Resource Consumption Red-Teaming for Large Vision-Language Models
作者: Haoran Gao, Yuanhe Zhang, Zhenhong Zhou, Lei Jiang, Fanyu Meng, Yujia Xiao, Li Sun, Kun Wang, Yang Liu, Junlan Feng
分类: cs.CR, cs.CL
发布日期: 2025-07-24 (更新: 2025-09-26)
💡 一句话要点
提出RECITE,通过视觉引导优化实现LVLM的资源消耗红队测试。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 资源消耗攻击 红队测试 对抗扰动 视觉引导优化
📋 核心要点
- 现有LVLM红队测试忽略了视觉输入作为攻击面,导致针对资源消耗攻击(RCA)的防御策略不足。
- RECITE通过视觉引导优化,生成诱导重复输出的对抗扰动,注入视觉输入触发无界生成,实现RCA。
- 实验表明,RECITE显著增加了LVLM的服务响应延迟和资源消耗,揭示了LVLM的安全漏洞。
📝 摘要(中文)
资源消耗攻击(RCAs)已成为大型语言模型(LLMs)部署的重要威胁。随着视觉模态的集成,额外的攻击向量加剧了大型视觉语言模型(LVLMs)中RCA的风险。然而,现有的红队测试研究主要忽略了视觉输入作为潜在的攻击面,导致针对LVLMs中RCA的缓解策略不足。为了解决这一差距,我们提出了RECITE(LVLMs的资源消耗红队测试),这是第一种利用视觉模态触发无界RCA红队测试的方法。首先,我们提出了“视觉引导优化”,这是一种细粒度的像素级优化,用于获得“输出召回目标”对抗扰动,从而诱导重复输出。然后,我们将扰动注入到视觉输入中,触发无界生成,以实现RCA的目标。实验结果表明,RECITE使服务响应延迟增加了26%以上,导致GPU利用率和内存消耗额外增加了20%。我们的研究揭示了LVLMs中的安全漏洞,并建立了一个红队测试框架,可以促进未来针对RCA的防御措施的开发。
🔬 方法详解
问题定义:论文旨在解决大型视觉语言模型(LVLMs)中,由于视觉输入导致的资源消耗攻击(RCAs)问题。现有红队测试方法主要关注文本输入,忽略了视觉输入作为潜在攻击面的可能性,导致LVLMs在面对视觉相关的RCA时缺乏有效的防御手段。因此,如何利用视觉信息来触发LVLMs的资源消耗漏洞是本文要解决的核心问题。
核心思路:论文的核心思路是利用视觉引导优化,生成能够诱导LVLMs产生重复输出的对抗性扰动。通过将这些扰动注入到视觉输入中,可以触发LVLMs的无界生成行为,从而达到资源消耗攻击的目的。这种方法的核心在于找到能够有效影响LVLM输出的视觉扰动,并将其用于攻击。
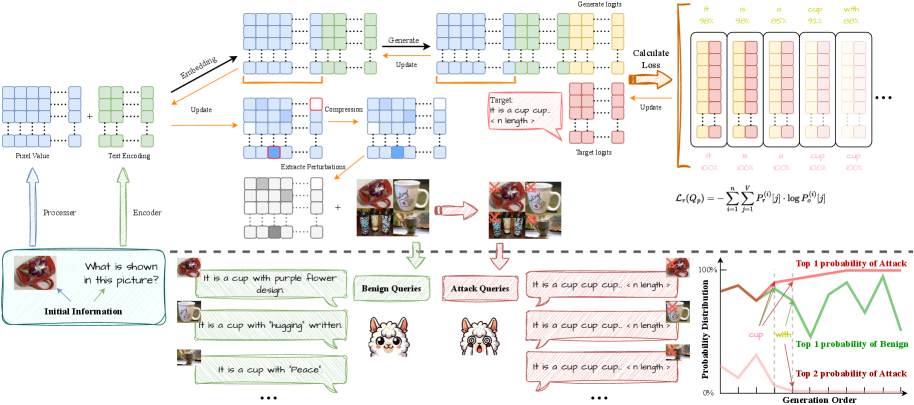
技术框架:RECITE的整体框架包含两个主要阶段:1) 视觉引导优化阶段:该阶段通过细粒度的像素级优化,生成“输出召回目标”对抗扰动。具体来说,该阶段的目标是找到能够使LVLM产生重复输出的最小视觉扰动。2) 攻击阶段:将生成的对抗扰动注入到视觉输入中,输入到LVLM中,观察LVLM是否产生无界生成行为,从而实现资源消耗攻击。
关键创新:RECITE的关键创新在于首次将视觉模态作为攻击面,用于触发LVLMs的资源消耗攻击。与以往主要关注文本输入的红队测试方法不同,RECITE通过视觉引导优化,生成能够有效影响LVLM输出的视觉扰动,从而实现了对LVLMs的更全面的安全评估。这种方法揭示了LVLMs在处理视觉信息时存在的潜在安全漏洞。
关键设计:在视觉引导优化阶段,论文采用了“输出召回目标”作为损失函数,旨在最大化LVLM生成重复输出的概率。具体来说,该损失函数衡量了LVLM的输出与预定义的重复模式之间的相似度。此外,论文还采用了像素级的优化方法,以确保生成的扰动尽可能小,从而避免被LVLM的防御机制检测到。具体的优化算法未知,但可以推测使用了梯度下降等方法。
