Learning without training: The implicit dynamics of in-context learning
作者: Benoit Dherin, Michael Munn, Hanna Mazzawi, Michael Wunder, Javier Gonzalvo
分类: cs.CL, cs.LG
发布日期: 2025-07-21 (更新: 2025-12-22)
💡 一句话要点
揭示Transformer在上下文学习中的隐式动态机制,无需额外训练即可实现泛化
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 上下文学习 Transformer模型 自注意力机制 隐式动态 低秩权重更新 大型语言模型 Few-shot学习
📋 核心要点
- 大型语言模型展现出强大的上下文学习能力,但其内在机制尚不明确,成为当前研究的核心问题。
- 该研究表明,Transformer块通过自注意力机制和MLP的结合,能够隐式地根据上下文调整MLP层的权重。
- 理论分析和实验结果均支持这一观点,即Transformer块将上下文转化为MLP层的低秩权重更新,从而实现上下文学习。
📝 摘要(中文)
大型语言模型(LLM)最引人注目的特性之一是其上下文学习能力。在推理时,LLM能够学习新的模式,而无需任何额外的权重更新,只要这些模式以示例的形式出现在提示中,即使这些模式在训练期间没有见过。这种现象背后的机制在很大程度上仍然未知。本文表明,自注意力层与MLP的堆叠允许Transformer块根据上下文隐式地修改MLP层的权重。通过理论和实验,我们认为这种简单的机制可能是LLM能够进行上下文学习的原因,而不仅仅是在训练期间。具体来说,我们展示了Transformer块如何隐式地将上下文转换为其MLP层的低秩权重更新。
🔬 方法详解
问题定义:大型语言模型(LLM)的上下文学习能力,即在推理阶段无需额外训练就能从prompt中的示例学习新模式,其内在机制尚不明确。现有的研究未能充分解释这种无需梯度更新的学习现象,以及Transformer架构在其中的作用。
核心思路:论文的核心思路是揭示Transformer块内部的隐式动态机制,特别是自注意力层和MLP的相互作用。作者认为,Transformer块能够将上下文信息转化为MLP层的低秩权重更新,从而实现上下文学习。这种设计避免了显式的梯度更新,而是通过架构本身来适应新的模式。
技术框架:该研究主要关注单个Transformer块的内部运作。其核心在于分析自注意力层如何处理输入上下文,并将信息传递给MLP层。作者通过数学推导和实验验证,展示了自注意力层如何将上下文信息编码为一种低秩的权重更新,并将其应用于MLP层。整体流程可以概括为:输入上下文 -> 自注意力层(提取上下文信息) -> MLP层(应用上下文信息进行预测)。
关键创新:最重要的技术创新点在于揭示了Transformer块的隐式权重更新机制。与传统的训练方式不同,这种机制不需要显式的梯度更新,而是通过自注意力层和MLP的相互作用,自动地将上下文信息融入到MLP层的权重中。这种隐式学习方式解释了LLM在上下文学习中的强大泛化能力。
关键设计:论文侧重于理论分析和概念验证,并没有特别强调具体的参数设置或网络结构。关键在于对自注意力机制和MLP层之间关系的数学建模,以及通过实验验证这种模型的有效性。研究中可能涉及对自注意力头的数量、MLP层的维度等参数的调整,但这些细节并非研究的核心关注点。
🖼️ 关键图片
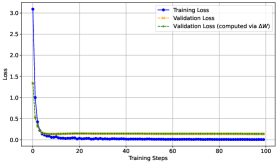
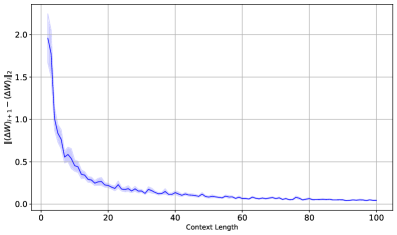
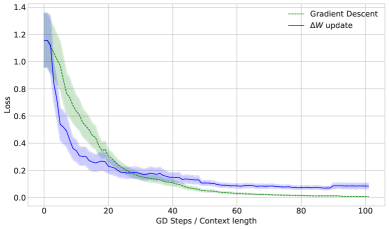
📊 实验亮点
论文通过理论分析和实验验证,揭示了Transformer块内部的隐式权重更新机制。实验结果表明,Transformer块能够将上下文信息转化为MLP层的低秩权重更新,从而实现上下文学习。虽然论文没有提供具体的性能数据或对比基线,但其理论贡献在于解释了LLM在上下文学习中的泛化能力。
🎯 应用场景
该研究成果有助于更好地理解大型语言模型的内在工作机制,为改进模型设计、提升上下文学习能力提供理论指导。潜在应用包括:更高效的Few-shot学习、更强的泛化能力、以及在资源受限场景下的模型部署。此外,该研究也为开发新型的、无需大量训练数据的AI模型提供了新的思路。
📄 摘要(原文)
One of the most striking features of Large Language Models (LLMs) is their ability to learn in-context. Namely at inference time an LLM is able to learn new patterns without any additional weight update when these patterns are presented in the form of examples in the prompt, even if these patterns were not seen during training. The mechanisms through which this can happen are still largely unknown. In this work, we show that the stacking of a self-attention layer with an MLP, allows the transformer block to implicitly modify the weights of the MLP layer according to the context. We argue through theory and experimentation that this simple mechanism may be the reason why LLMs can learn in-context and not only during training. Specifically, we show how a transformer block implicitly transforms a context into a low-rank weight-update of its MLP layer.