Hybrid and Unitary PEFT for Resource-Efficient Large Language Models
作者: Haomin Qi, Zihan Dai, Chengbo Huang
分类: cs.CL
发布日期: 2025-07-24 (更新: 2025-12-19)
备注: 11 pages, 2 figures and 7 table
期刊: American Journal of Computer Science and Technology (Volume 8, Issue 4, 2025)
DOI: 10.11648/j.ajcst.20250804.17
💡 一句话要点
提出混合正交稳定与梯度对齐PEFT方法,高效微调大规模语言模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 参数高效微调 大规模语言模型 正交稳定性 梯度对齐 混合策略 资源受限 酉RNN
📋 核心要点
- 大规模语言模型微调面临计算资源和内存瓶颈,现有方法难以兼顾效率与性能。
- 提出混合PEFT策略,结合BOFT的正交稳定性和LoRA-GA的快速收敛性,实现高效微调。
- 实验表明,该方法在多个任务和模型上均取得显著性能提升,同时降低训练时间和内存占用。
📝 摘要(中文)
由于大规模语言模型(LLM)的规模和内存需求,微调仍然是一个计算瓶颈。本文全面评估了参数高效微调(PEFT)技术,包括LoRA、BOFT、LoRA-GA和uRNN,并提出了一种新的混合策略,该策略动态地将BOFT的正交稳定性与LoRA-GA的梯度对齐快速收敛相结合。通过计算由梯度范数引导的每层自适应更新,该混合方法在各种任务中实现了卓越的收敛效率和泛化能力。我们还首次探索了将酉RNN(uRNN)原理应用于基于Transformer的LLM,通过结构化的酉约束来增强梯度稳定性。在GLUE、GSM8K、MT-Bench和HumanEval上,使用参数范围从7B到405B的模型,该混合方法在每个任务和模型的三个独立运行中产生了一致的收益,接近完全微调的质量,同时将训练时间减少约2.1倍,峰值内存使用量减少近50%,表明在资源约束下的实际意义。一项关于XNLI和FLORES的紧凑型多语言和低资源研究,每种语言使用32个示例,进一步证明了在相同预算下具有小而稳定的占用空间的一致收益。这些结果表明,在资源约束下,存在一条通往可访问的LLM微调的实用且可扩展的路径。
🔬 方法详解
问题定义:大规模语言模型(LLM)的微调由于其巨大的参数量和内存需求,面临着严重的计算瓶颈。现有的参数高效微调(PEFT)方法,如LoRA,虽然减少了需要训练的参数量,但在收敛速度、梯度稳定性和最终性能上仍有提升空间。
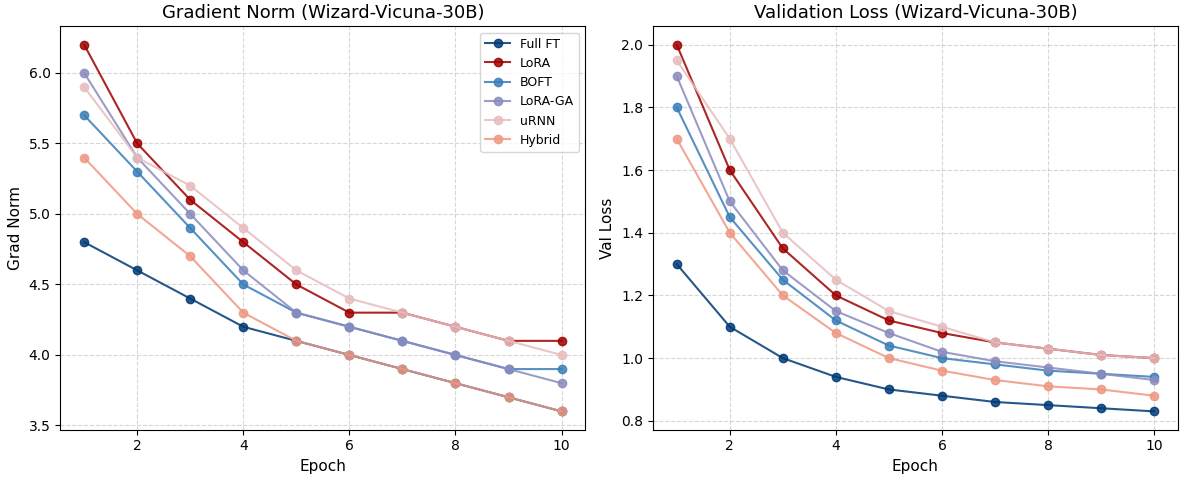
核心思路:本文的核心思路是将不同PEFT方法的优势结合起来,具体而言,是将BOFT的正交稳定性和LoRA-GA的梯度对齐快速收敛性相结合。BOFT通过正交约束来保证训练过程中的梯度稳定性,而LoRA-GA则通过梯度对齐加速收敛。通过动态地调整两种方法的权重,可以实现更高效和稳定的微调。
技术框架:该方法首先对LLM进行初始化,然后使用LoRA、BOFT、LoRA-GA和uRNN等PEFT方法进行微调。关键在于提出的混合策略,它根据每层的梯度范数动态地调整BOFT和LoRA-GA的权重。具体来说,梯度范数较大的层更倾向于使用LoRA-GA,以加速收敛;梯度范数较小的层更倾向于使用BOFT,以保证梯度稳定性。此外,论文还探索了将uRNN的酉约束应用于Transformer,以进一步增强梯度稳定性。
关键创新:最重要的技术创新点在于提出的混合PEFT策略,它能够根据每层的梯度信息自适应地调整不同PEFT方法的权重,从而在收敛速度、梯度稳定性和最终性能之间取得更好的平衡。与现有方法相比,该方法能够更有效地利用计算资源,并在更短的时间内达到更高的性能。此外,首次将uRNN的酉约束应用于Transformer也是一个创新点。
