Aligning Large Language Models to Low-Resource Languages through LLM-Based Selective Translation: A Systematic Study
作者: Rakesh Paul, Anusha Kamath, Kanishk Singla, Raviraj Joshi, Utkarsh Vaidya, Sanjay Singh Chauhan, Niranjan Wartikar
分类: cs.CL, cs.LG
发布日期: 2025-07-18 (更新: 2025-10-15)
💡 一句话要点
提出基于LLM选择性翻译的低资源语言对齐方法,提升多语言LLM性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多语言LLM 低资源语言 选择性翻译 语言对齐 机器翻译
📋 核心要点
- 多语言LLM在低资源语言上的性能不足,缺乏高质量的对齐数据是主要挑战。
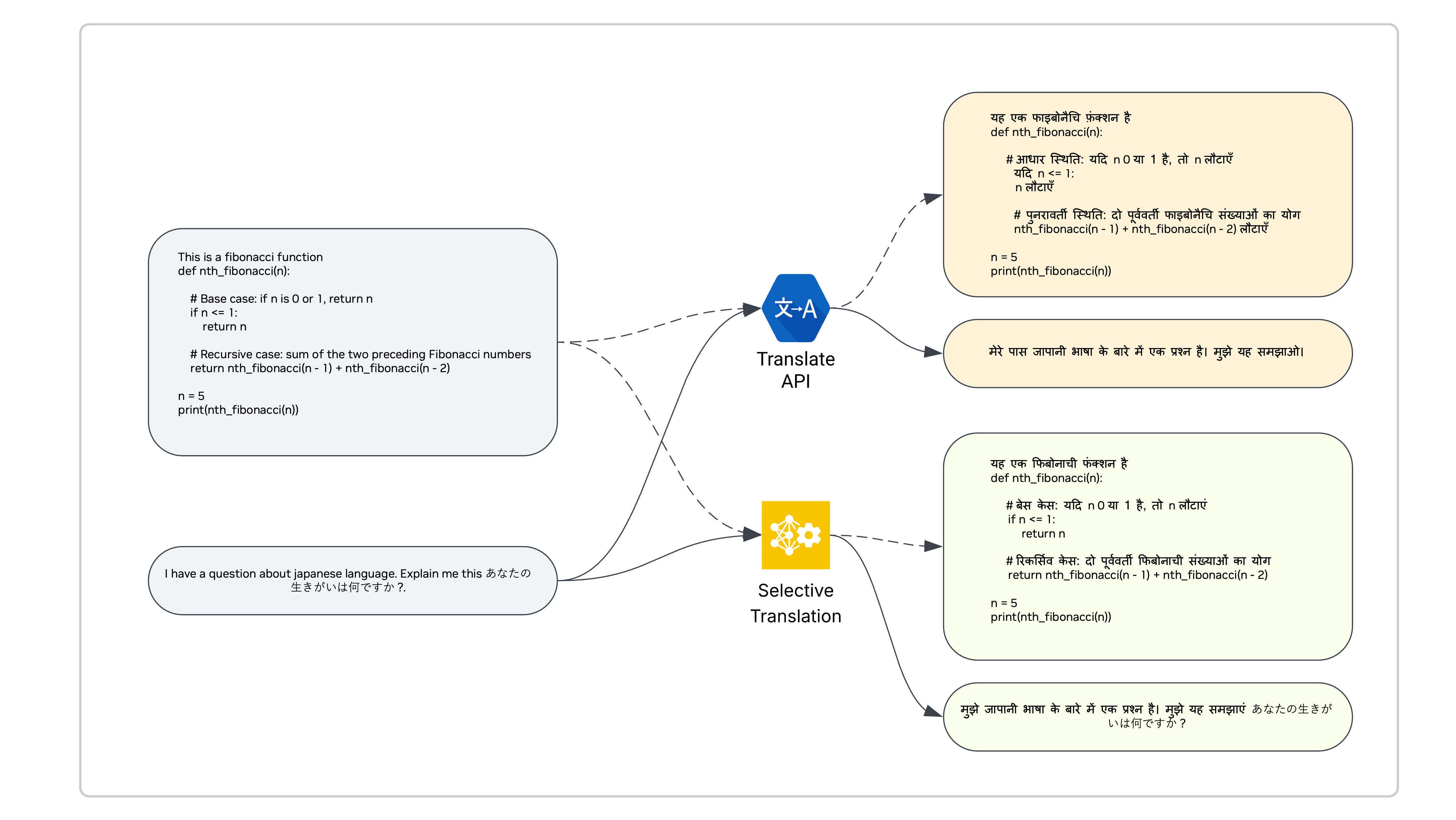
- 论文提出基于LLM的选择性翻译方法,仅翻译可翻译部分,保留代码和结构等关键信息。
- 实验表明,选择性翻译在印地语上优于普通翻译,混合翻译数据和原始英语数据能进一步提升性能。
📝 摘要(中文)
多语言大型语言模型(LLM)通常在英语和非英语语言之间表现出性能差距,尤其是在低资源环境中。将这些模型与低资源语言对齐至关重要,但由于高质量数据有限而具有挑战性。虽然英语对齐数据集很容易获得,但在其他语言中策划等效数据既昂贵又耗时。一种常见的解决方法是翻译现有的英语对齐数据;然而,标准翻译技术通常无法保留代码、数学表达式和JSON等结构化格式等关键元素。在这项工作中,我们研究了基于LLM的选择性翻译,该技术有选择地仅翻译文本中可翻译的部分,同时保留不可翻译的内容和句子结构。