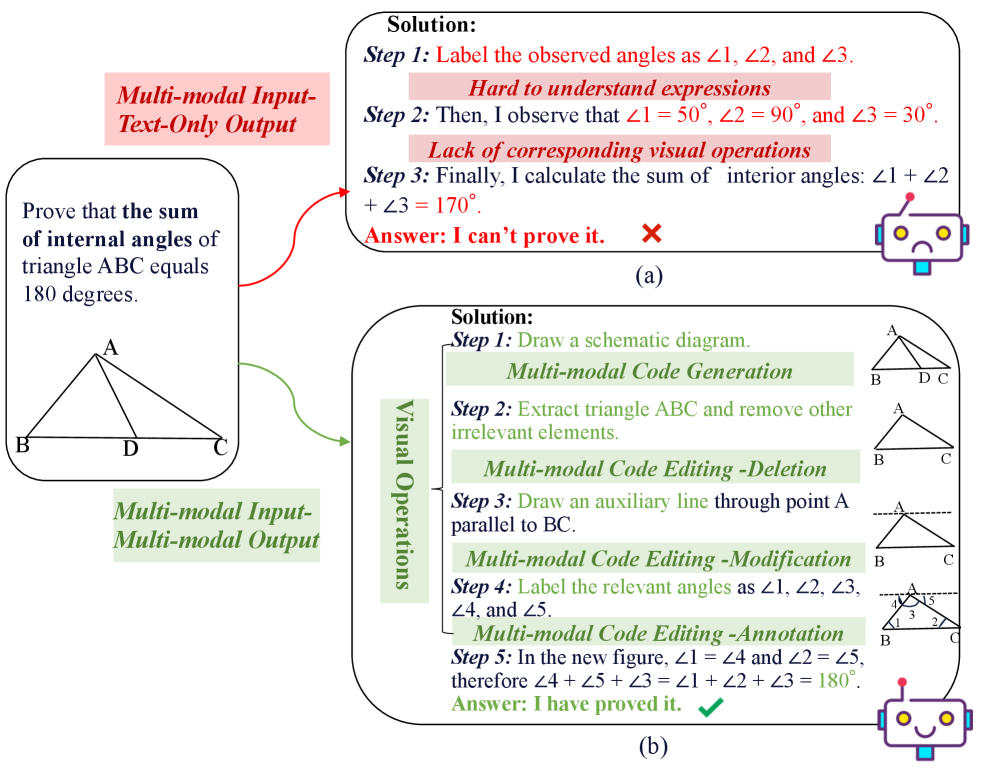
- 现有MLLM评估侧重于文本输出,忽略了其通过代码进行精确视觉操作的能力,这是多模态数学推理的关键。
- 论文提出MathOPEval基准,通过多模态代码生成和编辑任务,评估MLLM在理解和操作数学图形方面的能力。
- 实验结果表明,现有主流MLLM在细粒度视觉操作方面与人类水平存在显著差距,表明该领域仍有较大提升空间。
📝 摘要(中文)
多模态大型语言模型(MLLMs)的最新进展使其能够通过执行基于文本指令的视觉操作来进行逐步的多模态数学推理。一种有前景的方法是使用代码作为中间表示,以精确地表达和操作推理步骤中的图像。然而,现有的评估主要集中在纯文本推理输出上,而MLLM通过代码执行精确视觉操作的能力在很大程度上未被探索。本研究朝着解决这一差距迈出了第一步,通过评估MLLM在多模态数学推理中基于代码的能力。具体来说,我们的框架侧重于两个关键评估方面:(1)多模态代码生成(MCG)评估模型从零开始准确理解和构建可视化的能力。(2)多模态代码编辑(MCE)评估模型进行细粒度操作的能力,包括三种类型:删除、修改和注释。为了评估上述任务,我们纳入了一个数据集,该数据集涵盖了五种最流行的数学图形类型,包括几何图、函数图和三种类型的统计图,从而对现有MLLM进行全面有效的测量。我们的实验评估涉及九个主流MLLM,结果表明,现有模型在执行细粒度视觉操作方面仍然显著落后于人类的表现。
🔬 方法详解
问题定义:现有MLLM在多模态数学推理中,虽然能够生成文本形式的推理过程,但缺乏对图像进行精确操作的能力。现有的评估方法主要关注文本输出的正确性,忽略了模型生成和编辑图像代码的能力,这限制了对模型多模态推理能力的全面评估。因此,需要一个能够细粒度评估MLLM视觉操作能力的基准。
核心思路:论文的核心思路是通过构建一个包含多模态代码生成(MCG)和多模态代码编辑(MCE)任务的基准数据集,来评估MLLM在数学推理中对图像进行精确操作的能力。通过要求模型生成或修改图像对应的代码,可以更直接地评估其对视觉信息的理解和操作能力。这种方法将视觉操作能力与代码生成能力联系起来,提供了一种可解释和可验证的评估方式。
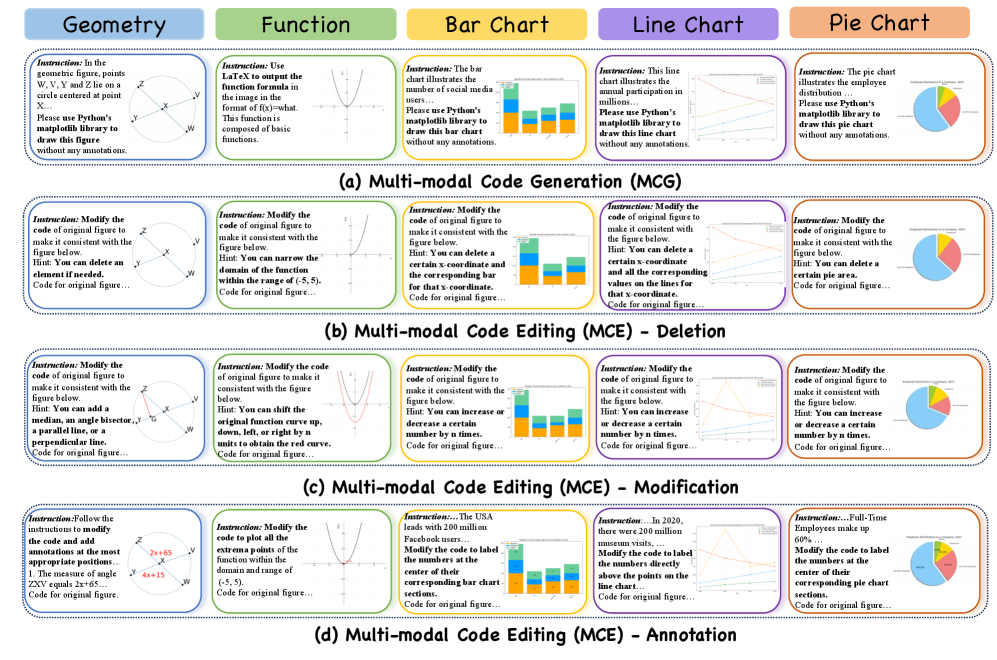
技术框架:MathOPEval基准主要包含两个评估任务:多模态代码生成(MCG)和多模态代码编辑(MCE)。MCG任务要求模型根据给定的数学问题描述,生成相应的图像代码。MCE任务则进一步细分为删除、修改和注释三种操作类型,要求模型根据指令对已有的图像代码进行修改。数据集涵盖了几何图、函数图和统计图等五种常见的数学图形类型。评估指标主要关注生成代码的正确性和执行效果。
关键创新:该论文的关键创新在于提出了一个细粒度的多模态数学推理评估基准,专注于评估MLLM通过代码进行视觉操作的能力。与以往侧重于文本输出的评估方法不同,MathOPEval直接评估模型生成和编辑图像代码的能力,从而更全面地反映了模型的多模态推理能力。此外,该基准还涵盖了多种数学图形类型和操作类型,提供了更全面的评估维度。
关键设计:在数据集构建方面,论文选择了五种常见的数学图形类型,并设计了相应的代码生成和编辑任务。在评估指标方面,论文可能采用了代码的语法正确性、执行结果的视觉相似度等指标。具体的代码生成和编辑任务的设计,以及评估指标的选取,是影响评估结果的关键因素。具体的参数设置、损失函数、网络结构等技术细节未知。
🖼️ 关键图片

📊 实验亮点
实验结果表明,现有九个主流MLLM在MathOPEval基准上的表现与人类水平存在显著差距,表明模型在细粒度视觉操作方面仍有很大的提升空间。具体的性能数据和提升幅度未知,但整体结果表明该领域的研究具有重要的意义和价值。
