Comparing Apples to Oranges: A Dataset & Analysis of LLM Humour Understanding from Traditional Puns to Topical Jokes
作者: Tyler Loakman, William Thorne, Chenghua Lin
分类: cs.CL
发布日期: 2025-07-17 (更新: 2025-09-12)
备注: Accepted to Findings of EMNLP 2025
💡 一句话要点
构建多类型幽默理解数据集,揭示LLM在复杂幽默解释上的局限性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 幽默理解 大型语言模型 数据集构建 零样本学习 时事笑话
📋 核心要点
- 现有计算幽默研究主要集中于简单的双关语,忽略了更复杂的、需要现实世界知识的时事笑话。
- 论文通过构建包含多种幽默类型的数据集,并人工编写高质量解释,来评估LLM对不同幽默的理解能力。
- 实验表明,现有LLM在解释复杂幽默方面存在不足,无法可靠地生成所有类型笑话的充分解释。
📝 摘要(中文)
本文旨在研究大型语言模型(LLM)解释幽默的能力是否依赖于幽默的具体形式。作者构建了一个包含600个笑话的数据集,涵盖异形和同形双关语、当代网络幽默以及时事笑话等四种类型,并手动编写了高质量的解释。通过比较一系列LLM在零样本条件下准确、全面地解释不同类型笑话的能力,论文揭示了幽默解释任务中的关键研究空白。实验结果表明,包括推理模型在内,没有模型能够可靠地生成所有类型笑话的充分解释,进一步突出了现有工作过度关注简单笑话形式的局限性。
🔬 方法详解
问题定义:现有计算幽默的研究主要集中在简单的、基于双关语的笑话上,忽略了需要更广泛世界知识和推理能力的复杂幽默形式,例如时事笑话。这导致了对LLM幽默理解能力的评估存在偏差,无法全面反映其真实水平。现有方法无法有效处理需要背景知识和复杂推理的幽默。
核心思路:论文的核心思路是通过构建一个包含多种幽默类型的数据集,并人工编写高质量的解释,来更全面地评估LLM的幽默理解能力。通过比较LLM在不同类型幽默上的表现,揭示其在复杂幽默理解方面的局限性,从而为未来的研究提供方向。