我们进行了一项系统的研究,以探索围绕这种方法的关键问题,包括其与普通翻译相比的有效性、过滤噪声输出的重要性以及在对齐期间混合翻译样本与原始英语数据的好处。我们的实验侧重于低资源印度语言印地语,并比较了Google Cloud Translation (GCP)和Llama-3.1-405B生成的翻译。结果突出了选择性翻译作为一种实用且有效的方法,可用于改进LLM中的多语言对齐。
🔬 方法详解
问题定义:论文旨在解决多语言LLM在低资源语言上的对齐问题。现有方法,如直接翻译英文对齐数据,无法有效保留代码、数学表达式和JSON等结构化信息,导致对齐效果不佳。
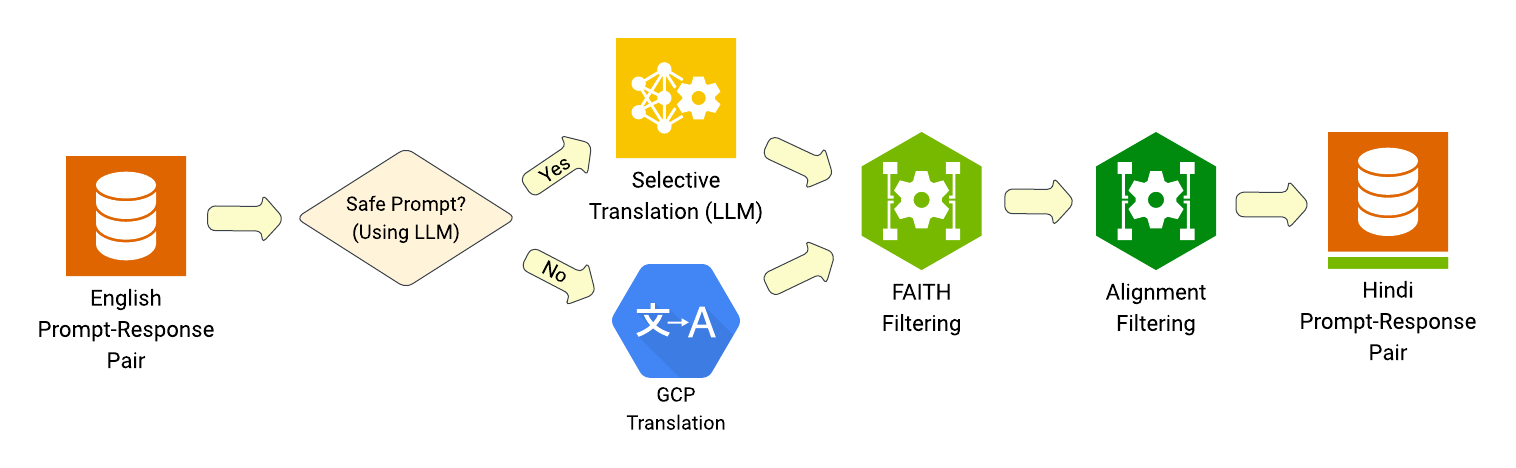
核心思路:核心思路是利用LLM进行选择性翻译,即只翻译文本中需要翻译的部分,而保留那些不应该被翻译的部分(例如代码、数学公式、特定格式的文本)。这样可以最大限度地保留原始数据的结构和关键信息,从而提高对齐效果。
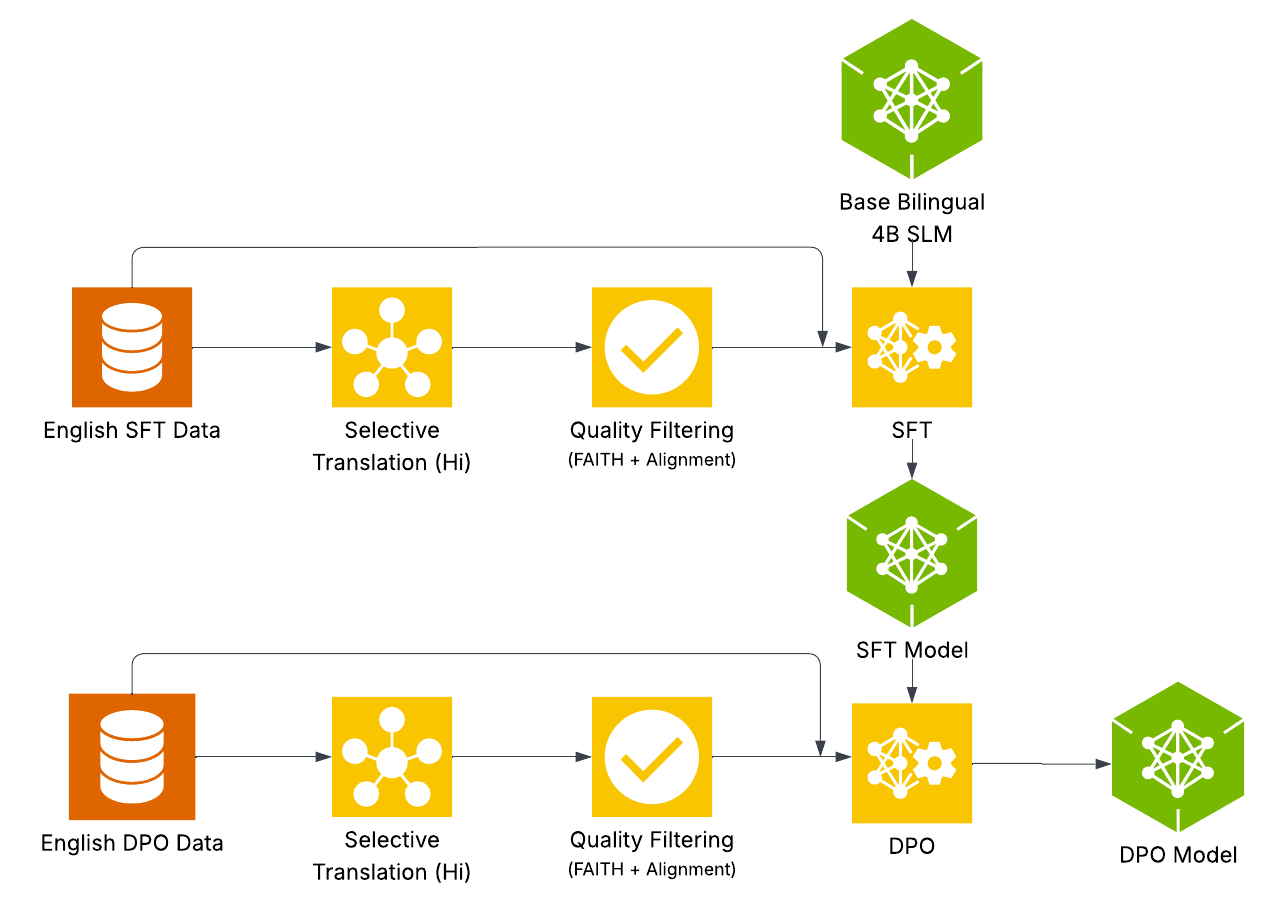
技术框架:整体流程包括:1) 使用LLM对英文对齐数据进行选择性翻译,生成低资源语言的对齐数据;2) 对翻译后的数据进行过滤,去除噪声;3) 将翻译后的数据与原始英文数据混合,构建最终的对齐数据集;4) 使用该数据集对LLM进行微调,使其更好地对齐到低资源语言。
关键创新:关键创新在于选择性翻译策略。与传统的全文翻译相比,选择性翻译能够更好地保留原始数据的结构和语义信息,从而提高对齐效果。此外,论文还系统地研究了选择性翻译的各个方面,包括其有效性、噪声过滤的重要性以及混合数据的益处。
关键设计:论文使用了Google Cloud Translation (GCP)和Llama-3.1-405B两种模型进行翻译实验。选择性翻译的具体实现方式未知,但推测是通过LLM识别文本中需要翻译的部分和不需要翻译的部分,然后分别进行处理。噪声过滤的具体方法未知,但推测是基于LLM的文本质量评估或规则过滤。混合数据的比例未知,需要根据实验结果进行调整。
