RefCritic: Training Long Chain-of-Thought Critic Models with Refinement Feedback
作者: Qiaoyu Tang, Hao Xiang, Le Yu, Bowen Yu, Hongyu Lin, Yaojie Lu, Xianpei Han, Le Sun, Junyang Lin
分类: cs.CL
发布日期: 2025-07-20
💡 一句话要点
RefCritic:利用精细化反馈训练长链思考评论模型
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 评论模块 强化学习 长链思考 反馈优化
📋 核心要点
- 现有基于监督微调的评论模块无法有效提升大型语言模型的评论能力,产生肤浅且缺乏深度思考的评价。
- RefCritic通过强化学习训练长链思考评论模块,利用双重规则奖励,提升评论质量和指导模型改进的有效性。
- 实验表明,RefCritic在多个基准测试中均优于现有方法,尤其在需要复杂推理的任务上表现突出。
📝 摘要(中文)
随着大型语言模型(LLMs)的快速发展,开发用于精确指导的有效评论模块变得至关重要,但也充满挑战。本文首先证明,用于构建评论模块的监督微调(目前解决方案中广泛采用)未能真正增强模型的评论能力,仅产生肤浅的评论,缺乏充分的思考和验证。为了释放前所未有的评论能力,我们提出了RefCritic,一个基于强化学习的长链思考评论模块,具有双重基于规则的奖励:(1)解决方案判断的实例级正确性;(2)基于评论的策略模型改进准确性,旨在生成高质量的评估,并提供可操作的反馈,从而有效地指导模型改进。我们在Qwen2.5-14B-Instruct和DeepSeek-R1-Distill-Qwen-14B上,跨五个基准评估了RefCritic。在评论和改进设置中,RefCritic在所有基准上都表现出一致的优势,例如,对于各自的基础模型,在AIME25上分别获得了6.8%和7.2%的收益。值得注意的是,在多数投票下,由RefCritic过滤的策略模型显示出随着投票数量增加而优越的扩展性。此外,尽管在解决方案级别监督下进行训练,但RefCritic在ProcessBench(一个用于识别数学推理中错误步骤的基准)上优于步骤级别监督方法。
🔬 方法详解
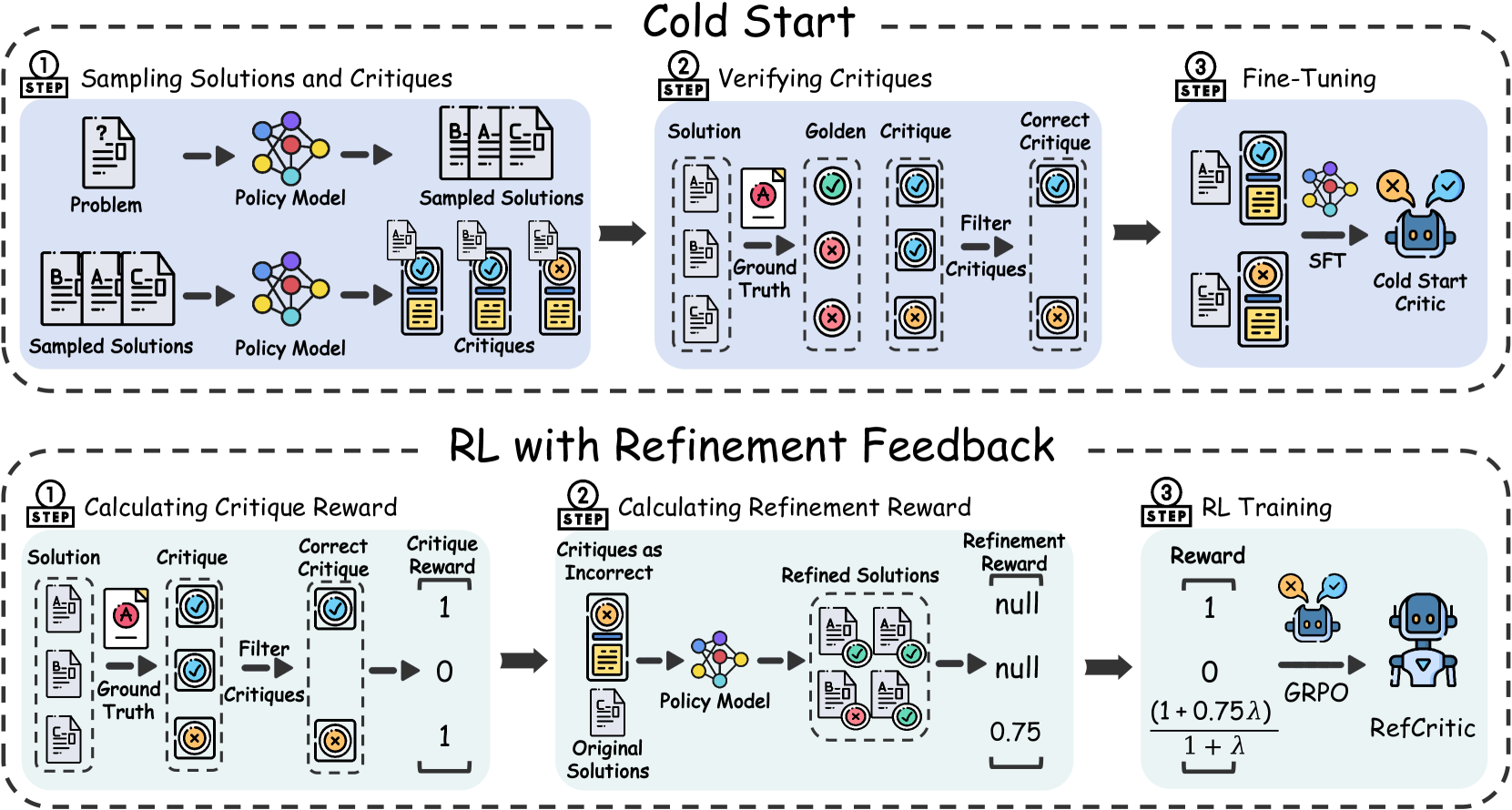
问题定义:现有的大型语言模型评论模块,通常采用监督微调的方式进行训练。然而,这种方法训练出的评论模块往往只能进行表面化的评论,缺乏深入的思考和验证,无法真正有效地指导模型的改进。因此,如何构建一个能够进行高质量、可操作性强的评论模块,是本文要解决的核心问题。
核心思路:本文的核心思路是利用强化学习来训练评论模块,并引入双重规则奖励机制。通过强化学习,评论模块可以学习到更有效的评论策略,而双重规则奖励则可以保证评论的质量和可操作性。具体来说,一个奖励是基于解决方案判断的实例级正确性,另一个奖励是基于评论的策略模型改进准确性。
技术框架:RefCritic的整体框架包含两个主要部分:评论模块和策略模型。评论模块负责对策略模型的输出进行评估,并给出相应的反馈。策略模型则根据评论模块的反馈进行改进。这两个模块通过强化学习进行迭代训练,最终达到一个平衡状态。在训练过程中,使用双重规则奖励来指导评论模块的学习。
关键创新:RefCritic的关键创新在于其利用强化学习来训练评论模块,并引入了双重规则奖励机制。与传统的监督微调方法相比,强化学习可以使评论模块学习到更有效的评论策略,而双重规则奖励则可以保证评论的质量和可操作性。此外,RefCritic还采用了长链思考的方式,使评论模块能够进行更深入的思考和验证。
关键设计:RefCritic的关键设计包括:(1) 采用Transformer架构作为评论模块和策略模型的基础架构;(2) 使用Proximal Policy Optimization (PPO) 算法进行强化学习训练;(3) 设计了实例级正确性奖励和改进准确性奖励两种规则奖励;(4) 采用了长链思考的提示工程,引导模型进行深入分析。
🖼️ 关键图片


📊 实验亮点
