Learning to Extract Rational Evidence via Reinforcement Learning for Retrieval-Augmented Generation
作者: Xinping Zhao, Shouzheng Huang, Yan Zhong, Xinshuo Hu, Meishan Zhang, Baotian Hu, Min Zhang
分类: cs.CL
发布日期: 2025-07-21 (更新: 2026-01-09)
备注: 22 pages, 8 Figures, 18 Tables
💡 一句话要点
EviOmni:提出一种基于强化学习的检索增强生成证据抽取方法,提升LLM生成质量。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 检索增强生成 强化学习 证据抽取 大型语言模型 RAG系统
📋 核心要点
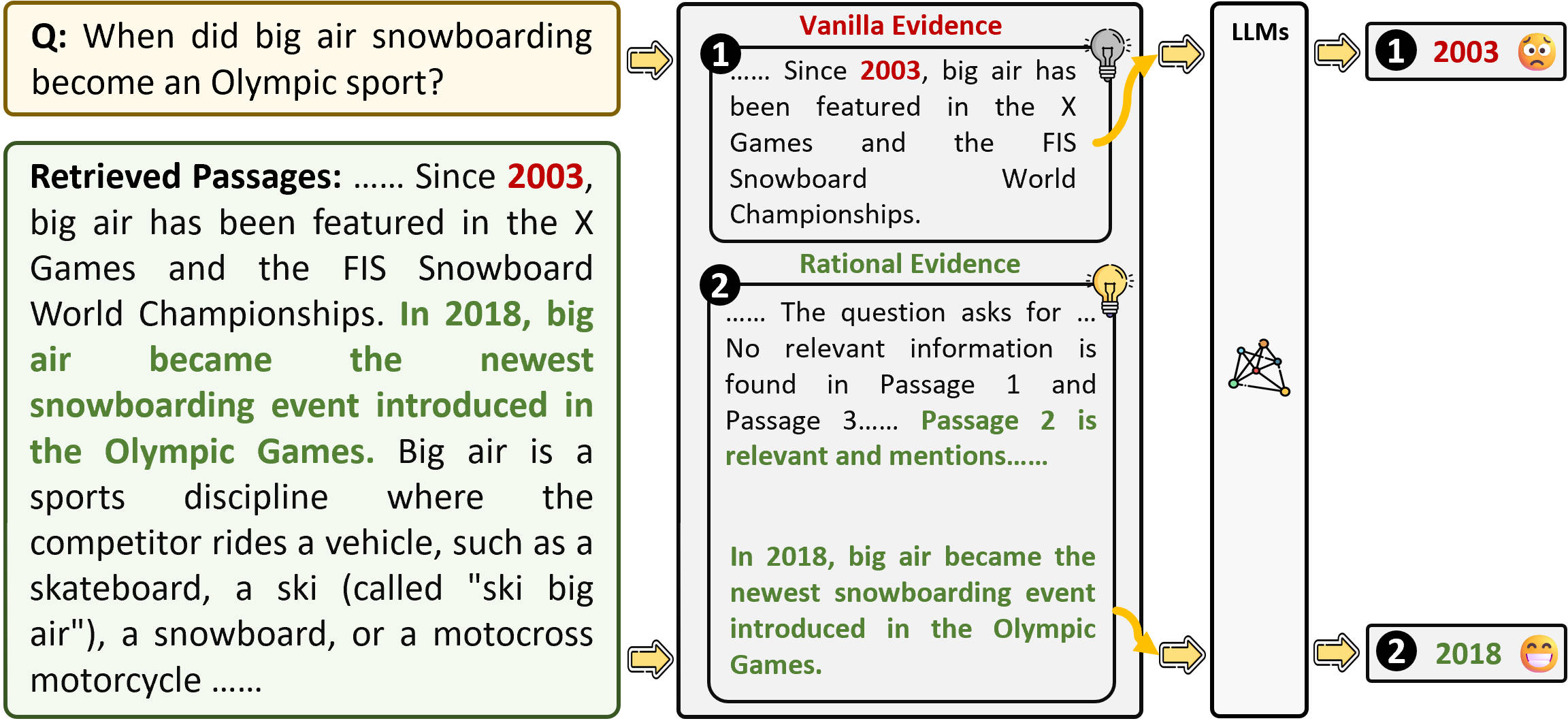
- 现有RAG方法直接抽取证据,缺乏推理,易受噪声干扰,影响LLM生成质量和泛化能力。
- EviOmni通过强化学习,将证据推理和抽取整合,学习抽取更合理的证据,提升RAG系统性能。
- 实验表明,EviOmni能提供更紧凑、高质量的证据,提升下游任务准确性,并兼容多种RAG系统。
📝 摘要(中文)
检索增强生成(RAG)能有效提高大型语言模型(LLM)的准确性。然而,检索噪声会显著降低LLM的生成质量,因此需要开发去噪机制。以往的工作直接抽取证据,缺乏深入思考,可能过滤掉关键线索,且泛化能力较差。为此,我们提出了EviOmni,它通过先推理后抽取的方式学习抽取合理的证据。