Synthetic Data Generation for Phrase Break Prediction with Large Language Model
作者: Hoyeon Lee, Sejung Son, Ye-Eun Kang, Jong-Hwan Kim
分类: cs.CL, cs.AI
发布日期: 2025-07-24
备注: Accepted at Interspeech 2025
💡 一句话要点
利用大型语言模型生成合成数据,解决短语停顿预测的数据标注难题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 短语停顿预测 大型语言模型 合成数据生成 文本到语音 数据增强
📋 核心要点
- 短语停顿预测依赖大量人工标注,成本高昂,且语音数据的可变性增加了获取高质量数据的难度。
- 利用大型语言模型生成合成短语停顿标注数据,旨在减少人工标注需求,降低成本并提高数据质量。
- 实验结果表明,LLM生成的合成数据能有效解决短语停顿预测的数据挑战,具有实际应用潜力。
📝 摘要(中文)
现有的短语停顿预测方法对于文本到语音系统至关重要,但严重依赖于来自音频或文本的大量人工标注,导致显著的人工成本。语音领域中由语音因素驱动的固有可变性,进一步复杂化了获取一致、高质量数据的过程。最近,大型语言模型(LLMs)在NLP领域通过生成定制的合成数据同时减少人工标注需求,成功应对了数据挑战。受此启发,我们探索利用LLM生成合成的短语停顿标注,通过与传统标注进行比较并评估其在多种语言中的有效性,来解决人工标注和语音相关任务的挑战。我们的研究结果表明,基于LLM的合成数据生成有效地缓解了短语停顿预测中的数据挑战,并突出了LLM作为语音领域可行解决方案的潜力。
🔬 方法详解
问题定义:论文旨在解决短语停顿预测任务中数据标注成本高昂且质量难以保证的问题。现有方法依赖大量人工标注,耗时费力,并且语音数据本身的复杂性使得标注一致性难以控制。因此,如何降低人工标注成本,同时保证数据质量,是该论文要解决的核心问题。
核心思路:论文的核心思路是利用大型语言模型(LLMs)强大的生成能力,自动生成带有短语停顿标注的合成数据。通过使用LLM,可以避免大量的人工标注工作,并且LLM能够学习到语言的内在规律,从而生成高质量的标注数据。这种方法旨在降低成本,提高效率,并解决语音数据可变性带来的挑战。
技术框架:整体框架包括以下几个主要步骤:1) 选择合适的LLM模型;2) 设计合适的prompt,引导LLM生成带有短语停顿标注的文本数据;3) 对生成的合成数据进行质量评估和筛选;4) 将合成数据与少量人工标注数据结合,训练短语停顿预测模型;5) 在真实数据集上评估模型的性能。
关键创新:该论文的关键创新在于将大型语言模型应用于短语停顿预测的合成数据生成。与传统的人工标注方法相比,该方法能够显著降低标注成本,并提高数据生成效率。此外,利用LLM的语言理解能力,可以生成更符合语言规律的标注数据,从而提高模型的性能。
关键设计:论文的关键设计包括:1) Prompt的设计,需要精心设计prompt,以引导LLM生成高质量的短语停顿标注数据。Prompt需要包含清晰的指令和示例,以确保LLM能够理解任务要求;2) 数据质量评估,需要设计合适的指标来评估合成数据的质量,例如标注一致性、语言流畅度等。可以使用人工评估或自动评估方法;3) 模型训练策略,需要研究如何将合成数据与人工标注数据结合,以获得最佳的训练效果。可以采用不同的数据增强方法或迁移学习策略。
