On the robustness of modeling grounded word learning through a child's egocentric input
作者: Wai Keen Vong, Brenden M. Lake
分类: cs.CL
发布日期: 2025-07-19 (更新: 2026-01-08)
💡 一句话要点
基于儿童自我中心视觉输入的具身化词汇学习建模的鲁棒性研究
🎯 匹配领域: 支柱六:视频提取与匹配 (Video Extraction) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 具身化词汇学习 多模态学习 儿童语言习得 自我中心视觉 神经网络
📋 核心要点
- 现有大型模型依赖海量数据,与儿童通过少量数据学习语言的方式不符,需要更贴近儿童学习方式的模型。
- 论文利用儿童的自我中心视觉和听觉数据,训练多模态神经网络,模拟儿童的词汇学习过程。
- 实验证明,模型在不同儿童、视频和图像领域具有良好的泛化能力,验证了具身化词汇学习的鲁棒性。
📝 摘要(中文)
大型语言模型和多模态模型在语言理解方面取得了显著进展,但它们对海量训练数据的依赖与儿童通过有限输入学习语言的方式存在根本差异。为了弥合这一差距,研究人员开始使用与儿童输入数据量和质量相似的数据训练神经网络。本文基于SAYCam数据集,利用自动语音转录方法,为三个儿童生成了超过500小时的多模态视觉-语言数据集,用于训练和评估。研究结果表明,在每个儿童的自动转录数据上训练的网络可以学习词-指代映射,并在视频、儿童和图像领域之间泛化。这些结果验证了多模态神经网络在具身化词汇学习方面的鲁棒性,同时也突出了在每个儿童的经验上训练模型时出现的个体差异。
🔬 方法详解
问题定义:论文旨在研究基于儿童自我中心视觉输入的具身化词汇学习模型的鲁棒性。现有方法通常依赖于大规模数据集,这与儿童通过少量数据学习语言的实际情况不符。此外,以往的研究较少关注模型在不同儿童数据上的泛化能力,难以评估模型的鲁棒性。
核心思路:论文的核心思路是利用从儿童视角获取的视觉和听觉数据,训练多模态神经网络,模拟儿童的词汇学习过程。通过在不同儿童的数据上训练和评估模型,可以评估模型在不同个体经验上的泛化能力,从而验证模型的鲁棒性。这种方法更贴近儿童的实际学习方式,有助于理解人类语言习得的机制。
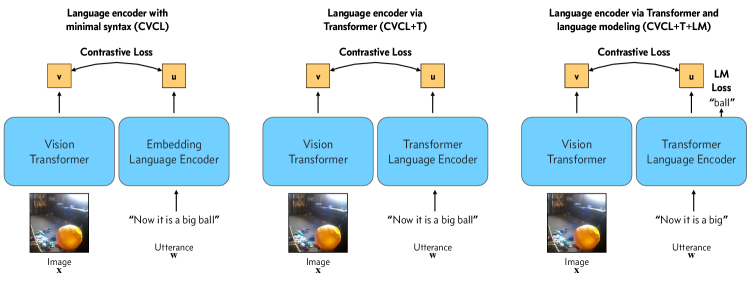
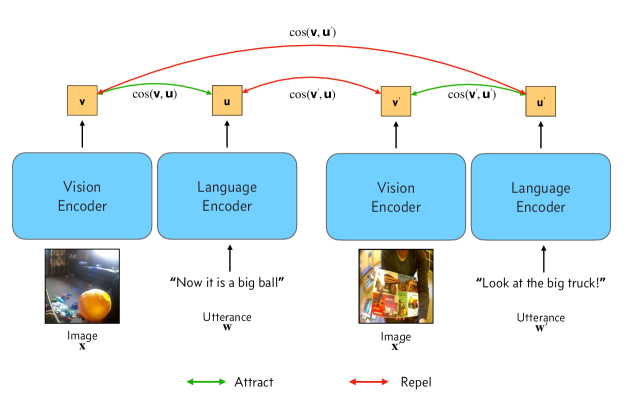
技术框架:整体框架包括数据收集、数据预处理、模型训练和模型评估四个主要阶段。首先,利用SAYCam数据集,该数据集包含多个儿童的自我中心视角视频。然后,使用自动语音转录方法将视频中的语音转换为文本。接下来,使用多模态神经网络,将视觉和文本信息融合,学习词-指代映射。最后,在不同儿童的数据上评估模型的泛化能力。
关键创新:论文的关键创新在于利用大规模的儿童自我中心视角视频数据,并结合自动语音转录技术,构建了用于具身化词汇学习的训练数据集。此外,论文还通过在不同儿童的数据上进行训练和评估,验证了多模态神经网络在具身化词汇学习方面的鲁棒性。
关键设计:论文使用了多模态神经网络,具体结构未知(原文未明确说明)。关键设计可能包括视觉和文本特征的提取方法、多模态特征融合策略以及损失函数的设计。损失函数可能用于衡量模型预测的词-指代映射与真实情况之间的差异。具体的参数设置未知。
🖼️ 关键图片

📊 实验亮点
实验结果表明,在每个儿童的自动转录数据上训练的网络可以学习词-指代映射,并在视频、儿童和图像领域之间泛化。这验证了多模态神经网络在具身化词汇学习方面的鲁棒性,并突出了在每个儿童的经验上训练模型时出现的个体差异。具体的性能数据未知。
🎯 应用场景
该研究成果可应用于开发更智能的儿童语言学习辅助工具,例如,通过分析儿童的视觉和听觉输入,帮助他们更好地理解词汇的含义。此外,该研究还可以为机器人和人工智能系统的开发提供借鉴,使其能够像儿童一样通过具身化经验学习语言。
📄 摘要(原文)
What insights can machine learning bring to understanding human language acquisition? Large language and multimodal models have achieved remarkable capabilities, but their reliance on massive training datasets creates a fundamental mismatch with children, who succeed in acquiring language from comparatively limited input. To help bridge this gap, researchers have increasingly trained neural networks using data similar in quantity and quality to children's input. Taking this approach to the limit, Vong et al. (2024) showed that a multimodal neural network trained on 61 hours of visual and linguistic input extracted from just one child's developmental experience could acquire word-referent mappings. However, whether this approach's success reflects the idiosyncrasies of a single child's experience, or whether it would show consistent and robust learning patterns across multiple children's experiences was not explored. In this article, we applied automated speech transcription methods to the entirety of the SAYCam dataset, consisting of over 500 hours of video data spread across all three children. Using these automated transcriptions, we generated multi-modal vision-and-language datasets for both training and evaluation, and explored a range of neural network configurations to examine the robustness of simulated word learning. Our findings demonstrate that networks trained on automatically transcribed data from each child can acquire word-referent mappings, generalizing across videos, children, and image domains. These results validate the robustness of multimodal neural networks for grounded word learning, while highlighting the individual differences that emerge in how models learn when trained on each child's developmental experiences.