Towards Greater Leverage: Scaling Laws for Efficient Mixture-of-Experts Language Models
作者: Changxin Tian, Kunlong Chen, Jia Liu, Ziqi Liu, Zhiqiang Zhang, Jun Zhou
分类: cs.CL
发布日期: 2025-07-23 (更新: 2025-10-21)
💡 一句话要点
提出效率杠杆(EL)指标,揭示MoE模型高效扩展的缩放规律
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 混合专家模型 MoE 缩放规律 效率杠杆 大型语言模型
📋 核心要点
- 现有MoE模型缺乏有效的模型容量预测方法,难以根据配置选择最优模型。
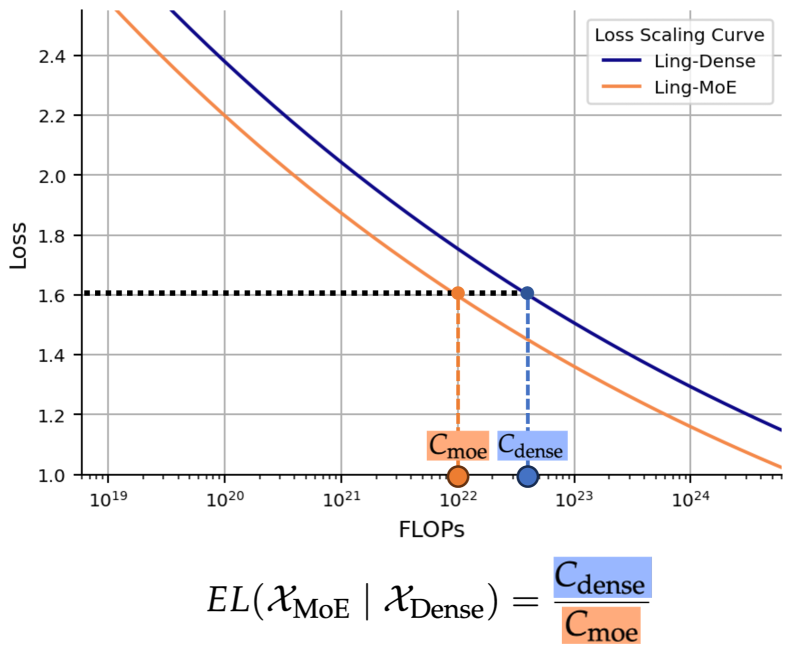
- 提出效率杠杆(EL)指标,量化MoE模型相对于稠密模型的计算优势,指导模型设计。
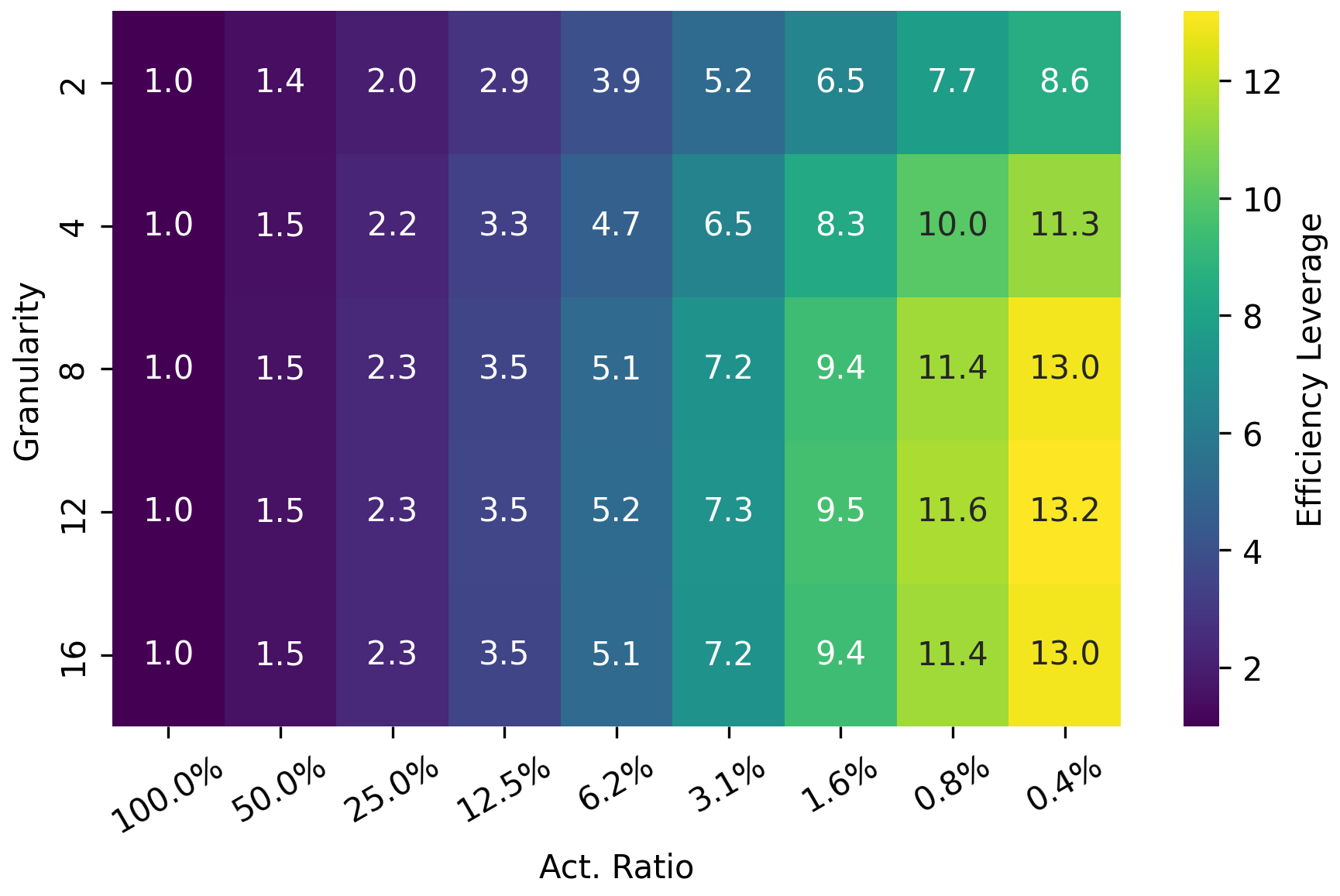
- 通过大规模实验,揭示了专家激活率、计算预算和专家粒度对EL的影响规律,并验证了有效性。
📝 摘要(中文)
混合专家模型(MoE)已成为高效扩展大型语言模型(LLM)的主流架构,它将总参数与计算成本解耦。然而,这种解耦带来了一个关键挑战:预测给定MoE配置(例如,专家激活率和粒度)的模型容量仍然是一个未解决的问题。为了弥补这一差距,我们引入了效率杠杆(EL),这是一个量化MoE模型相对于等效稠密模型的计算优势的指标。我们进行了一项大规模的实证研究,训练了超过300个模型,参数高达280亿,以系统地研究MoE架构配置与EL之间的关系。我们的研究结果表明,EL主要由专家激活率和总计算预算驱动,两者都遵循可预测的幂律,而专家粒度则充当具有明确最佳范围的非线性调节器。我们将这些发现整合到一个统一的缩放规律中,该规律可以根据MoE架构的配置准确预测其EL。为了验证我们推导出的缩放规律,我们设计并训练了Ling-mini-beta,这是Ling-2.0系列的试点模型,只有0.85B的激活参数,同时还有一个6.1B的稠密模型用于比较。当在相同的1T高质量token数据集上训练时,Ling-mini-beta匹配了6.1B稠密模型的性能,同时消耗了7倍以上的计算资源,从而证实了我们的缩放规律的准确性。这项工作为高效MoE模型的扩展提供了一个有原则的和基于经验的基础。