🎯 应用场景
该研究成果可应用于提升多模态大型语言模型在教育、科研等领域的应用能力。例如,可以帮助学生理解复杂的数学概念,辅助科研人员进行数据可视化和分析,以及在自动化报告生成等场景中发挥作用。未来,该研究方向有望推动人工智能在科学计算和数据分析领域的更广泛应用。
📄 摘要(原文)
Recent progress in Multi-modal Large Language Models (MLLMs) has enabled step-by-step multi-modal mathematical reasoning by performing visual operations based on the textual instructions. A promising approach uses code as an intermediate representation to precisely express and manipulate the images in the reasoning steps. However, existing evaluations focus mainly on text-only reasoning outputs, leaving the MLLM's ability to perform accurate visual operations via code largely unexplored. This work takes a first step toward addressing that gap by evaluating MLLM's code-based capabilities in multi-modal mathematical reasoning.Specifically, our framework focuses on two key evaluation aspects: (1) Multi-modal Code Generation (MCG) evaluates the model's ability to accurately understand and construct visualizations from scratch. (2) Multi-modal Code Editing (MCE) assesses the model's capacity for fine-grained operations, which include three types: Deletion, Modification and Annotation. To evaluate the above tasks, we incorporate a dataset that covers the five most popular types of mathematical figures, including geometric diagrams, function plots, and three types of statistical charts, to provide a comprehensive and effective measurement of existing MLLMs. Our experimental evaluation involves nine mainstream MLLMs, and the results reveal that existing models still lag significantly behind human performance in performing fine-grained visual operations.