The Prompt Makes the Person(a): A Systematic Evaluation of Sociodemographic Persona Prompting for Large Language Models
作者: Marlene Lutz, Indira Sen, Georg Ahnert, Elisa Rogers, Markus Strohmaier
分类: cs.CL
发布日期: 2025-07-21 (更新: 2025-10-03)
备注: Accepted to EMNLP Findings 2025
💡 一句话要点
系统评估社会人口学角色提示对大语言模型的影响,揭示刻板印象与模型选择的关键因素
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 角色提示 社会人口学模拟 刻板印象 提示工程
📋 核心要点
- 现有方法在利用大语言模型模拟不同社会人口群体时,角色提示的制定方式对结果影响巨大,导致模拟结果的真实性存疑。
- 该论文系统研究了角色采纳形式和人口统计学启动策略对LLM模拟不同社会人口群体的影响,旨在优化角色提示设计。
- 实验结果表明,LLM在模拟边缘化群体时表现不佳,但特定的提示策略(如访谈形式和基于名称的启动)可以减少刻板印象。
📝 摘要(中文)
角色提示越来越多地被用于大语言模型(LLMs)中,以模拟不同社会人口群体的观点。然而,角色提示的制定方式会显著影响结果,引发了对此类模拟真实性的担忧。本文使用五个开源LLM,系统地研究了不同的角色提示策略,特别是角色采纳形式和人口统计学启动策略,如何在开放式和封闭式任务中影响15个交叉人口统计群体的LLM模拟。研究结果表明,LLM在模拟边缘化群体时存在困难,但人口统计学启动和角色采纳策略的选择会显著影响其表现。具体而言,研究发现以访谈形式进行提示和基于名称的启动可以帮助减少刻板印象并改善一致性。令人惊讶的是,像OLMo-2-7B这样的小型模型优于像Llama-3.3-70B这样的大型模型。研究结果为在基于LLM的模拟研究中设计社会人口学角色提示提供了可操作的指导。
🔬 方法详解
问题定义:论文旨在解决大语言模型(LLMs)在进行社会人口学模拟时,由于角色提示(persona prompt)的设计不当,导致模拟结果失真,无法准确反映目标人群观点的问题。现有方法缺乏对不同提示策略的系统性评估,无法有效指导用户设计高质量的角色提示,从而可能加剧刻板印象和偏见。
核心思路:论文的核心思路是通过系统性的实验评估,分析不同的角色提示策略(包括角色采纳形式和人口统计学启动策略)对LLM模拟结果的影响。通过对比不同提示策略下LLM的表现,揭示哪些策略能够减少刻板印象、提高模拟的真实性和一致性,从而为用户提供可操作的提示设计指南。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 选择多个开源LLM作为实验对象;2) 构建包含15个交叉人口统计群体的测试数据集;3) 设计不同的角色提示策略,包括不同的角色采纳形式(如角色扮演、访谈等)和人口统计学启动策略(如基于名称的启动、基于描述的启动等);4) 在开放式和封闭式任务中,评估不同提示策略下LLM的模拟结果;5) 分析实验数据,对比不同提示策略的表现,并总结出有效的提示设计原则。
关键创新:该论文的关键创新在于:1) 系统性地评估了不同角色提示策略对LLM社会人口学模拟的影响,填补了该领域的研究空白;2) 揭示了LLM在模拟边缘化群体时存在的困难,并指出了特定提示策略(如访谈形式和基于名称的启动)可以有效减少刻板印象;3) 发现小型模型在某些情况下优于大型模型,挑战了以往认为模型越大越好的观点。
