Large Language Models as Medical Codes Selectors: a benchmark using the International Classification of Primary Care
作者: Vinicius Anjos de Almeida, Vinicius de Camargo, Raquel Gómez-Bravo, Egbert van der Haring, Kees van Boven, Marcelo Finger, Luis Fernandez Lopez
分类: cs.CL
发布日期: 2025-07-19 (更新: 2025-11-01)
备注: Accepted at NeurIPS 2025 as a poster presentation in The Second Workshop on GenAI for Health: Potential, Trust, and Policy Compliance (https://openreview.net/forum?id=Kl7KZwJFEG). 33 pages, 10 figures (including appendix), 15 tables (including appendix). To be submitted to peer-reviewed journal. For associated code repository, see https://github.com/almeidava93/llm-as-code-selectors-paper
💡 一句话要点
利用大型语言模型作为医学编码选择器:基于ICPC的基准测试
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 医学编码 ICPC-2 语义搜索 自然语言处理
📋 核心要点
- 医学编码对医疗数据进行结构化,以用于研究、质量监控和政策制定,但现有方法效率较低,需要自动化。
- 该研究利用大型语言模型(LLMs)结合语义搜索,从候选集中选择最佳匹配的ICPC-2医学编码。
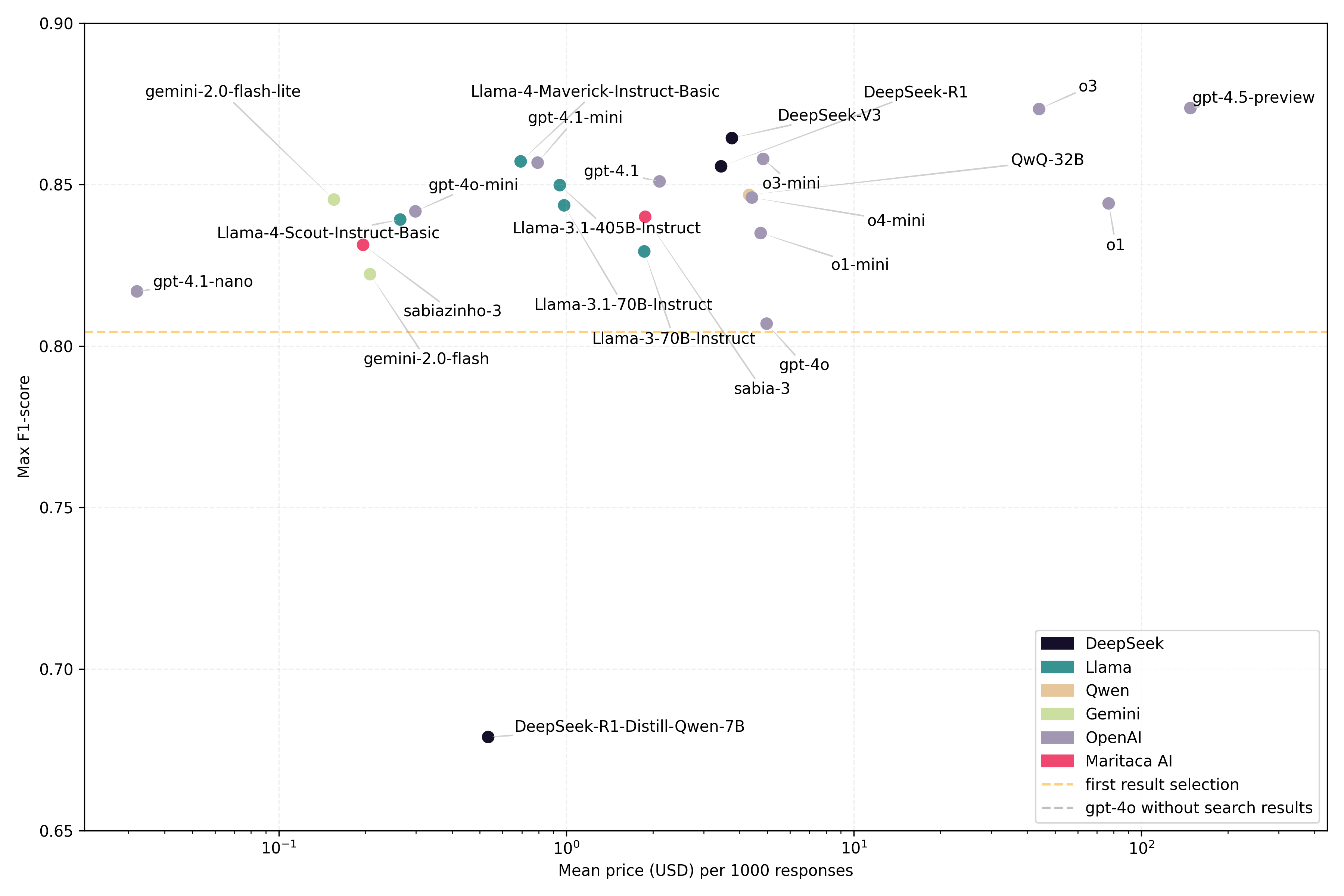
- 实验结果表明,多个LLM在ICPC-2编码任务上表现出色,F1分数超过0.8,证明了LLM在该领域的潜力。
