Intent-Aware Schema Generation And Refinement For Literature Review Tables
作者: Vishakh Padmakumar, Joseph Chee Chang, Kyle Lo, Doug Downey, Aakanksha Naik
分类: cs.CL, cs.LG
发布日期: 2025-07-18 (更新: 2025-10-06)
备注: To Appear at EMNLP Findings 2025
💡 一句话要点
提出意图感知的文献综述表格模式生成与优化方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 模式生成 文献综述 大型语言模型 数据集构建 信息检索 模型优化 合成意图
📋 核心要点
- 现有的模式生成方法在参考评估中存在模糊性,且缺乏有效的编辑和优化手段。
- 本文提出通过合成意图来增强未标注表格语料库,并创建了一个针对信息需求的模式生成数据集。
- 实验结果显示,结合表格意图后,基线性能显著提升,且小型开源模型经过微调后可与最先进的模型竞争。
📝 摘要(中文)
随着学术文献数量的增加,研究人员需要有效地组织、比较和对比文献。大型语言模型(LLMs)能够通过生成模式来支持这一过程,但在模式生成方面的进展缓慢,主要由于参考评估的模糊性和缺乏编辑/优化方法。本文首次解决了这两个问题,提出了一种通过合成意图增强未标注表格语料库的方法,并创建了一个用于研究基于信息需求的模式生成的数据集,从而减少了模糊性。实验表明,结合表格意图显著提升了参考模式重构的基线性能。
🔬 方法详解
问题定义:本文旨在解决学术文献模式生成中的模糊性和缺乏编辑优化方法的问题。现有方法在参考评估中存在不确定性,导致生成的模式质量不高。
核心思路:通过合成意图增强未标注表格语料库,创建一个针对特定信息需求的模式生成数据集,从而减少模糊性并提升生成效果。
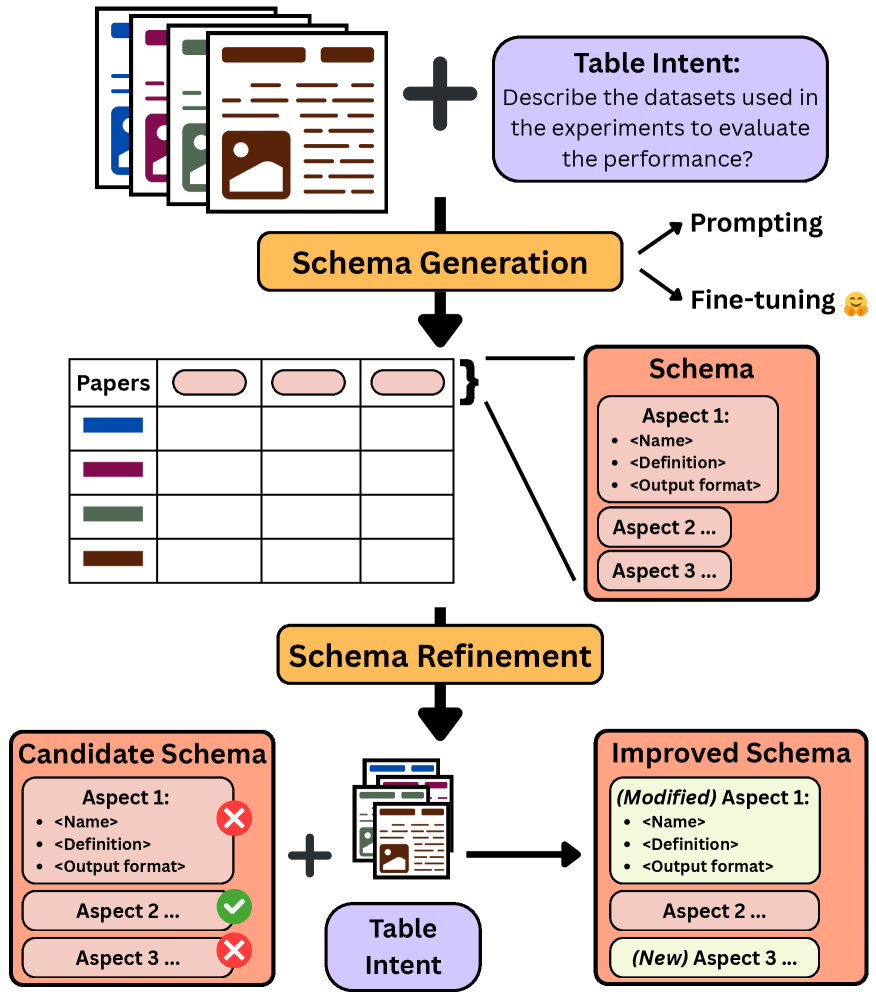
技术框架:整体架构包括数据集构建、模式生成和模式优化三个主要模块。首先,通过合成意图生成数据集,然后使用多种单次模式生成方法进行基准测试,最后提出多种基于LLM的模式优化技术。
关键创新:最重要的创新在于首次提出合成意图的概念,并将其应用于未标注表格语料库的增强,从而显著提升模式生成的准确性和有效性。
关键设计:在实验中,采用了多种单次模式生成方法,包括提示式LLM工作流和微调模型,发现小型开源模型经过微调后能够与最先进的提示式LLM竞争。
🖼️ 关键图片


📊 实验亮点
实验结果表明,结合合成意图后,模式重构的基线性能显著提升,尤其是在小型开源模型的微调后,其性能与最先进的提示式LLM相当,展示了该方法的有效性和实用性。
🎯 应用场景
该研究的潜在应用领域包括学术文献管理、信息检索和自动化文献综述生成等。通过提高模式生成的准确性和效率,研究人员能够更快速地整理和分析大量文献,从而加速科学研究的进展。
📄 摘要(原文)
The increasing volume of academic literature makes it essential for researchers to organize, compare, and contrast collections of documents. Large language models (LLMs) can support this process by generating schemas defining shared aspects along which to compare papers. However, progress on schema generation has been slow due to: (i) ambiguity in reference-based evaluations, and (ii) lack of editing/refinement methods. Our work is the first to address both issues. First, we present an approach for augmenting unannotated table corpora with \emph{synthesized intents}, and apply it to create a dataset for studying schema generation conditioned on a given information need, thus reducing ambiguity. With this dataset, we show how incorporating table intents significantly improves baseline performance in reconstructing reference schemas. We start by comprehensively benchmarking several single-shot schema generation methods, including prompted LLM workflows and fine-tuned models, showing that smaller, open-weight models can be fine-tuned to be competitive with state-of-the-art prompted LLMs. Next, we propose several LLM-based schema refinement techniques and show that these can further improve schemas generated by these methods.