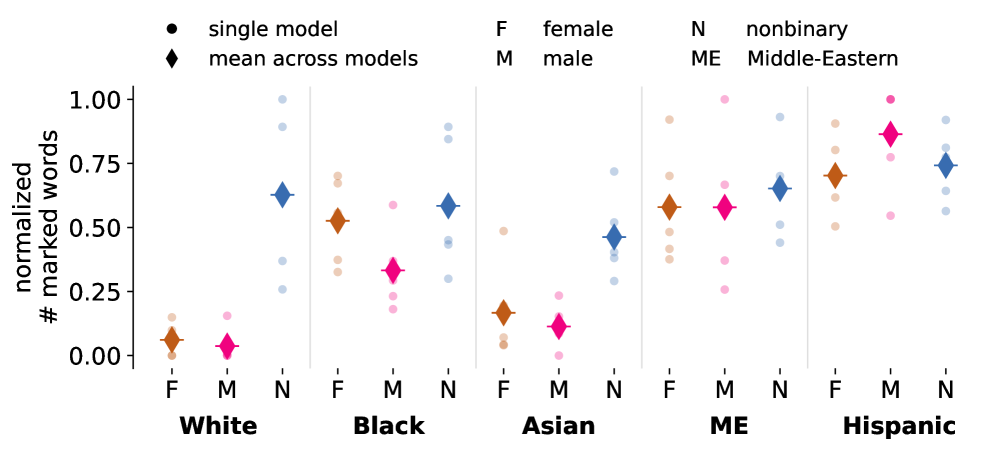
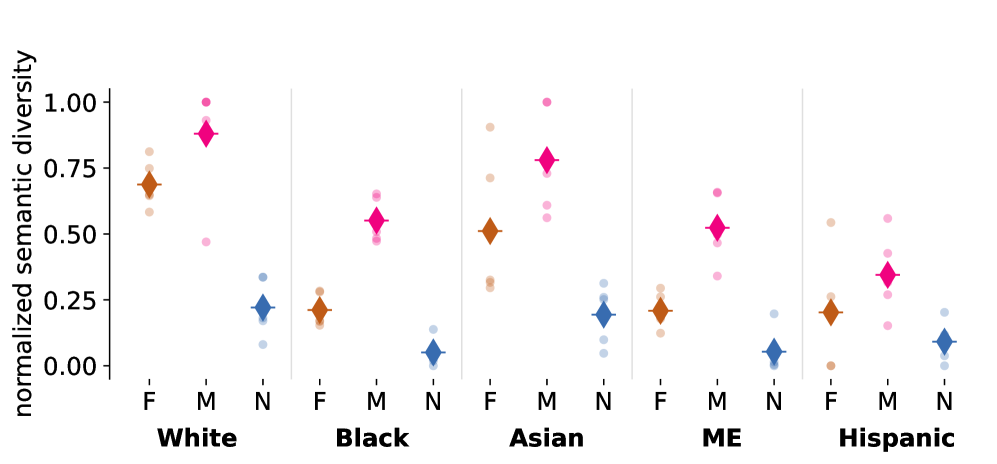
关键设计:论文的关键设计包括:1) 角色采纳形式:比较了不同的角色扮演方式,例如直接扮演角色,或者以访谈对象的形式回答问题。访谈形式被证明更有效。2) 人口统计学启动策略:比较了基于名称的启动(例如,使用特定族裔的名字)和基于描述的启动(例如,使用描述人口统计特征的句子)。基于名称的启动表现更好。3) 评估指标:使用了多种评估指标,包括一致性、刻板印象程度等,以全面评估不同提示策略的效果。
🖼️ 关键图片

📊 实验亮点
实验结果表明,LLM在模拟边缘化群体时存在困难,但通过采用访谈形式的角色采纳和基于名称的人口统计学启动策略,可以显著减少刻板印象并提高模拟结果的一致性。令人惊讶的是,小型模型OLMo-2-7B在某些任务中优于大型模型Llama-3.3-70B,这表明模型大小并非决定模拟效果的唯一因素。
🎯 应用场景
该研究成果可应用于社会科学研究、市场调研、政策制定等领域。通过优化角色提示设计,可以利用LLM更准确地模拟不同社会群体的观点和行为,从而为决策提供更可靠的依据。此外,该研究还可以帮助开发者构建更公平、更具包容性的AI系统,避免加剧社会偏见。
📄 摘要(原文)
Persona prompting is increasingly used in large language models (LLMs) to simulate views of various sociodemographic groups. However, how a persona prompt is formulated can significantly affect outcomes, raising concerns about the fidelity of such simulations. Using five open-source LLMs, we systematically examine how different persona prompt strategies, specifically role adoption formats and demographic priming strategies, influence LLM simulations across 15 intersectional demographic groups in both open- and closed-ended tasks. Our findings show that LLMs struggle to simulate marginalized groups but that the choice of demographic priming and role adoption strategy significantly impacts their portrayal. Specifically, we find that prompting in an interview-style format and name-based priming can help reduce stereotyping and improve alignment. Surprisingly, smaller models like OLMo-2-7B outperform larger ones such as Llama-3.3-70B. Our findings offer actionable guidance for designing sociodemographic persona prompts in LLM-based simulation studies.