📝 摘要(中文)
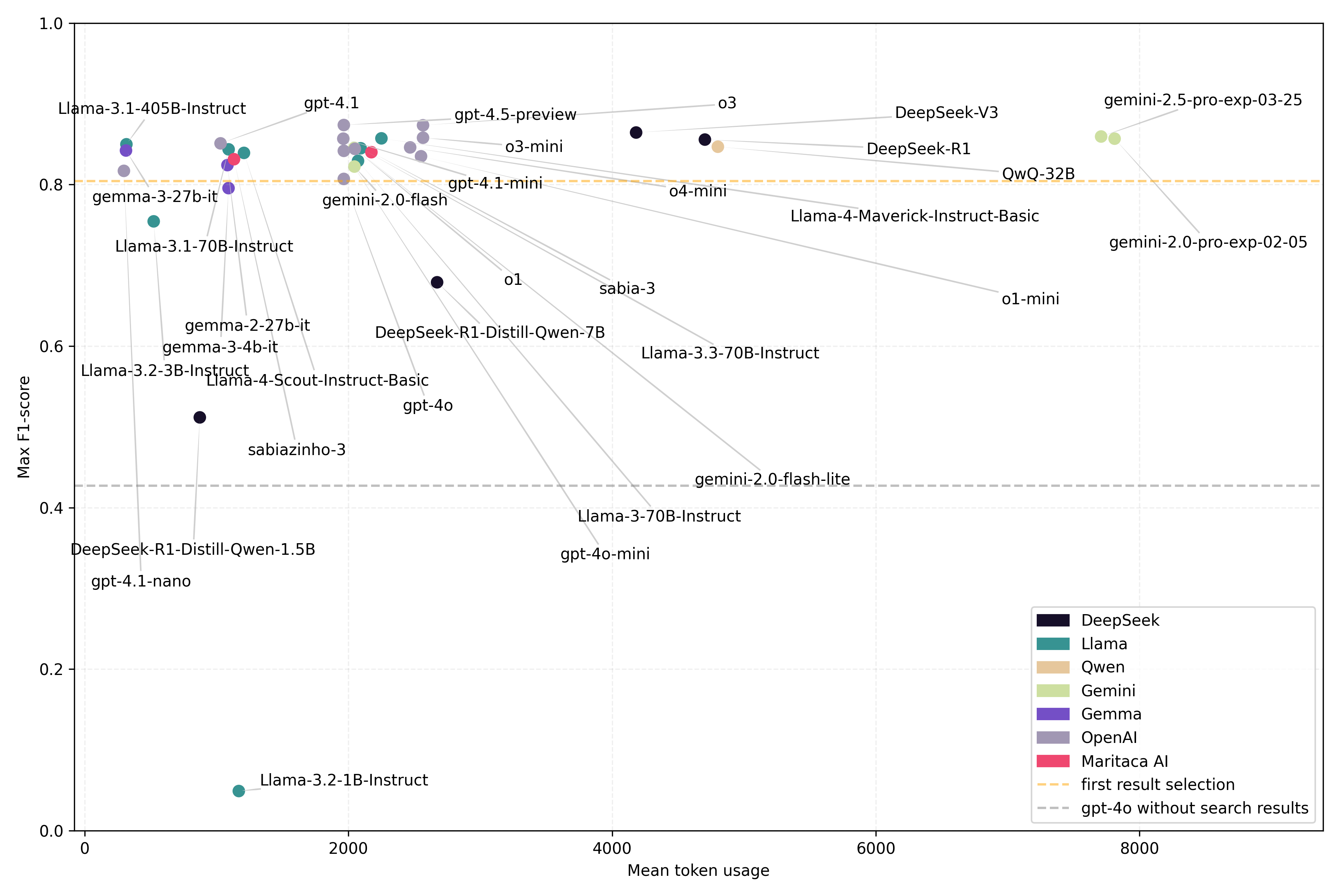
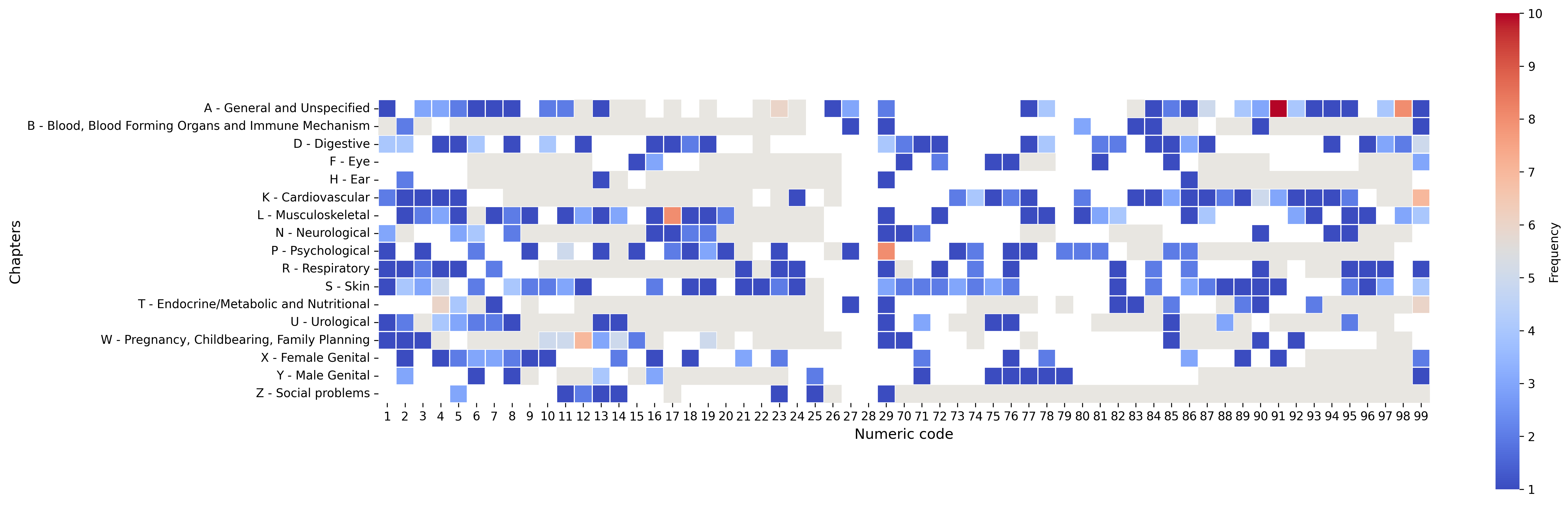
本研究评估了大型语言模型(LLMs)在分配ICPC-2编码方面的潜力,利用领域特定的搜索引擎的输出。使用包含437个巴西葡萄牙语临床表达式的数据集,每个表达式都用ICPC-2代码进行注释。语义搜索引擎(OpenAI的text-embedding-3-large)从73563个标记概念中检索候选结果。使用每个查询和检索到的结果提示三十三个LLM,以选择最佳匹配的ICPC-2代码。使用F1分数评估性能,以及token使用量、成本、响应时间和格式一致性。结果表明,28个模型的F1分数> 0.8;10个模型超过0.85。表现最佳的模型包括gpt-4.5-preview、o3和gemini-2.5-pro。检索器优化可以将性能提高多达4个点。大多数模型以预期的格式返回有效的代码,减少了幻觉。较小的模型(<3B)在格式化和输入长度方面存在困难。结论是,即使没有微调,LLM也显示出自动执行ICPC-2编码的强大潜力。这项工作提供了一个基准并突出了挑战,但研究结果受到数据集范围和设置的限制。需要更广泛、多语言、端到端的评估来进行临床验证。
🔬 方法详解
问题定义:论文旨在解决医学编码自动化的问题,特别是ICPC-2编码。现有方法依赖于人工或传统的规则引擎,效率低且易出错。大型语言模型在理解和生成文本方面展现出强大的能力,但其在医学编码领域的应用潜力尚未充分探索。
核心思路:论文的核心思路是利用大型语言模型(LLMs)作为医学编码选择器。首先,使用语义搜索引擎从大量的医学概念中检索候选编码。然后,利用LLM对检索到的候选编码进行排序和选择,从而实现自动化的ICPC-2编码。这种方法结合了语义搜索的效率和LLM的理解能力。
技术框架:整体框架包括以下几个主要步骤:1) 构建包含临床表达式和ICPC-2编码的数据集;2) 使用OpenAI的text-embedding-3-large模型作为语义搜索引擎,检索与临床表达式相关的候选ICPC-2编码;3) 使用不同的LLM(如gpt-4.5-preview, o3, gemini-2.5-pro)对检索到的候选编码进行排序和选择;4) 使用F1分数、token使用量、成本、响应时间和格式一致性等指标评估LLM的性能。
