Semi-automated Fact-checking in Portuguese: Corpora Enrichment using Retrieval with Claim extraction
作者: Juliana Resplande Sant'anna Gomes, Arlindo Rodrigues Galvão Filho
分类: cs.CL, cs.AI, cs.IR
发布日期: 2025-07-19
备注: Master Thesis in Computer Science at Federal University on Goias (UFG). Written in Portuguese
💡 一句话要点
提出一种半自动化葡萄牙语事实核查语料库增强方法,利用检索与声明抽取。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 半自动化事实核查 葡萄牙语 语料库增强 大型语言模型 信息检索
📋 核心要点
- 现有葡萄牙语事实核查数据集缺乏外部证据整合,限制了半自动化事实核查系统的发展。
- 利用大型语言模型抽取新闻声明,并结合搜索引擎API检索相关外部证据,模拟人工核查过程。
- 通过数据验证和预处理框架,包括近重复检测,提升了葡萄牙语新闻语料库的质量。
📝 摘要(中文)
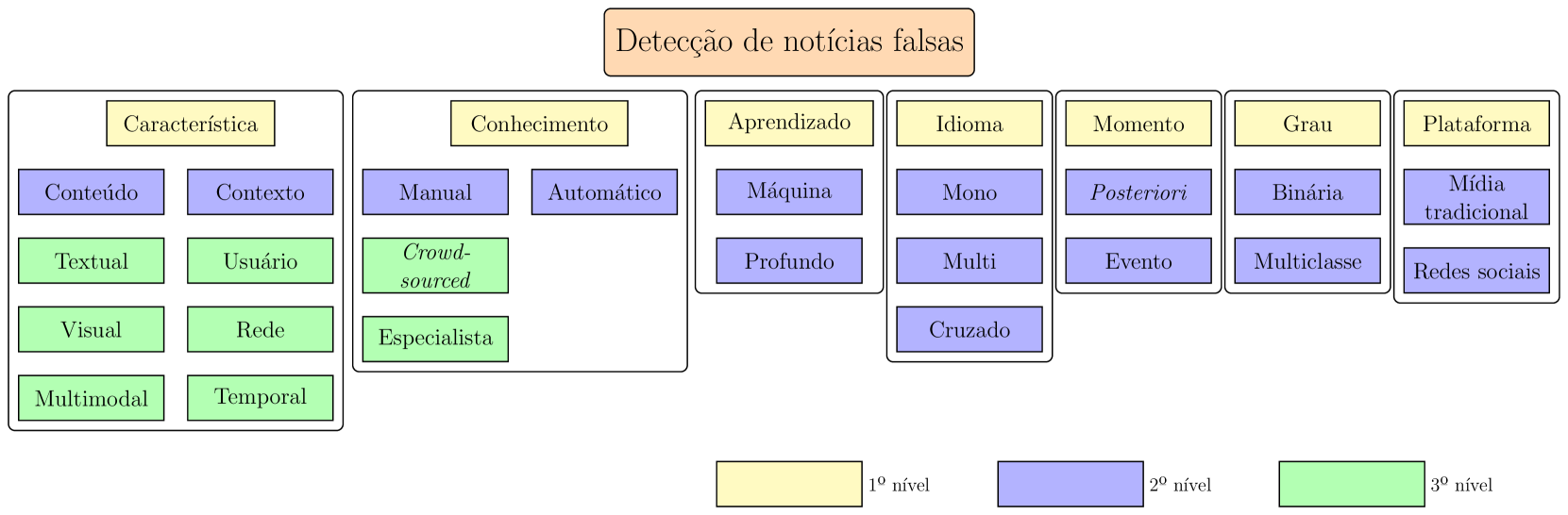
针对虚假信息加速传播超出人工核查能力的问题,本研究致力于开发半自动化事实核查(SAFC)系统。在葡萄牙语环境下,缺乏整合外部证据的公开数据集,这对于开发稳健的AFC系统至关重要,因为许多现有资源仅侧重于基于内在文本特征的分类。本论文通过开发、应用和分析一种方法来丰富葡萄牙语新闻语料库(Fake.Br、COVID19.BR、MuMiN-PT),从而弥补了这一差距。该方法模拟用户的验证过程,采用大型语言模型(LLM,特别是Gemini 1.5 Flash)从文本中提取主要声明,并使用搜索引擎API(Google Search API、Google FactCheck Claims Search API)检索相关的外部文档(证据)。此外,还引入了一个数据验证和预处理框架,包括近重复检测,以提高基础语料库的质量。
🔬 方法详解
问题定义:论文旨在解决葡萄牙语环境下半自动化事实核查系统缺乏高质量、包含外部证据的语料库的问题。现有方法主要依赖于文本的内在特征进行分类,忽略了外部证据的重要性,导致核查结果的可靠性不足。人工核查速度慢,难以应对虚假信息快速传播的挑战。
核心思路:论文的核心思路是模拟人工事实核查的过程,即从新闻文本中提取关键声明,然后利用搜索引擎检索相关证据,并将这些证据与原始文本结合,从而丰富语料库。通过自动化这一过程,可以高效地生成包含外部证据的语料库,为半自动化事实核查系统的开发提供支持。
技术框架:整体框架包括以下几个主要模块:1) 声明抽取:使用大型语言模型(Gemini 1.5 Flash)从葡萄牙语新闻文本中提取主要声明。2) 证据检索:利用Google Search API和Google FactCheck Claims Search API,根据提取的声明检索相关的外部文档作为证据。3) 数据验证与预处理:对检索到的证据进行验证和预处理,包括近重复检测,以提高语料库的质量。4) 语料库增强:将提取的声明和检索到的证据添加到现有的葡萄牙语新闻语料库(Fake.Br、COVID19.BR、MuMiN-PT)中。
关键创新:该方法的主要创新点在于将大型语言模型和搜索引擎API结合,自动化地为葡萄牙语新闻语料库添加外部证据。与传统方法相比,该方法能够更高效、更准确地获取相关证据,从而提高语料库的质量和可用性。此外,数据验证和预处理框架也有助于提高语料库的可靠性。