🔬 方法详解
问题定义:现有混合专家模型(MoE)在扩展大型语言模型时面临一个关键问题:如何准确预测给定MoE配置(如专家激活率和粒度)下的模型容量。现有方法缺乏有效的指标来衡量MoE模型的计算效率,导致难以选择最优的MoE架构,从而限制了MoE模型的应用和发展。
核心思路:论文的核心思路是引入“效率杠杆”(Efficiency Leverage, EL)这一指标,用于量化MoE模型相对于等效稠密模型的计算优势。通过分析EL与MoE架构配置之间的关系,建立可预测的缩放规律,从而指导MoE模型的设计和扩展。这种方法旨在解决MoE模型容量预测的难题,提高计算效率。
技术框架:该研究的技术框架主要包括以下几个阶段:1) 定义效率杠杆(EL)指标;2) 进行大规模实证研究,训练大量不同配置的MoE模型;3) 分析实验数据,揭示专家激活率、计算预算和专家粒度对EL的影响规律;4) 将这些规律整合为一个统一的缩放规律,用于预测MoE架构的EL;5) 设计并训练小型MoE模型Ling-mini-beta,验证缩放规律的准确性。
关键创新:该论文最重要的技术创新点在于提出了效率杠杆(EL)这一指标,并揭示了EL与MoE架构配置之间的缩放规律。与现有方法相比,EL提供了一种量化MoE模型计算效率的手段,使得可以根据计算预算和性能需求选择合适的MoE架构。此外,该研究还发现了专家粒度对EL的非线性影响,为MoE模型的设计提供了新的视角。
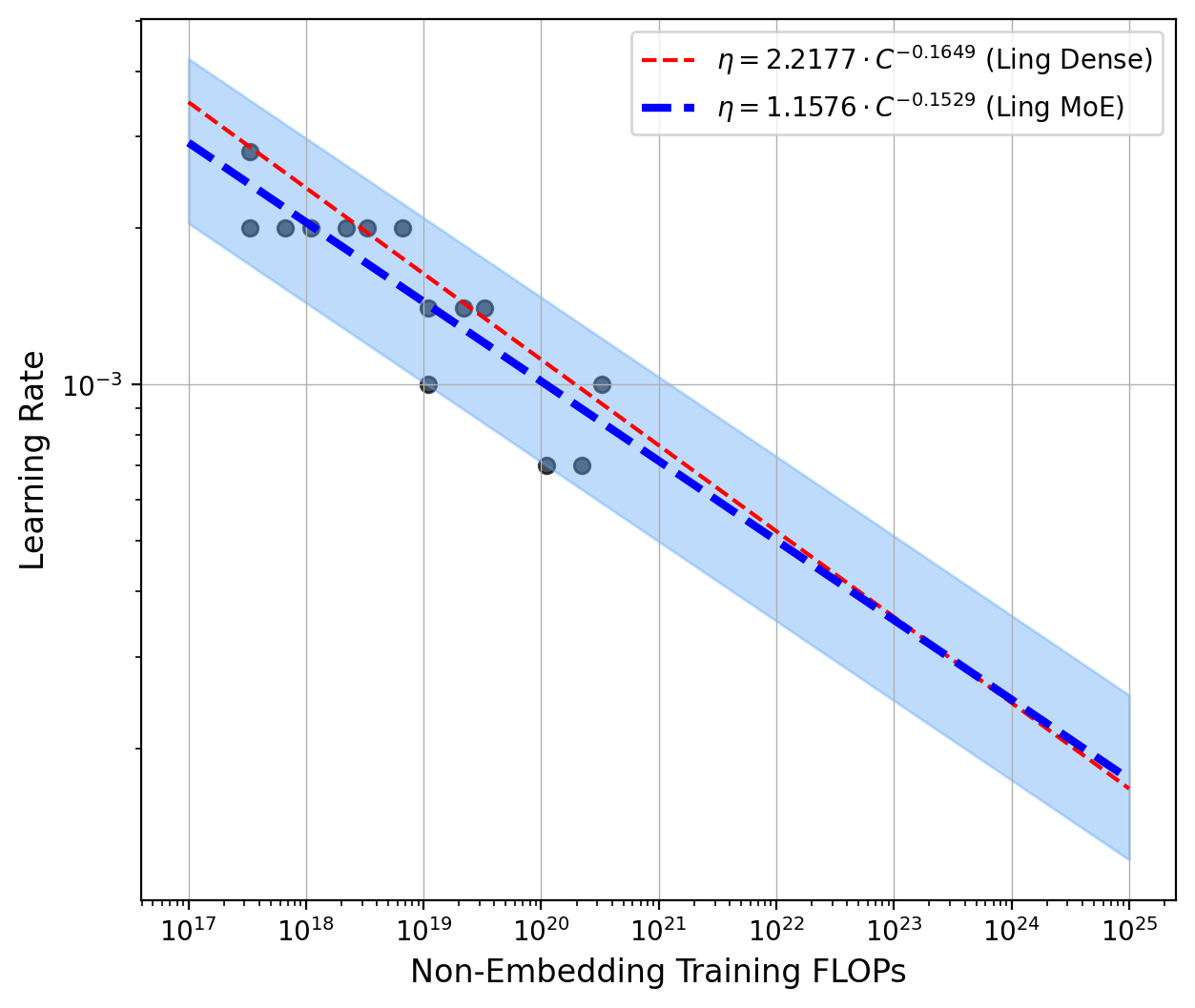
关键设计:在实验设计方面,论文训练了超过300个模型,参数高达280亿,覆盖了不同的专家激活率和粒度。在模型训练方面,使用了高质量的1T token数据集。在验证缩放规律方面,设计了Ling-mini-beta模型,并与6.1B的稠密模型进行了对比。关键参数包括专家数量、专家容量、激活函数类型等。损失函数使用了标准的交叉熵损失函数。