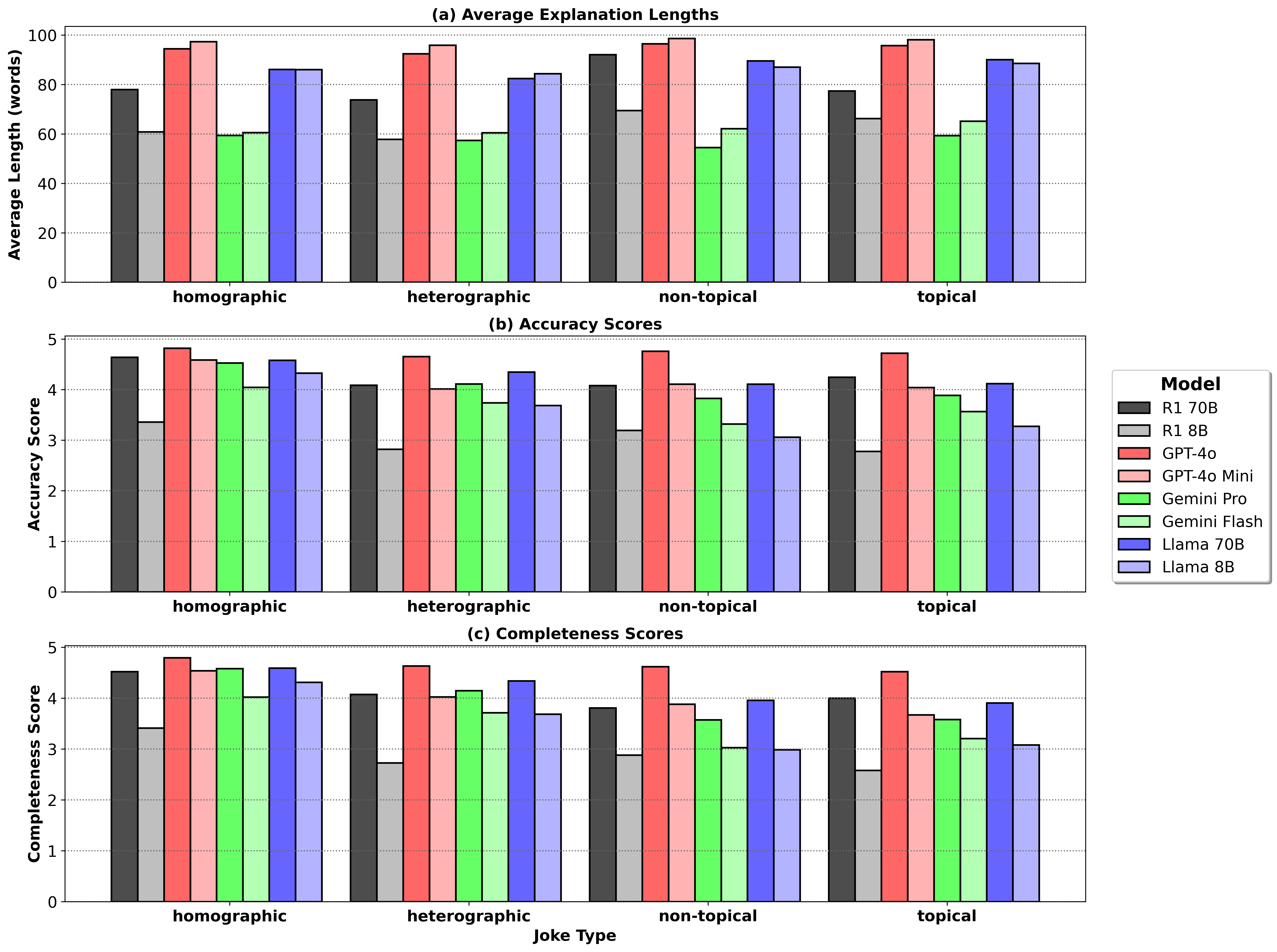
技术框架:论文主要包含以下几个阶段:1) 收集不同类型的笑话,包括异形和同形双关语、当代网络幽默以及时事笑话。2) 人工编写每个笑话的高质量解释,作为评估LLM的ground truth。3) 使用一系列LLM(包括推理模型)在零样本条件下生成笑话解释。4) 对比LLM生成的解释与人工编写的解释,评估其准确性和全面性。5) 分析不同类型笑话的解释结果,识别LLM在幽默理解方面的优势和不足。
关键创新:论文的关键创新在于构建了一个包含多种幽默类型的数据集,并人工编写了高质量的解释。这使得可以更全面地评估LLM的幽默理解能力,并揭示其在复杂幽默理解方面的局限性。此外,论文还对不同类型幽默的解释难度进行了分析,为未来的研究提供了有价值的见解。
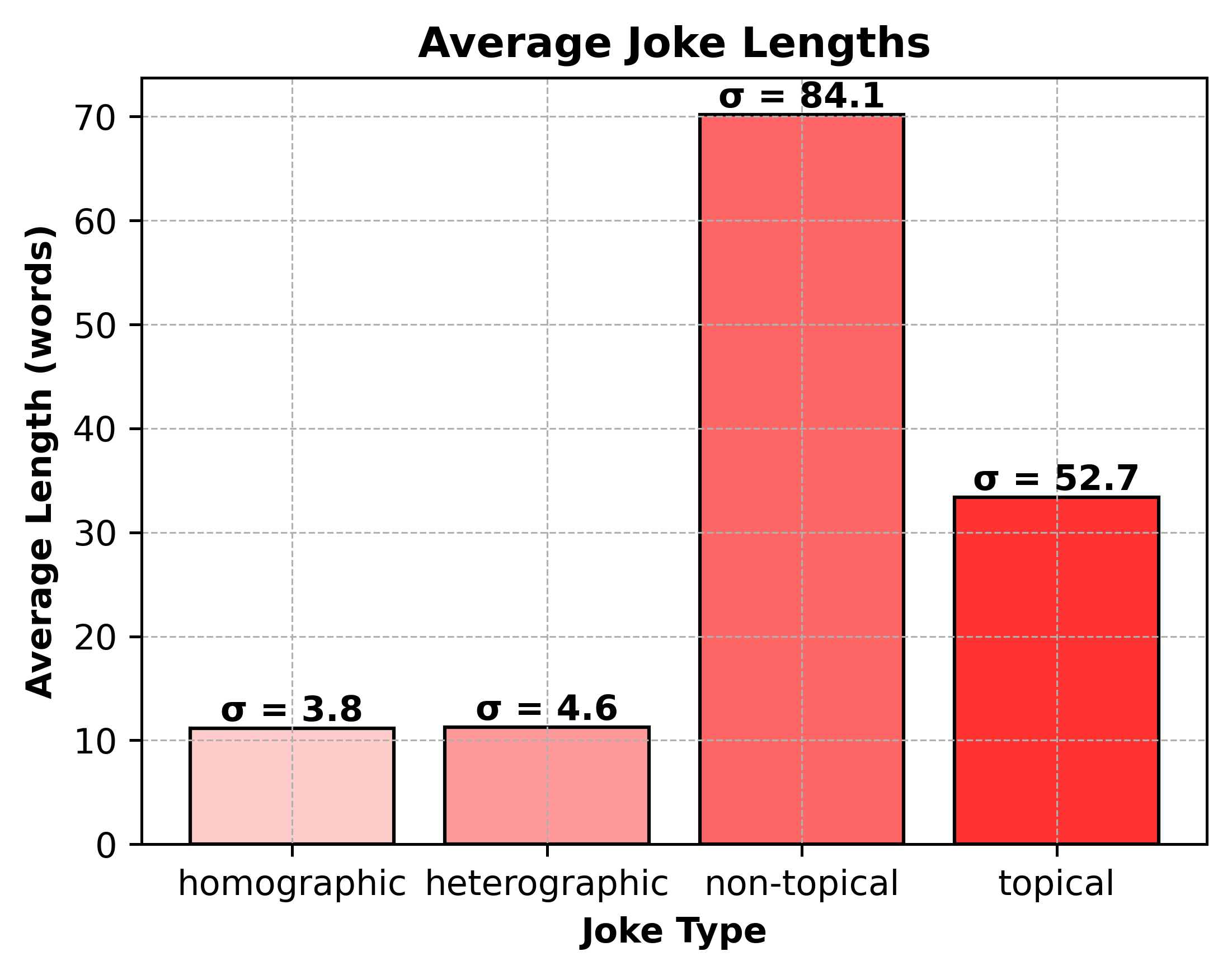
关键设计:数据集包含600个笑话,分为四种类型:异形双关语、同形双关语、当代网络幽默和时事笑话。每个笑话都由人工编写了高质量的解释,解释的质量通过人工评估进行保证。实验采用零样本设置,即LLM没有经过任何针对幽默理解的微调。评估指标主要关注生成解释的准确性和全面性,具体评估方法未知。
🖼️ 关键图片

📊 实验亮点
实验结果表明,现有LLM在解释复杂幽默方面存在显著不足,即使是推理模型也无法可靠地生成所有类型笑话的充分解释。例如,LLM在解释时事笑话时表现较差,表明其缺乏必要的背景知识和推理能力。该研究突出了现有计算幽默研究过度关注简单笑话形式的局限性,并为未来的研究提供了新的方向。
🎯 应用场景
该研究成果可应用于提升聊天机器人、智能助手等AI系统的幽默理解能力,使其能够更好地理解和生成幽默内容,从而提高用户交互体验。此外,该数据集和分析方法也可用于评估和改进LLM的推理能力和知识获取能力,促进通用人工智能的发展。未来,该研究可以扩展到其他语言和文化背景下的幽默理解。
📄 摘要(原文)
Humour, as a complex language form, is derived from myriad aspects of life. Whilst existing work on computational humour has focussed almost exclusively on short pun-based jokes, we investigate whether the ability of Large Language Models (LLMs) to explain humour depends on the particular form. We compare models' joke explanation abilities from simple puns to complex topical humour that requires esoteric knowledge of real-world entities and events. To this end, we curate a dataset of 600 jokes across 4 joke types and manually write high-quality explanations. These jokes include heterographic and homographic puns, contemporary internet humour, and topical jokes. Using this dataset, we compare the zero-shot abilities of a range of LLMs to accurately and comprehensively explain jokes of different types, identifying key research gaps in the task of humour explanation. We find that none of the tested models (including reasoning models) are capable of reliably generating adequate explanations of all joke types, further highlighting the narrow focus of most existing works on overly simple joke forms.