🖼️ 关键图片


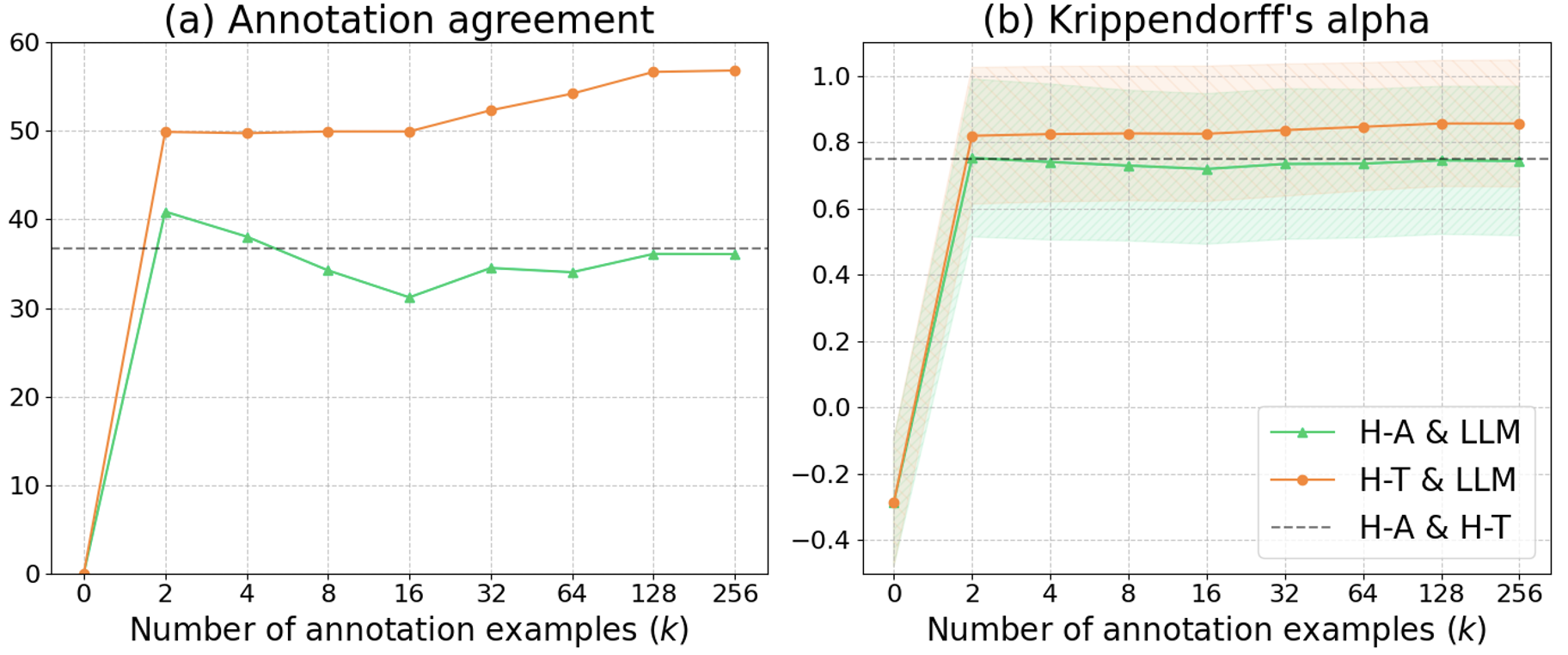
📊 实验亮点
该研究表明,基于LLM生成的合成数据在短语停顿预测任务中表现出良好的性能,能够有效缓解数据标注的难题。通过与传统标注方法进行比较,验证了LLM生成数据的有效性。实验结果表明,使用LLM合成数据训练的模型在多种语言上都取得了显著的性能提升,证明了该方法的跨语言适用性。
🎯 应用场景
该研究成果可广泛应用于文本到语音(TTS)系统、语音识别、语音合成等领域。通过降低短语停顿预测的数据标注成本,可以加速相关技术的研发和应用,提升语音交互的自然度和流畅性。此外,该方法还可以推广到其他语音相关的任务中,例如情感识别、语音翻译等,具有广阔的应用前景。
📄 摘要(原文)
Current approaches to phrase break prediction address crucial prosodic aspects of text-to-speech systems but heavily rely on vast human annotations from audio or text, incurring significant manual effort and cost. Inherent variability in the speech domain, driven by phonetic factors, further complicates acquiring consistent, high-quality data. Recently, large language models (LLMs) have shown success in addressing data challenges in NLP by generating tailored synthetic data while reducing manual annotation needs. Motivated by this, we explore leveraging LLM to generate synthetic phrase break annotations, addressing the challenges of both manual annotation and speech-related tasks by comparing with traditional annotations and assessing effectiveness across multiple languages. Our findings suggest that LLM-based synthetic data generation effectively mitigates data challenges in phrase break prediction and highlights the potential of LLMs as a viable solution for the speech domain.