Pixels to Principles: Probing Intuitive Physics Understanding in Multimodal Language Models
作者: Mohamad Ballout, Serwan Jassim, Elia Bruni
分类: cs.CL
发布日期: 2025-07-22
💡 一句话要点
评估多模态大语言模型在直觉物理任务中的理解能力,揭示视觉-语言对齐问题。
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 直觉物理 视觉-语言对齐 模型可解释性 探测分析
📋 核心要点
- 现有MLLM在直觉物理任务中表现不佳,无法可靠区分物理合理与不合理的场景。
- 通过探测模型中间层表示,分析视觉信息是否有效传递到语言模型,揭示潜在的视觉-语言不对齐问题。
- 实验表明,视觉编码器能捕获物理线索,但语言模型未能有效利用,视觉-语言对齐是性能瓶颈。
📝 摘要(中文)
本文系统性地评估了最先进的多模态大语言模型(MLLMs)在直觉物理任务上的表现,使用了GRASP和IntPhys 2数据集。评估了开源模型InternVL 2.5、Qwen 2.5 VL、LLaVA-OneVision以及闭源模型Gemini 2.0 Flash Thinking,发现即使是最新的模型也难以可靠地区分物理上合理与不合理的场景。为了超越性能指标,本文对模型嵌入进行了探测分析,提取关键处理阶段的中间表示,以检查任务相关信息是否得到良好保留。结果表明,根据任务难度,可能会出现关键的视觉-语言不对齐:视觉编码器成功捕获了物理合理性线索,但语言模型未能有效利用这些信息,导致推理失败。这种不对齐表明,MLLMs在直觉物理任务中的主要限制不是视觉组件,而是视觉和语言信息的无效集成。研究结果强调了视觉-语言对齐是未来MLLMs开发的关键改进领域,并为未来的MLLMs发展提供了见解。
🔬 方法详解
问题定义:论文旨在评估多模态大语言模型(MLLMs)在理解直觉物理方面的能力。现有方法,即直接使用MLLMs进行预测,在区分物理上合理与不合理的场景时表现不佳,缺乏对模型内部信息处理过程的深入理解,无法确定性能瓶颈所在。
核心思路:论文的核心思路是通过探测分析(probing analysis)模型内部的中间层表示,来研究视觉信息在模型中的传递和利用情况。具体来说,就是提取视觉编码器和语言模型在关键处理阶段的嵌入向量,分析这些向量是否包含任务相关的物理信息,以及这些信息是否有效地从视觉模块传递到语言模块。