关键设计:论文使用了Gemini 1.5 Flash作为声明抽取的LLM,具体prompt工程细节未知。搜索引擎API的使用依赖于其自身的检索算法,论文可能对检索结果进行了排序或过滤。近重复检测的具体算法未知,但其目的是去除冗余信息。对于检索到的证据,可能需要进行文本清洗和格式化,以便与原始文本进行整合。具体损失函数和网络结构未提及,因为重点在于语料库增强而非模型训练。
🖼️ 关键图片

📊 实验亮点
论文成功地将外部证据整合到现有的葡萄牙语新闻语料库中,为半自动化事实核查系统的开发奠定了基础。通过使用大型语言模型和搜索引擎API,实现了高效的证据检索和语料库增强。数据验证和预处理框架进一步提高了语料库的质量。具体的性能数据和提升幅度未知。
🎯 应用场景
该研究成果可应用于半自动化事实核查系统的开发,帮助快速识别和揭露虚假信息,尤其是在葡萄牙语环境下。增强后的语料库可用于训练和评估事实核查模型,提高模型的准确性和鲁棒性。此外,该方法也可推广到其他语言和领域,为构建更可靠的信息生态系统做出贡献。
📄 摘要(原文)
The accelerated dissemination of disinformation often outpaces the capacity for manual fact-checking, highlighting the urgent need for Semi-Automated Fact-Checking (SAFC) systems. Within the Portuguese language context, there is a noted scarcity of publicly available datasets that integrate external evidence, an essential component for developing robust AFC systems, as many existing resources focus solely on classification based on intrinsic text features. This dissertation addresses this gap by developing, applying, and analyzing a methodology to enrich Portuguese news corpora (Fake.Br, COVID19.BR, MuMiN-PT) with external evidence. The approach simulates a user's verification process, employing Large Language Models (LLMs, specifically Gemini 1.5 Flash) to extract the main claim from texts and search engine APIs (Google Search API, Google FactCheck Claims Search API) to retrieve relevant external documents (evidence). Additionally, a data validation and preprocessing framework, including near-duplicate detection, is introduced to enhance the quality of the base corpora.