🖼️ 关键图片
📊 实验亮点
实验结果表明,Ling-mini-beta(0.85B激活参数)在相同的1T高质量token数据集上训练后,能够匹配6.1B稠密模型的性能,同时消耗的计算资源减少了7倍以上。这充分验证了论文提出的效率杠杆(EL)指标和缩放规律的准确性,证明了MoE模型在高效扩展大型语言模型方面的潜力。
🎯 应用场景
该研究成果可应用于大规模语言模型的训练和部署,尤其是在计算资源受限的场景下。通过利用效率杠杆(EL)指标和缩放规律,可以设计出在相同计算预算下性能更优的MoE模型,降低训练成本,提高模型推理效率。此外,该研究还可以指导硬件加速器的设计,以更好地支持MoE模型的计算。
📄 摘要(原文)
Mixture-of-Experts (MoE) has become a dominant architecture for scaling Large Language Models (LLMs) efficiently by decoupling total parameters from computational cost. However, this decoupling creates a critical challenge: predicting the model capacity of a given MoE configurations (e.g., expert activation ratio and granularity) remains an unresolved problem. To address this gap, we introduce Efficiency Leverage (EL), a metric quantifying the computational advantage of an MoE model over a dense equivalent. We conduct a large-scale empirical study, training over 300 models up to 28B parameters, to systematically investigate the relationship between MoE architectural configurations and EL. Our findings reveal that EL is primarily driven by the expert activation ratio and the total compute budget, both following predictable power laws, while expert granularity acts as a non-linear modulator with a clear optimal range. We integrate these discoveries into a unified scaling law that accurately predicts the EL of an MoE architecture based on its configuration. To validate our derived scaling laws, we designed and trained Ling-mini-beta, a pilot model for Ling-2.0 series with only 0.85B active parameters, alongside a 6.1B dense model for comparison. When trained on an identical 1T high-quality token dataset, Ling-mini-beta matched the performance of the 6.1B dense model while consuming over 7x fewer computational resources, thereby confirming the accuracy of our scaling laws. This work provides a principled and empirically-grounded foundation for the scaling of efficient MoE models.