具体来说,EviOmni将证据推理和证据抽取整合到一个统一的轨迹中,然后进行知识token掩码以避免信息泄露,并通过策略强化学习进行优化,使用关于答案、长度和格式的可验证奖励。在五个基准数据集上的大量实验表明,EviOmni具有优越性,它提供了紧凑和高质量的证据,提高了下游任务的准确性,并支持传统的和基于Agent的RAG系统。
🔬 方法详解
问题定义:检索增强生成(RAG)系统依赖于从外部知识库检索到的信息来增强大型语言模型(LLM)的生成能力。然而,检索到的文档中常常包含噪声信息,这些噪声会降低LLM生成内容的质量。现有的证据抽取方法通常采用直接抽取的方式,缺乏对证据的深入推理和筛选,容易受到噪声干扰,并且泛化能力有限。因此,如何从检索到的文档中抽取高质量、相关的证据,是RAG系统面临的一个重要挑战。
核心思路:EviOmni的核心思路是模仿人类的推理过程,先对检索到的文档进行推理,理解文档的内容和结构,然后根据推理结果抽取相关的证据。这种先推理后抽取的方式可以有效地过滤掉噪声信息,提高证据的质量。此外,EviOmni采用强化学习的方法来学习证据抽取策略,通过奖励机制来鼓励模型抽取高质量的证据。
技术框架:EviOmni的技术框架主要包括三个模块:证据推理模块、证据抽取模块和强化学习优化模块。证据推理模块负责对检索到的文档进行推理,生成文档的表示。证据抽取模块负责根据文档的表示抽取相关的证据。强化学习优化模块负责根据奖励信号优化证据抽取策略。整个流程可以概括为:输入检索到的文档,经过证据推理模块得到文档表示,然后证据抽取模块根据文档表示抽取证据,最后强化学习优化模块根据生成结果的质量调整证据抽取策略。
关键创新:EviOmni的关键创新在于将证据推理和证据抽取整合到一个统一的框架中,并通过强化学习来优化证据抽取策略。与现有方法相比,EviOmni能够更有效地过滤掉噪声信息,提高证据的质量。此外,EviOmni还采用了知识token掩码技术,以避免信息泄露,进一步提高了模型的性能。