关键设计:混合策略的关键在于如何根据梯度范数动态地调整BOFT和LoRA-GA的权重。具体来说,可以使用以下公式:weight = sigmoid(alpha * gradient_norm),其中alpha是一个超参数,用于控制权重调整的灵敏度。损失函数可以使用标准的交叉熵损失函数,并添加一个正则化项来约束BOFT的正交性。对于uRNN,可以使用Cayley变换来参数化酉矩阵。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该混合方法在GLUE、GSM8K、MT-Bench和HumanEval等多个任务上均取得了显著的性能提升,接近完全微调的水平,同时将训练时间减少约2.1倍,峰值内存使用量减少近50%。在低资源场景下,使用32个样本进行微调,也取得了显著的性能提升,证明了该方法在资源受限环境下的有效性。
🎯 应用场景
该研究成果可广泛应用于各种需要对大规模语言模型进行微调的场景,例如自然语言处理、机器翻译、文本生成等。特别是在资源受限的环境下,该方法能够以较低的计算成本实现高性能的微调,具有重要的实际应用价值。未来,该方法有望进一步推广到其他类型的深度学习模型和任务中。
📄 摘要(原文)
Fine-tuning large language models (LLMs) remains a computational bottleneck due to their scale and memory demands. This paper presents a comprehensive evaluation of parameter-efficient fine-tuning (PEFT) techniques, including LoRA, BOFT, LoRA-GA, and uRNN, and introduces a novel hybrid strategy that dynamically integrates BOFT's orthogonal stability with LoRA-GA's gradient-aligned rapid convergence. By computing per-layer adaptive updates guided by gradient norms, the hybrid method achieves superior convergence efficiency and generalization across diverse tasks. We also explore, for the first time, the adaptation of unitary RNN (uRNN) principles to Transformer-based LLMs, enhancing gradient stability through structured unitary constraints. Across GLUE, GSM8K, MT-Bench, and HumanEval, using models ranging from 7B to 405B parameters, the hybrid approach yields consistent gains across three independent runs per task and model, approaching the quality of full fine-tuning while reducing training time by approximately 2.1 times and peak memory usage by nearly 50 percent, indicating practical significance under resource constraints. A compact multilingual and low-resource study on XNLI and FLORES, using 32 examples per language, further demonstrates consistent gains under the same budget with a small and stable footprint. These results indicate a practical and scalable path toward accessible LLM fine-tuning under resource constraints.