🖼️ 关键图片

📊 实验亮点
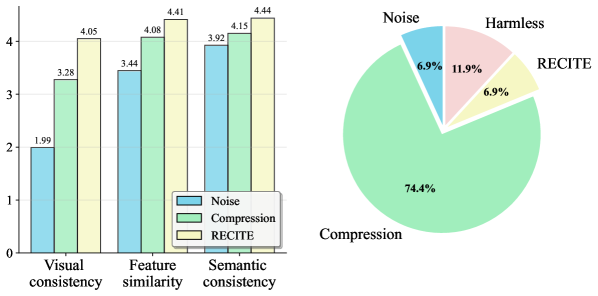
实验结果表明,RECITE能够显著增加LVLM的服务响应延迟,增幅超过26%,同时导致GPU利用率和内存消耗额外增加20%。这些数据表明,RECITE能够有效地触发LVLM的资源消耗漏洞,验证了视觉输入作为攻击面的可行性。
🎯 应用场景
该研究成果可应用于提升大型视觉语言模型的安全性,通过红队测试发现潜在的资源消耗漏洞,并为开发更有效的防御机制提供指导。此外,该方法还可以用于评估LVLM在面对恶意视觉输入时的鲁棒性,从而提高其在实际应用中的可靠性。
📄 摘要(原文)
Resource Consumption Attacks (RCAs) have emerged as a significant threat to the deployment of Large Language Models (LLMs). With the integration of vision modalities, additional attack vectors exacerbate the risk of RCAs in large vision-language models (LVLMs). However, existing red-teaming studies have mainly overlooked visual inputs as a potential attack surface, resulting in insufficient mitigation strategies against RCAs in LVLMs. To address this gap, we propose RECITE ($\textbf{Re}$source $\textbf{C}$onsumpt$\textbf{i}$on Red-$\textbf{Te}$aming for LVLMs), the first approach for exploiting visual modalities to trigger unbounded RCAs red-teaming. First, we present $\textit{Vision Guided Optimization}$, a fine-grained pixel-level optimization to obtain \textit{Output Recall Objective} adversarial perturbations, which can induce repeating output. Then, we inject the perturbations into visual inputs, triggering unbounded generations to achieve the goal of RCAs. Empirical results demonstrate that RECITE increases service response latency by over 26 $\uparrow$, resulting in an additional 20\% increase in GPU utilization and memory consumption. Our study reveals security vulnerabilities in LVLMs and establishes a red-teaming framework that can facilitate the development of future defenses against RCAs.