技术框架:整体框架包括:1)使用GRASP和IntPhys 2数据集作为评估基准;2)选择InternVL 2.5、Qwen 2.5 VL、LLaVA-OneVision和Gemini 2.0 Flash Thinking等MLLMs作为研究对象;3)提取模型在关键处理阶段的中间层表示(例如,视觉编码器的输出、语言模型的输入等);4)使用线性分类器等方法,分析这些中间层表示是否包含物理合理性信息;5)比较视觉编码器和语言模型的信息保留程度,从而判断是否存在视觉-语言不对齐。
关键创新:论文最重要的创新点在于,它不仅仅关注MLLMs在直觉物理任务上的整体性能,而是深入分析了模型内部的信息处理过程,揭示了视觉-语言不对齐是导致性能瓶颈的关键因素。与以往的研究相比,本文更加注重对模型内部机制的理解,为改进MLLMs的设计提供了新的思路。
关键设计:论文的关键设计包括:1)选择合适的中间层表示进行分析,例如视觉编码器的输出和语言模型的输入;2)使用线性分类器作为探测工具,评估中间层表示中包含的物理信息量;3)设计合理的实验方案,比较不同模型和不同任务难度下的视觉-语言对齐程度。具体参数设置和网络结构取决于所使用的MLLMs,论文侧重于分析框架而非特定模型架构。
🖼️ 关键图片
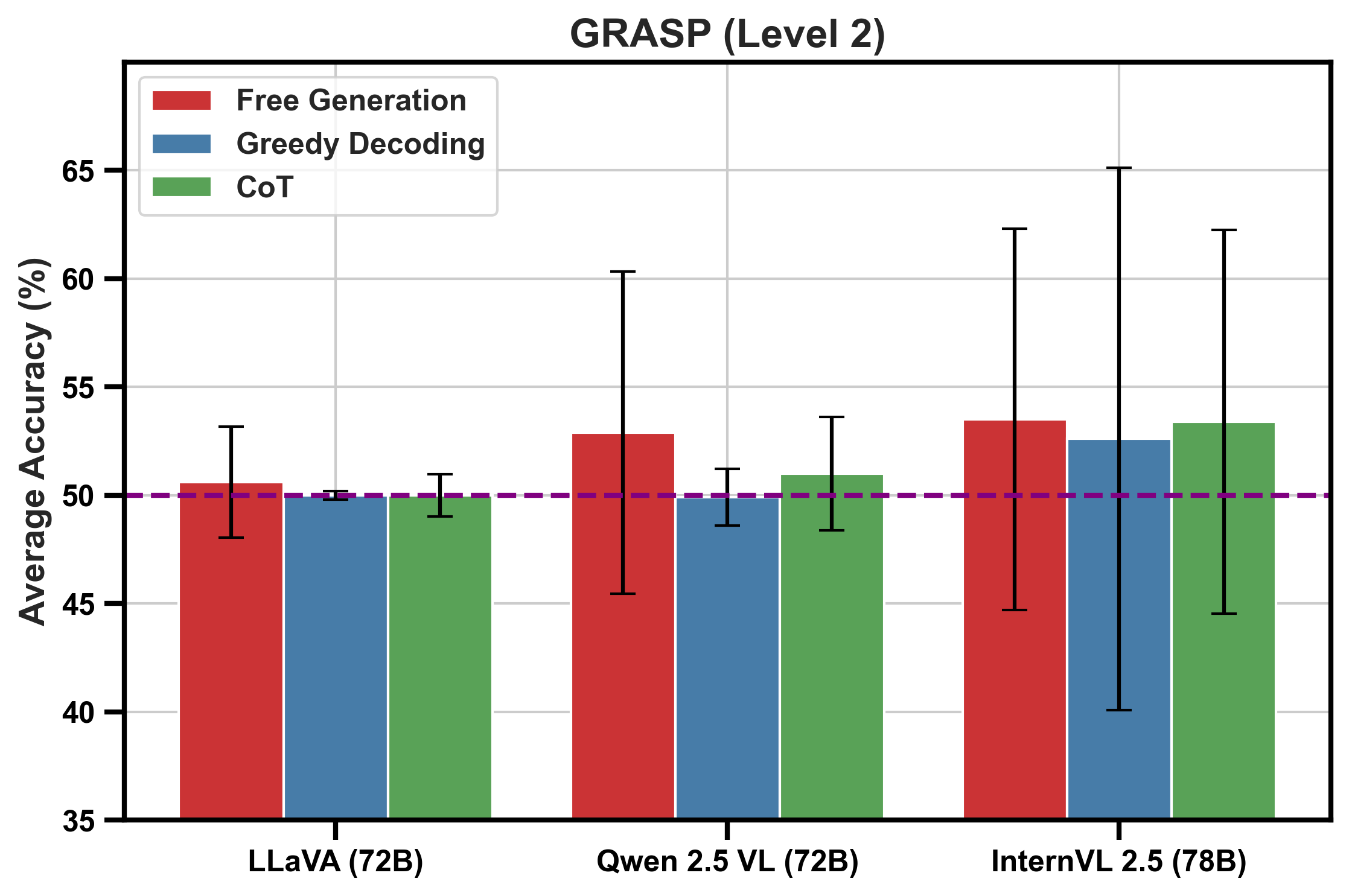

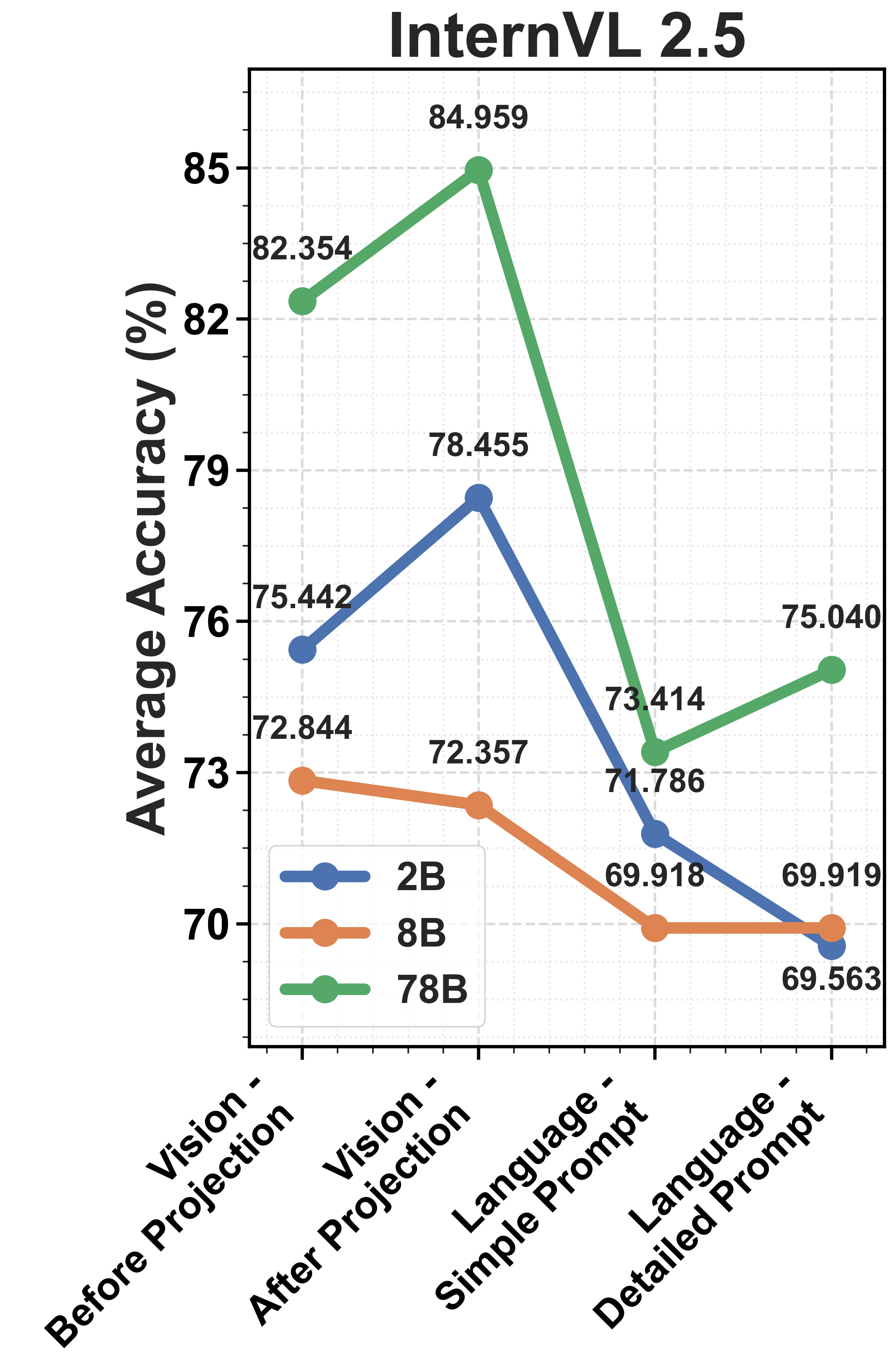
📊 实验亮点
实验结果表明,即使是最先进的MLLMs在直觉物理任务中也表现不佳,无法可靠区分物理上合理与不合理的场景。探测分析揭示,视觉编码器能够有效捕获物理线索,但这些信息未能有效传递到语言模型,导致推理失败。这表明视觉-语言对齐是MLLMs在该任务中的主要瓶颈。
🎯 应用场景
该研究成果可应用于提升机器人、自动驾驶等领域中AI系统的环境感知和推理能力,使其能够更好地理解和预测物理世界的行为。通过改进视觉-语言对齐,可以提高AI系统在复杂环境中的决策能力和安全性,例如在未知环境中导航或操作物体。
📄 摘要(原文)
This paper presents a systematic evaluation of state-of-the-art multimodal large language models (MLLMs) on intuitive physics tasks using the GRASP and IntPhys 2 datasets. We assess the open-source models InternVL 2.5, Qwen 2.5 VL, LLaVA-OneVision, and the proprietary Gemini 2.0 Flash Thinking, finding that even the latest models struggle to reliably distinguish physically plausible from implausible scenarios. To go beyond performance metrics, we conduct a probing analysis of model embeddings, extracting intermediate representations at key processing stages to examine how well task-relevant information is preserved. Our results show that, depending on task difficulty, a critical vision-language misalignment can emerge: vision encoders successfully capture physical plausibility cues, but this information is not effectively utilized by the language model, leading to failures in reasoning. This misalignment suggests that the primary limitation of MLLMs in intuitive physics tasks is not the vision component but the ineffective integration of visual and linguistic information. Our findings highlight vision-language alignment as a key area for improvement, offering insights for future MLLMs development.