Efficient Compositional Multi-tasking for On-device Large Language Models
作者: Ondrej Bohdal, Mete Ozay, Jijoong Moon, Kyeng-Hun Lee, Hyeonmok Ko, Umberto Michieli
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-07-21 (更新: 2025-10-11)
备注: Accepted at EMNLP 2025 (main track, long paper)
💡 一句话要点
提出面向端侧LLM的高效组合式多任务学习方法,解决资源受限场景下的复杂任务执行问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 端侧LLM 多任务学习 Adapter 任务合并 可学习校准 资源受限 组合式任务
📋 核心要点
- 现有LLM任务合并方法主要针对单任务场景,无法有效处理端侧资源受限的组合式多任务。
- 提出一种名为“可学习校准”的高效方法,专门针对端侧设备,旨在平衡性能与资源消耗。
- 构建包含四个实际组合任务的基准,为端侧LLM多任务处理研究提供了评估平台。
📝 摘要(中文)
Adapter参数为修改机器学习模型的行为提供了一种机制,并在大型语言模型(LLM)和生成式AI的背景下获得了显著的普及。这些参数可以通过一种称为任务合并的过程进行合并,以支持多个任务。然而,先前在LLM中进行合并的工作,特别是在自然语言处理中,仅限于每个测试示例仅处理单个任务的场景。在本文中,我们专注于端侧设置,并研究了基于文本的组合式多任务处理问题,其中每个测试示例都涉及同时执行多个任务。例如,生成长文本的翻译摘要需要同时解决翻译和摘要任务。为了促进对该领域的研究,我们提出了一个包含四个实际相关的组合任务的基准。我们还提出了一种专为端侧应用量身定制的高效方法(可学习校准),其中计算资源有限,强调需要资源高效且高性能的解决方案。我们的贡献为推进LLM在实际多任务场景中的能力奠定了基础,从而扩展了它们在复杂、资源受限用例中的适用性。
🔬 方法详解
问题定义:论文旨在解决端侧设备上大型语言模型(LLM)进行组合式多任务处理的问题。现有的任务合并方法主要关注单任务场景,无法有效利用有限的计算资源来同时执行多个相关任务,例如翻译并总结长文本。这种局限性阻碍了LLM在资源受限环境下的实际应用。
核心思路:论文的核心思路是设计一种资源高效的“可学习校准”方法,通过学习到的参数来调整不同任务的adapter,从而优化模型在组合式多任务场景下的性能。这种方法旨在最小化计算开销,同时最大化模型在多个任务上的表现。
技术框架:整体框架包括:1) 预训练的LLM;2) 为每个任务添加的Adapter模块;3) 可学习的校准模块,用于调整不同Adapter的输出。流程如下:输入文本首先通过LLM和相应的Adapter进行处理,然后校准模块根据输入和任务类型调整Adapter的输出,最后将调整后的输出组合起来生成最终结果。
关键创新:关键创新在于“可学习校准”模块的设计。该模块通过学习到的参数,动态地调整不同任务Adapter的贡献,从而优化模型在组合式多任务场景下的性能。与直接合并Adapter参数的方法相比,该方法更加灵活,能够更好地适应不同任务之间的相互影响。
关键设计:可学习校准模块的具体实现细节未知,但可以推测其可能包含一些可学习的权重或变换矩阵,用于调整不同Adapter的输出。损失函数的设计可能需要考虑不同任务之间的平衡,以及模型在资源消耗方面的约束。具体的网络结构和参数设置未知,需要在实验中进行调整和优化。
🖼️ 关键图片
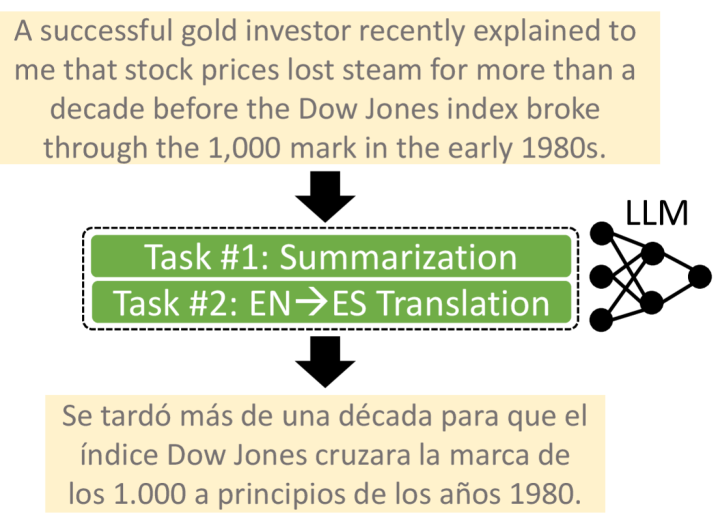


📊 实验亮点
论文提出了一个包含四个实际组合任务的基准,并验证了所提出的“可学习校准”方法在端侧设备上的有效性。虽然具体的性能数据未知,但论文强调该方法在资源效率和性能方面都具有优势,为端侧LLM多任务处理研究奠定了基础。
🎯 应用场景
该研究成果可应用于各种端侧设备,例如智能手机、嵌入式系统等,使这些设备能够高效地执行复杂的组合式任务,例如实时翻译、智能摘要、多语言信息检索等。这有助于提升用户体验,并拓展LLM在资源受限环境下的应用范围,例如在离线状态下提供智能服务。
📄 摘要(原文)
Adapter parameters provide a mechanism to modify the behavior of machine learning models and have gained significant popularity in the context of large language models (LLMs) and generative AI. These parameters can be merged to support multiple tasks via a process known as task merging. However, prior work on merging in LLMs, particularly in natural language processing, has been limited to scenarios where each test example addresses only a single task. In this paper, we focus on on-device settings and study the problem of text-based compositional multi-tasking, where each test example involves the simultaneous execution of multiple tasks. For instance, generating a translated summary of a long text requires solving both translation and summarization tasks concurrently. To facilitate research in this setting, we propose a benchmark comprising four practically relevant compositional tasks. We also present an efficient method (Learnable Calibration) tailored for on-device applications, where computational resources are limited, emphasizing the need for solutions that are both resource-efficient and high-performing. Our contributions lay the groundwork for advancing the capabilities of LLMs in real-world multi-tasking scenarios, expanding their applicability to complex, resource-constrained use cases.