SKA-Bench: A Fine-Grained Benchmark for Evaluating Structured Knowledge Understanding of LLMs
作者: Zhiqiang Liu, Enpei Niu, Yin Hua, Mengshu Sun, Lei Liang, Huajun Chen, Wen Zhang
分类: cs.CL, cs.AI
发布日期: 2025-07-23 (更新: 2025-08-29)
备注: EMNLP 2025
🔗 代码/项目: GITHUB
💡 一句话要点
SKA-Bench:用于评估LLM结构化知识理解能力的细粒度基准测试
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 结构化知识 大型语言模型 基准测试 知识图谱 表格问答 噪声鲁棒性 信息整合
📋 核心要点
- 现有LLM在结构化知识理解方面评估不足,缺乏对特定能力的细粒度评估,且多集中于单一知识形式。
- SKA-Bench通过构建包含多种结构化知识形式的问答基准,并设计噪声、顺序等测试,来诊断LLM的结构化知识理解能力。
- 实验结果表明,现有LLM在结构化知识理解方面仍面临挑战,性能受噪声、知识单元顺序和幻觉等因素影响。
📝 摘要(中文)
大型语言模型(LLM)在理解结构化知识(SK),如知识图谱(KG)和表格方面取得了显著进展。然而,现有的SK理解评估不够严谨(即缺乏对特定能力的评估),并且侧重于单一类型的SK。因此,本文旨在提出一个更全面和严谨的结构化知识理解基准,以诊断LLM的不足。本文介绍了SKA-Bench,一个结构化知识增强的问答基准,它包含四种广泛使用的结构化知识形式:KG、表格、KG+文本和表格+文本。我们使用一个三阶段的流程来构建SKA-Bench实例,其中包括问题、答案、正向知识单元和噪声知识单元。为了细粒度地评估LLM的SK理解能力,我们将实例扩展到四个基本能力测试平台:噪声鲁棒性、顺序不敏感性、信息整合和负例拒绝。对包括先进的DeepSeek-R1在内的8个代表性LLM的实证评估表明,现有的LLM在理解结构化知识方面仍然面临重大挑战,并且它们的性能受到噪声量、知识单元的顺序和幻觉现象等因素的影响。我们的数据集和代码可在https://github.com/zjukg/SKA-Bench上找到。
🔬 方法详解
问题定义:现有的大型语言模型在理解结构化知识(如知识图谱和表格)方面取得了进展,但现有的评估方法存在局限性。这些评估通常不够严谨,缺乏对特定能力的细粒度评估,并且往往只关注单一类型的结构化知识。这使得我们难以全面了解LLM在处理不同类型的结构化知识时的优势和不足。
核心思路:SKA-Bench的核心思路是构建一个更全面、更严谨的结构化知识理解基准,以诊断LLM的不足。它通过包含多种结构化知识形式(KG、表格、KG+文本、表格+文本)的问答实例,并设计针对噪声鲁棒性、顺序不敏感性、信息整合和负例拒绝等能力的测试,来更细粒度地评估LLM的结构化知识理解能力。
技术框架:SKA-Bench的构建包含一个三阶段的流程:1. 数据收集与清洗:收集各种结构化知识数据,并进行清洗和预处理。2. 实例生成:基于收集到的数据,生成包含问题、答案、正向知识单元和噪声知识单元的问答实例。3. 能力测试扩展:将生成的实例扩展到四个基本能力测试平台(噪声鲁棒性、顺序不敏感性、信息整合和负例拒绝)。
关键创新:SKA-Bench的关键创新在于其细粒度的评估方法和对多种结构化知识形式的支持。它不仅考虑了不同类型的结构化知识,还设计了针对特定能力的测试,从而能够更全面地评估LLM的结构化知识理解能力。此外,SKA-Bench还引入了噪声知识单元,以评估LLM的噪声鲁棒性。
关键设计:SKA-Bench的关键设计包括:1. 多种结构化知识形式的支持:涵盖KG、表格、KG+文本和表格+文本四种常见的结构化知识形式。2. 噪声知识单元的引入:通过引入噪声知识单元,评估LLM在存在噪声干扰的情况下,能否正确理解结构化知识。3. 四个基本能力测试平台的设计:针对噪声鲁棒性、顺序不敏感性、信息整合和负例拒绝等能力,设计了相应的测试用例。
🖼️ 关键图片
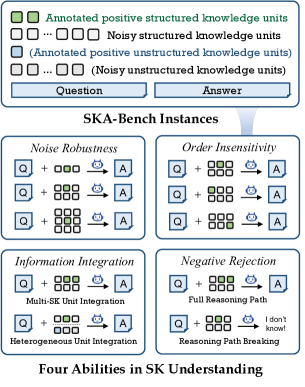
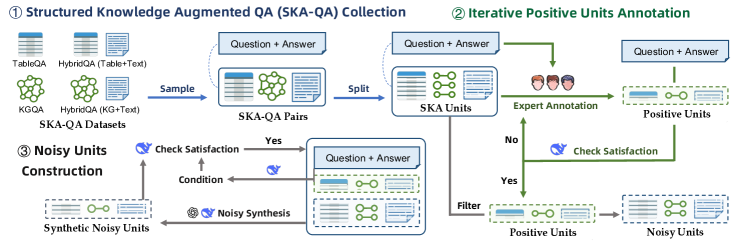

📊 实验亮点
在8个代表性LLM上的实验结果表明,现有LLM在理解结构化知识方面仍面临挑战。例如,模型性能受到噪声量、知识单元顺序和幻觉现象的影响。DeepSeek-R1等先进模型在某些测试中表现较好,但在其他测试中仍存在不足,表明结构化知识理解仍有提升空间。
🎯 应用场景
SKA-Bench可用于评估和提升LLM在知识图谱问答、表格问答、智能搜索、推荐系统等领域的应用性能。通过诊断LLM在结构化知识理解方面的不足,可以指导模型改进和优化,从而提高LLM在实际应用中的准确性和可靠性,并促进相关技术的进步。
📄 摘要(原文)
Although large language models (LLMs) have made significant progress in understanding Structured Knowledge (SK) like KG and Table, existing evaluations for SK understanding are non-rigorous (i.e., lacking evaluations of specific capabilities) and focus on a single type of SK. Therefore, we aim to propose a more comprehensive and rigorous structured knowledge understanding benchmark to diagnose the shortcomings of LLMs. In this paper, we introduce SKA-Bench, a Structured Knowledge Augmented QA Benchmark that encompasses four widely used structured knowledge forms: KG, Table, KG+Text, and Table+Text. We utilize a three-stage pipeline to construct SKA-Bench instances, which includes a question, an answer, positive knowledge units, and noisy knowledge units. To evaluate the SK understanding capabilities of LLMs in a fine-grained manner, we expand the instances into four fundamental ability testbeds: Noise Robustness, Order Insensitivity, Information Integration, and Negative Rejection. Empirical evaluations on 8 representative LLMs, including the advanced DeepSeek-R1, indicate that existing LLMs still face significant challenges in understanding structured knowledge, and their performance is influenced by factors such as the amount of noise, the order of knowledge units, and hallucination phenomenon. Our dataset and code are available at https://github.com/zjukg/SKA-Bench.