The Impact of Language Mixing on Bilingual LLM Reasoning
作者: Yihao Li, Jiayi Xin, Miranda Muqing Miao, Qi Long, Lyle Ungar
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-07-21 (更新: 2025-09-30)
备注: Accepted at EMNLP 2025 (Main Conference)
💡 一句话要点
研究表明双语LLM推理中的语言混合是一种策略性行为,并提出引导解码方法提升推理精度。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 双语LLM 语言混合 推理 强化学习 可验证奖励 探针 解码
📋 核心要点
- 现有的双语LLM在推理过程中存在语言混合现象,但其对推理的影响尚不明确。
- 该研究通过分析发现,语言混合是强化学习训练阶段产生的,并且能够提升推理性能。
- 实验表明,强制单语解码会降低准确率,而使用探针引导解码可以提高准确率。
📝 摘要(中文)
本文研究了中英双语推理模型中的语言切换现象。研究发现,使用可验证奖励的强化学习(RLVR)是导致语言混合的关键训练阶段。研究表明,语言混合可以增强推理能力:强制进行单语解码会导致MATH500数据集上的准确率下降5.6个百分点。此外,一个轻量级的探针可以被训练来预测潜在的语言切换是否会促进或损害推理,并且当用于指导解码时,可以提高2.92个百分点的准确率。研究结果表明,语言混合不仅仅是多语言训练的副产品,而是一种策略性的推理行为。
🔬 方法详解
问题定义:论文旨在研究双语大型语言模型(LLM)在推理过程中出现的语言混合现象,即在思维链中交替使用不同语言。现有研究表明,抑制这种行为可能会降低模型的准确性,但语言混合对推理的具体影响以及产生原因尚不明确。因此,论文要解决的问题是:语言混合是否仅仅是多语言训练的副产品,还是具有策略性意义的推理行为?
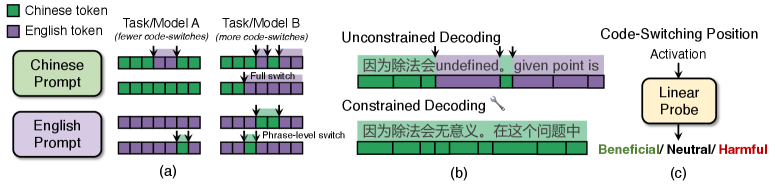
核心思路:论文的核心思路是深入分析双语LLM的训练过程,特别是强化学习阶段,以确定语言混合产生的原因。然后,通过实验验证语言混合对推理性能的影响,并设计一种方法来利用语言混合提升推理能力。具体来说,论文训练一个探针来预测语言切换的潜在影响,并使用该探针来指导解码过程。
技术框架:整体框架包括以下几个阶段:1) 使用中英文数据训练一个双语LLM;2) 使用强化学习(RLVR)对模型进行微调;3) 分析RLVR训练阶段对语言混合的影响;4) 训练一个轻量级探针来预测语言切换的收益;5) 使用探针引导解码,并评估其对推理性能的影响。
关键创新:论文的关键创新在于:1) 揭示了强化学习是导致语言混合的关键训练阶段;2) 证明了语言混合可以增强推理能力,而非仅仅是训练的副产品;3) 提出了一种基于探针的语言切换预测方法,并成功地将其应用于指导解码,从而提升了推理准确率。
关键设计:论文的关键设计包括:1) 使用可验证奖励的强化学习(RLVR)来训练模型,鼓励模型生成更准确的推理链;2) 设计了一个轻量级的探针,该探针以模型当前状态和潜在的语言切换为输入,预测该切换对推理的收益;3) 使用探针的预测结果来指导解码过程,即在生成每个token时,根据探针的预测结果选择使用哪种语言。
🖼️ 关键图片

📊 实验亮点
实验结果表明,强制单语解码会导致MATH500数据集上的准确率下降5.6个百分点,验证了语言混合对推理的积极作用。此外,使用探针引导解码可以将准确率提高2.92个百分点,证明了该方法能够有效地利用语言混合来提升推理性能。
🎯 应用场景
该研究成果可应用于提升双语LLM的推理能力,尤其是在需要多语言知识融合的场景下,例如跨语言信息检索、机器翻译、多语言问答等。通过理解和利用语言混合,可以开发出更智能、更高效的双语AI系统,促进跨文化交流和知识共享。
📄 摘要(原文)
Proficient multilingual speakers often intentionally switch languages in the middle of a conversation. Similarly, recent reasoning-focused bilingual large language models (LLMs) with strong capabilities in both languages exhibit language mixing-alternating languages within their chain of thought. Discouraging this behavior in DeepSeek-R1 was found to degrade accuracy, suggesting that language mixing may benefit reasoning. In this work, we study language switching in Chinese-English bilingual reasoning models. We identify reinforcement learning with verifiable rewards (RLVR) as the critical training stage that leads to language mixing. We show that language mixing can enhance reasoning: enforcing monolingual decoding reduces accuracy by 5.6 percentage points on MATH500. Additionally, a lightweight probe can be trained to predict whether a potential language switch would benefit or harm reasoning, and when used to guide decoding, increases accuracy by 2.92 percentage points. Our findings suggest that language mixing is not merely a byproduct of multilingual training, but is a strategic reasoning behavior.