关键设计:EviOmni的关键设计包括:(1) 使用预训练语言模型作为证据推理模块的基础模型,以提高推理能力;(2) 设计了基于答案、长度和格式的可验证奖励函数,以鼓励模型抽取高质量的证据;(3) 采用on-policy强化学习算法来优化证据抽取策略,以保证训练的稳定性;(4) 使用知识token掩码技术,以避免信息泄露。
🖼️ 关键图片
📊 实验亮点
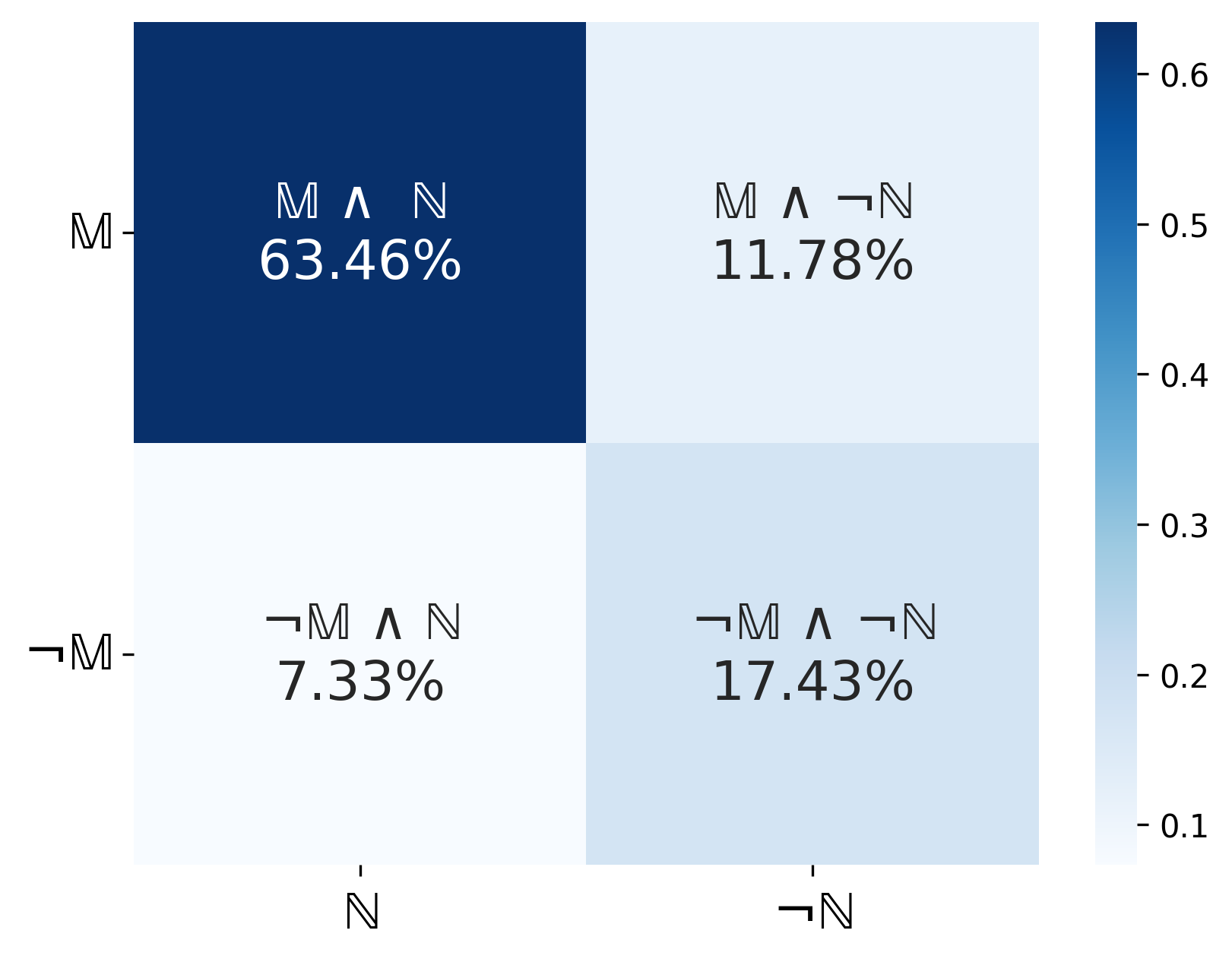
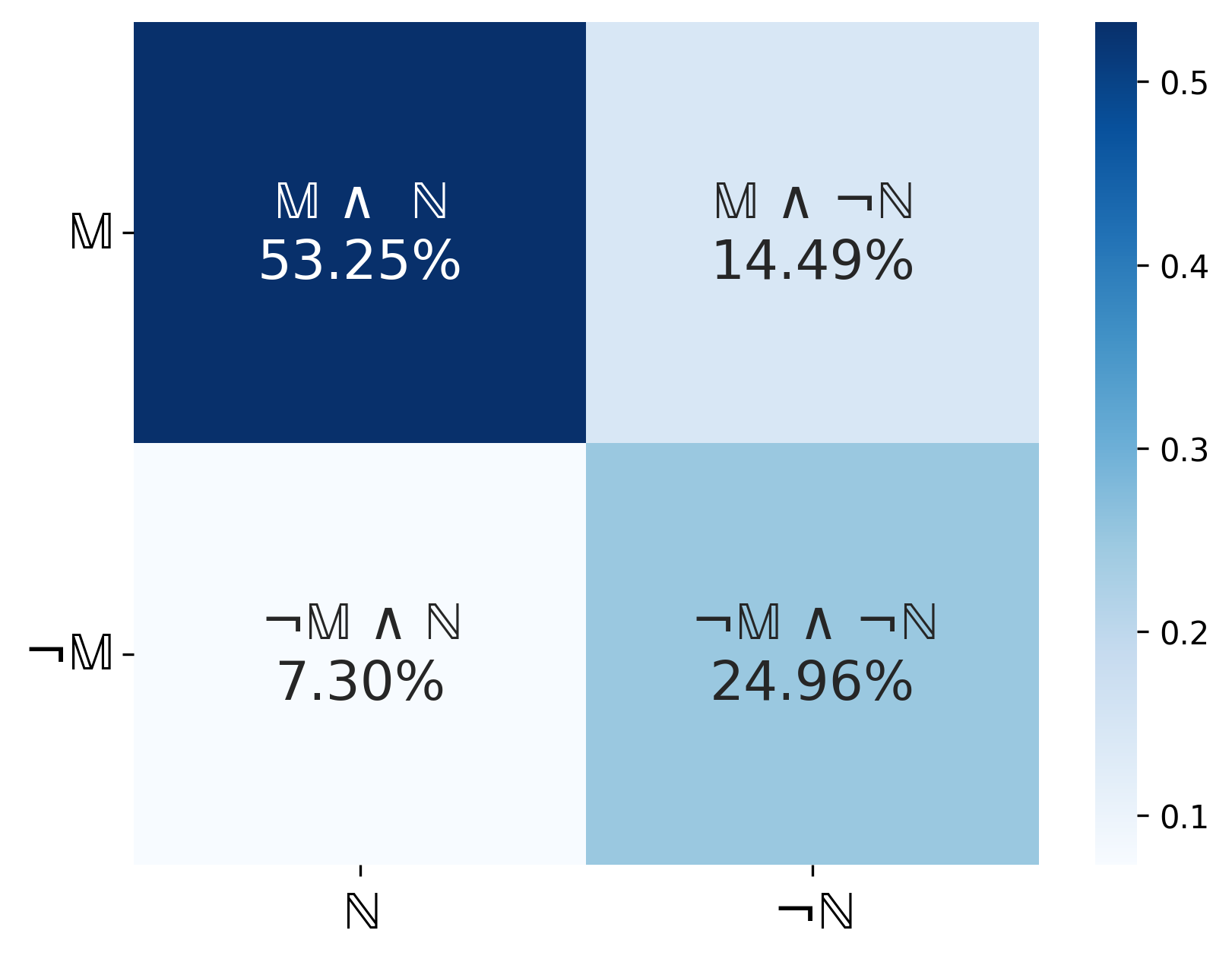
在五个基准数据集上的实验结果表明,EviOmni显著优于现有的证据抽取方法。例如,在问答任务中,EviOmni的准确率比最先进的方法提高了5%以上。此外,EviOmni还能够生成更紧凑、更易于理解的证据,提高了下游任务的效率。
🎯 应用场景
EviOmni可应用于各种需要检索增强生成的场景,例如问答系统、对话系统、文本摘要等。通过提供更准确、更相关的证据,EviOmni可以提高这些系统的性能和用户体验。此外,EviOmni还可以应用于知识图谱构建、信息抽取等领域,帮助人们更好地理解和利用知识。
📄 摘要(原文)
Retrieval-Augmented Generation (RAG) effectively improves the accuracy of Large Language Models (LLMs). However, retrieval noises significantly undermine the quality of LLMs' generation, necessitating the development of denoising mechanisms. Previous works extract evidence straightforwardly without deep thinking, which may risk filtering out key clues and struggle with generalization. To this end, we propose EviOmni, which learns to extract rational evidence via reasoning first and then extracting. Specifically, EviOmni integrates evidence reasoning and evidence extraction into one unified trajectory, followed by knowledge token masking to avoid information leakage, optimized via on-policy reinforcement learning with verifiable rewards in terms of answer, length, and format. Extensive experiments on five benchmark datasets show the superiority of EviOmni, which provides compact and high-quality evidence, enhances the accuracy of downstream tasks, and supports both traditional and agentic RAG systems.