关键创新:该研究的关键创新在于将大型语言模型应用于医学编码选择任务,并构建了一个基准测试。与传统的规则引擎或机器学习方法相比,LLM能够更好地理解临床表达式的语义,并选择更准确的ICPC-2编码。此外,该研究还评估了不同LLM在医学编码任务上的性能,并分析了检索器优化对性能的影响。
关键设计:研究中使用了OpenAI的text-embedding-3-large模型进行语义搜索,该模型能够将临床表达式和ICPC-2编码映射到同一个语义空间。在LLM的选择方面,研究选择了多个不同规模和架构的LLM,以评估它们在医学编码任务上的性能。在评估指标方面,研究使用了F1分数来衡量编码的准确性,并使用token使用量、成本和响应时间来衡量LLM的效率。
🖼️ 关键图片
📊 实验亮点
实验结果表明,多个大型语言模型在ICPC-2编码任务上表现出色,其中gpt-4.5-preview、o3和gemini-2.5-pro等模型的F1分数超过0.85。检索器优化可以将性能提高多达4个点。此外,大多数模型能够以预期的格式返回有效的代码,减少了幻觉现象。这些结果表明,LLM在医学编码领域具有巨大的潜力。
🎯 应用场景
该研究成果可应用于医疗数据管理、临床决策支持和医疗质量监控等领域。通过自动化ICPC-2编码,可以提高医疗数据的标准化程度,降低人工编码的成本和错误率,并为医疗研究和政策制定提供更可靠的数据基础。未来,该技术有望扩展到其他医学编码体系和语言,实现更广泛的应用。
📄 摘要(原文)
Background: Medical coding structures healthcare data for research, quality monitoring, and policy. This study assesses the potential of large language models (LLMs) to assign ICPC-2 codes using the output of a domain-specific search engine. Methods: A dataset of 437 Brazilian Portuguese clinical expressions, each annotated with ICPC-2 codes, was used. A semantic search engine (OpenAI's text-embedding-3-large) retrieved candidates from 73,563 labeled concepts. Thirty-three LLMs were prompted with each query and retrieved results to select the best-matching ICPC-2 code. Performance was evaluated using F1-score, along with token usage, cost, response time, and format adherence. Results: Twenty-eight models achieved F1-score > 0.8; ten exceeded 0.85. Top performers included gpt-4.5-preview, o3, and gemini-2.5-pro. Retriever optimization can improve performance by up to 4 points. Most models returned valid codes in the expected format, with reduced hallucinations. Smaller models (<3B) struggled with formatting and input length. Conclusions: LLMs show strong potential for automating ICPC-2 coding, even without fine-tuning. This work offers a benchmark and highlights challenges, but findings are limited by dataset scope and setup. Broader, multilingual, end-to-end evaluations are needed for clinical validation.