RefCritic在多个基准测试中均取得了显著的性能提升。例如,在AIME25基准测试中,RefCritic分别在Qwen2.5-14B-Instruct和DeepSeek-R1-Distill-Qwen-14B上获得了6.8%和7.2%的收益。此外,RefCritic在ProcessBench基准测试中也优于步骤级别监督方法,表明其具有更强的推理能力。实验结果表明,RefCritic能够有效地提高模型的评论能力和改进效果。
🎯 应用场景
RefCritic具有广泛的应用前景,可以应用于各种需要高质量反馈的场景,例如代码生成、文本创作、数学推理等。通过提供更准确、更可操作的反馈,RefCritic可以帮助模型更快地改进,从而提高模型的性能和效率。此外,RefCritic还可以用于评估模型的可靠性和安全性,从而更好地控制模型的行为。
📄 摘要(原文)
With the rapid advancement of Large Language Models (LLMs), developing effective critic modules for precise guidance has become crucial yet challenging. In this paper, we initially demonstrate that supervised fine-tuning for building critic modules (which is widely adopted in current solutions) fails to genuinely enhance models' critique abilities, producing superficial critiques with insufficient reflections and verifications. To unlock the unprecedented critique capabilities, we propose RefCritic, a long-chain-of-thought critic module based on reinforcement learning with dual rule-based rewards: (1) instance-level correctness of solution judgments and (2) refinement accuracies of the policy model based on critiques, aiming to generate high-quality evaluations with actionable feedback that effectively guides model refinement. We evaluate RefCritic on Qwen2.5-14B-Instruct and DeepSeek-R1-Distill-Qwen-14B across five benchmarks. On critique and refinement settings, RefCritic demonstrates consistent advantages across all benchmarks, e.g., 6.8\% and 7.2\% gains on AIME25 for the respective base models. Notably, under majority voting, policy models filtered by RefCritic show superior scaling with increased voting numbers. Moreover, despite training on solution-level supervision, RefCritic outperforms step-level supervised approaches on ProcessBench, a benchmark to identify erroneous steps in mathematical reasoning.