The Ever-Evolving Science Exam
作者: Junying Wang, Zicheng Zhang, Yijin Guo, Farong Wen, Ye Shen, Yingji Liang, Yalun Wu, Wenzhe Li, Chunyi Li, Zijian Chen, Qi Jia, Guangtao Zhai
分类: cs.CL, cs.AI
发布日期: 2025-07-22 (更新: 2025-09-30)
备注: 33 pages
🔗 代码/项目: GITHUB
💡 一句话要点
提出EESE:一个动态演进的科学考试基准,用于可靠评估基础模型的科学理解能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 科学基准 基础模型 数据泄露 动态评估 科学理解
📋 核心要点
- 现有科学基准测试存在数据泄露风险,影响评估的有效性,并且大规模测试导致评估效率低下。
- EESE通过构建包含大量科学实例的题库,并定期更新评估子集,实现防泄露和低开销的科学能力评估。
- 实验表明,EESE能够有效区分不同模型在科学领域和认知维度上的优劣,提供更可靠的评估结果。
📝 摘要(中文)
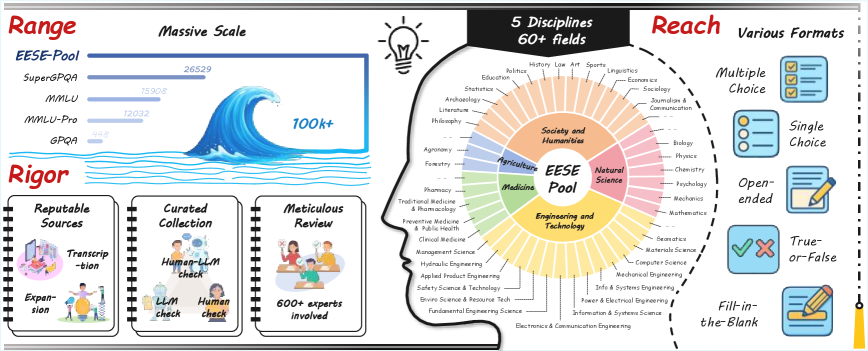
随着基础模型的能力和部署迅速增长,评估其科学理解能力变得至关重要。现有的科学基准在范围、覆盖面和严谨性方面取得进展,但常面临数据泄露风险和大规模测试导致的评估效率低下两大挑战。为解决这些问题,我们引入了动态基准Ever-Evolving Science Exam (EESE),旨在可靠评估基础模型的科学能力。EESE包含两个部分:1) 一个非公开的EESE-Pool,包含超过10万个由专家构建的科学实例(问题-答案对),涵盖5个学科和500多个子领域,通过多阶段流程确保范围、覆盖面和严谨性;2) 一个定期更新的500个实例子集EESE,经过抽样和验证,实现防泄露、低开销的评估。在32个开源和闭源模型上的实验表明,EESE有效地区分了模型在科学领域和认知维度上的优势和劣势。总体而言,EESE为科学基准设计提供了一个鲁棒、可扩展且向前兼容的解决方案,能够真实地衡量基础模型处理科学问题的能力。
🔬 方法详解
问题定义:论文旨在解决现有科学基准测试中普遍存在的数据泄露问题,以及大规模测试带来的评估效率低下的问题。现有基准测试容易被模型通过记忆训练数据而作弊,无法真实反映模型的科学理解能力。同时,对所有数据进行测试会耗费大量计算资源和时间。
核心思路:论文的核心思路是构建一个动态演进的科学考试基准,即Ever-Evolving Science Exam (EESE)。通过维护一个庞大且不断更新的非公开题库(EESE-Pool),并从中定期抽样生成新的评估子集(EESE),从而有效防止数据泄露,并降低评估的计算成本。这种动态更新的机制保证了基准测试的长期有效性和可靠性。
技术框架:EESE的整体框架包含两个主要组成部分:EESE-Pool和EESE。EESE-Pool是一个包含超过10万个科学实例的非公开题库,涵盖5个学科和500多个子领域。这些实例由专家构建,并经过多阶段的质量控制流程。EESE是定期更新的500个实例子集,从EESE-Pool中抽样生成,并经过验证以确保其代表性和难度。评估流程是,模型在EESE上进行测试,根据其在EESE上的表现来评估其科学理解能力。
关键创新:EESE的关键创新在于其动态演进的特性。通过定期更新评估子集,EESE能够有效防止数据泄露,并保持基准测试的新鲜度和挑战性。此外,EESE-Pool的构建过程也注重范围、覆盖面和严谨性,确保了基准测试的全面性和可靠性。与静态的基准测试相比,EESE能够更真实地反映模型在科学领域的泛化能力。
关键设计:EESE-Pool的构建采用多阶段流程,包括问题生成、答案验证和难度评估等。问题生成由领域专家负责,确保问题的科学性和准确性。答案验证采用人工和自动相结合的方式,确保答案的正确性。难度评估则通过统计分析和专家评估相结合的方式,确保问题的难度分布合理。EESE的抽样策略也经过精心设计,以确保评估子集的代表性和多样性。具体参数设置和损失函数等细节在论文中未详细描述,属于EESE-Pool的私有信息。
🖼️ 关键图片


📊 实验亮点
在32个开源和闭源模型上的实验结果表明,EESE能够有效区分不同模型在科学领域和认知维度上的表现。例如,某些模型在特定学科或认知维度上表现出色,但在其他方面则存在不足。EESE的评估结果能够为模型开发者提供有价值的反馈,帮助他们改进模型的设计和训练。
🎯 应用场景
EESE可用于评估各种基础模型在科学领域的理解能力,帮助研究人员了解模型的优势和劣势,并指导模型的改进。此外,EESE还可以用于比较不同模型之间的性能,促进科学领域人工智能的发展。该基准测试的动态更新特性使其能够长期有效,并适应不断发展的模型能力。
📄 摘要(原文)
As foundation models grow rapidly in capability and deployment, evaluating their scientific understanding becomes increasingly critical. Existing science benchmarks have made progress towards broad Range, wide Reach, and high Rigor, yet they often face two major challenges: data leakage risks that compromise benchmarking validity, and evaluation inefficiency due to large-scale testing. To address these issues, we introduce the Ever-Evolving Science Exam (EESE), a dynamic benchmark designed to reliably assess scientific capabilities in foundation models. Our approach consists of two components: 1) a non-public EESE-Pool with over 100K expertly constructed science instances (question-answer pairs) across 5 disciplines and 500+ subfields, built through a multi-stage pipeline ensuring Range, Reach, and Rigor, 2) a periodically updated 500-instance subset EESE, sampled and validated to enable leakage-resilient, low-overhead evaluations. Experiments on 32 open- and closed-source models demonstrate that EESE effectively differentiates the strengths and weaknesses of models in scientific fields and cognitive dimensions. Overall, EESE provides a robust, scalable, and forward-compatible solution for science benchmark design, offering a realistic measure of how well foundation models handle science questions. The project page is at: https://github.com/aiben-ch/EESE.