Beyond Isolated Dots: Benchmarking Structured Table Construction as Deep Knowledge Extraction
作者: Tianyun Zhong, Guozhao Mo, Yanjiang Liu, Yihan Chen, Lingdi Kong, Xuanang Chen, Yaojie Lu, Hongyu Lin, Shiwei Ye, Xianpei Han, Ben He, Le Sun
分类: cs.CL
发布日期: 2025-07-22 (更新: 2025-10-30)
💡 一句话要点
提出AOE基准,评估LLM从复杂文档中抽取结构化表格信息的能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 信息抽取 结构化表格 基准测试 文档理解
📋 核心要点
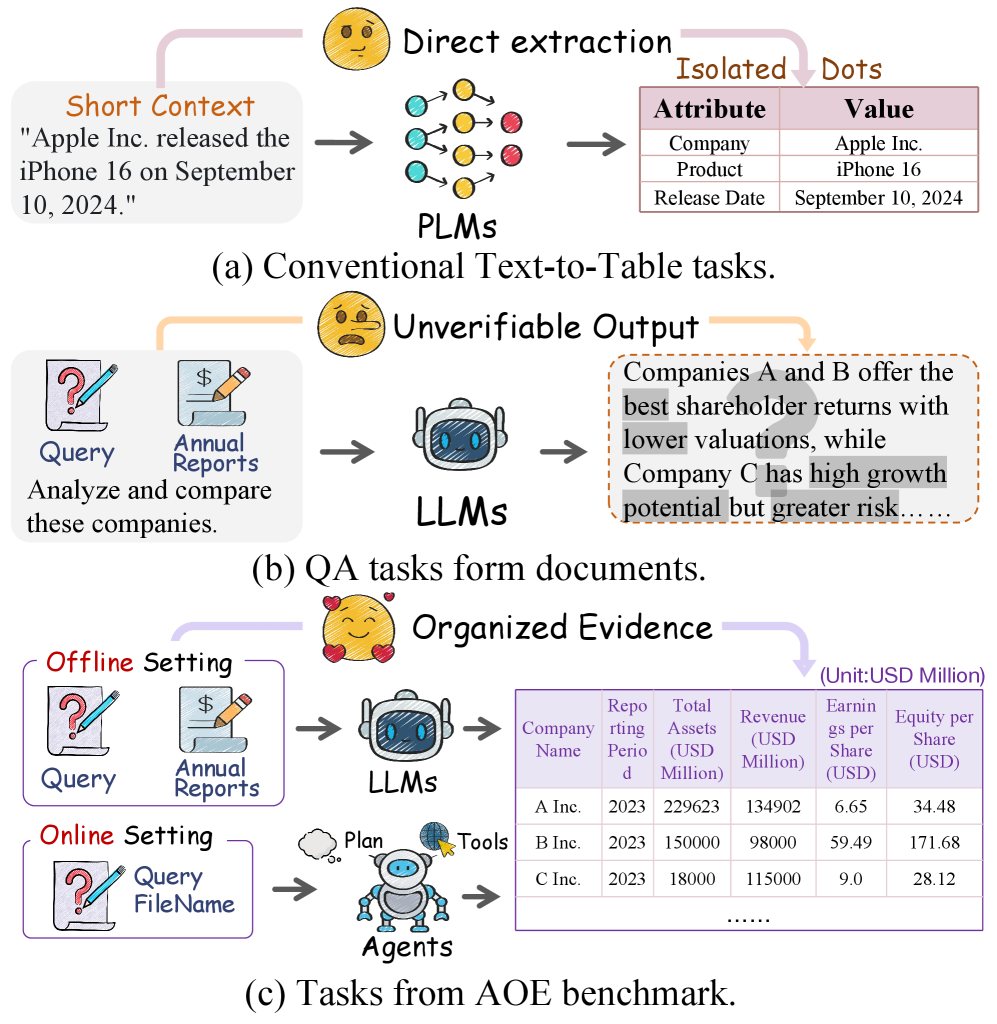
- 现有LLM在处理复杂文档时,提取的信息通常是段落形式,缺乏组织性和可追溯性。
- 论文提出AOE基准,旨在评估LLM从碎片化文档中提取信息并构建结构化表格的能力。
- 实验结果表明,即使是最先进的LLM在AOE基准上表现不佳,表明该任务具有挑战性。
📝 摘要(中文)
随着大型语言模型(LLMs)的兴起,人们期望LLMs能够有效地从复杂的真实文档(例如,论文、报告)中提取显式信息。然而,大多数LLMs生成段落式的答案,这些答案混乱、无组织且难以追溯。为了弥合这一差距,我们引入了排列和组织提取基准(AOE),这是一个新的双语基准,包含不同长度的数据和文档,旨在系统地评估LLMs理解碎片化文档并将孤立信息重构为一个有组织的表格的能力。与依赖于固定模式和狭窄任务领域的传统文本到表格任务不同,AOE包括跨越三个不同领域的11个精心设计的任务,要求模型生成针对不同输入查询量身定制的上下文特定模式。在实验中,我们评估了开源和闭源的先进LLMs。结果表明,即使是最先进的模型也表现不佳。该基准可在https://anonymous.4open.science/r/AOE-Benchmark/上获得。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在从复杂、碎片化的真实世界文档(如论文和报告)中提取结构化信息时面临的挑战。现有方法通常生成段落式的答案,这些答案缺乏组织性,难以追踪信息的来源,并且难以直接用于下游任务。传统的文本到表格任务通常依赖于固定的模式和狭窄的领域,无法满足真实世界文档的多样性和复杂性。