🖼️ 关键图片
📊 实验亮点
实验结果表明,基于LLM的选择性翻译在低资源语言印地语上的对齐效果优于普通翻译。通过混合翻译后的印地语数据和原始英文数据,可以进一步提升LLM在印地语上的性能。具体性能提升幅度未知,但实验结果表明选择性翻译是一种有前景的低资源语言对齐方法。
🎯 应用场景
该研究成果可应用于提升多语言LLM在低资源语言上的性能,例如机器翻译、文本摘要、问答系统等。通过选择性翻译,可以更有效地利用现有的英文对齐数据,降低低资源语言对齐的成本,促进多语言LLM的广泛应用。未来,该方法可以推广到更多低资源语言,并与其他对齐技术相结合,进一步提升多语言LLM的性能。
📄 摘要(原文)
Multilingual large language models (LLMs) often demonstrate a performance gap between English and non-English languages, particularly in low-resource settings. Aligning these models to low-resource languages is essential yet challenging due to limited high-quality data. While English alignment datasets are readily available, curating equivalent data in other languages is expensive and time-consuming. A common workaround is to translate existing English alignment data; however, standard translation techniques often fail to preserve critical elements such as code, mathematical expressions, and structured formats like JSON. In this work, we investigate LLM-based selective translation, a technique that selectively translates only the translatable parts of a text while preserving non-translatable content and sentence structure. We conduct a systematic study to explore key questions around this approach, including its effectiveness compared to vanilla translation, the importance of filtering noisy outputs, and the benefits of mixing translated samples with original English data during alignment. Our experiments focus on the low-resource Indic language Hindi and compare translations generated by Google Cloud Translation (GCP) and Llama-3.1-405B. The results highlight the promise of selective translation as a practical and effective method for improving multilingual alignment in LLMs.