核心思路:论文的核心思路是构建一个更具挑战性和现实意义的基准测试,即AOE(Arranged and Organized Extraction Benchmark),用于系统地评估LLMs将分散在文档中的信息组织成结构化表格的能力。AOE基准包含多个任务,每个任务都要求模型根据上下文生成特定的表格模式,从而更好地模拟真实世界的信息提取场景。
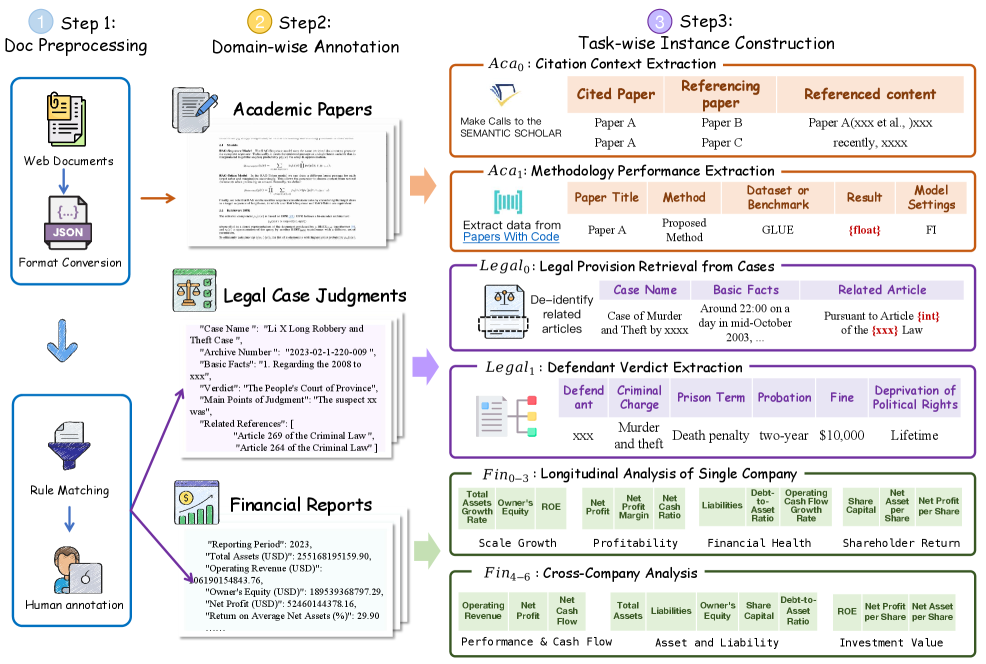
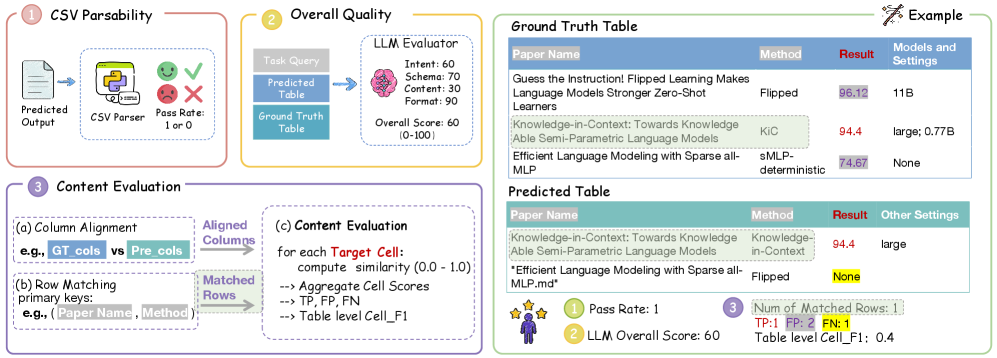
技术框架:AOE基准包含以下几个关键组成部分:1) 多样化的数据集:包含来自三个不同领域的文档,涵盖不同长度和复杂度的文本。2) 精心设计的任务:包括11个任务,每个任务都要求模型根据特定的查询从文档中提取信息并构建表格。3) 上下文相关的模式生成:模型需要根据输入查询动态地生成表格的模式,而不是使用预定义的固定模式。4) 评估指标:用于评估模型生成的表格的准确性和完整性。
关键创新:AOE基准的关键创新在于其任务的复杂性和真实性。与传统的文本到表格任务相比,AOE要求模型不仅要提取信息,还要理解上下文并生成合适的表格模式。这种上下文相关的模式生成能力是评估LLMs在真实世界场景中应用的关键。此外,AOE基准还提供了双语数据,支持对LLMs的跨语言能力进行评估。
关键设计:AOE基准的任务设计考虑了不同领域的特点和信息提取的需求。例如,某些任务可能需要模型从科学论文中提取实验结果,而另一些任务可能需要模型从报告中提取财务数据。每个任务都包含一个查询,用于指导模型提取相关信息。数据集的构建过程中,作者们也进行了人工标注和验证,以确保数据的质量和准确性。具体的参数设置、损失函数和网络结构的选择取决于所使用的LLM模型,论文主要关注的是基准的构建和评估,而不是提出特定的模型架构。
🖼️ 关键图片
📊 实验亮点
实验结果表明,即使是最先进的开源和闭源LLMs在AOE基准上都表现不佳,这突显了当前LLMs在处理复杂文档和构建结构化信息方面的局限性。这表明AOE基准能够有效区分不同LLMs的性能,并为未来的研究提供了明确的方向,即如何提升LLMs在复杂信息抽取任务中的能力。
🎯 应用场景
该研究成果可应用于智能文档处理、知识图谱构建、商业情报分析等领域。通过提升LLM从复杂文档中提取结构化信息的能力,可以帮助用户更高效地获取和利用信息,辅助决策,并提高工作效率。未来,该基准可以促进LLM在信息抽取和知识表示方面的研究进展。
📄 摘要(原文)
With the emergence of large language models (LLMs), there is an expectation that LLMs can effectively extract explicit information from complex real-world documents (e.g., papers, reports). However, most LLMs generate paragraph-style answers that are chaotic, disorganized, and untraceable. To bridge this gap, we introduce the Arranged and Organized Extraction Benchmark (AOE), a new bilingual benchmark with data and documents of varying lengths designed to systematically evaluate the ability of LLMs to comprehend fragmented documents and reconstruct isolated information into one organized table. Unlike conventional text-to-table tasks, which rely on fixed schema and narrow task domains, AOE includes 11 carefully crafted tasks across three diverse domains, requiring models to generate context-specific schema tailored to varied input queries. In the experiment, we evaluated both open-source and closed-source state-of-the-art LLMs. The results show that even the most advanced models struggled significantly. The benchmark is available at https://anonymous.4open.science/r/AOE-Benchmark/.