QuestA: Expanding Reasoning Capacity in LLMs via Question Augmentation
作者: Jiazheng Li, Hongzhou Lin, Hong Lu, Kaiyue Wen, Zaiwen Yang, Jiaxuan Gao, Yi Wu, Jingzhao Zhang
分类: cs.CL, cs.AI
发布日期: 2025-07-17 (更新: 2025-09-30)
备注: 19 pages, 8 figures
🔗 代码/项目: GITHUB
💡 一句话要点
QuestA:通过问题增广提升大型语言模型在推理任务中的能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 强化学习 问题增广 数学推理 推理能力提升
📋 核心要点
- 现有研究表明,强化学习在提升LLM推理能力方面存在瓶颈,难以有效解决复杂推理问题。
- QuestA通过在训练中引入部分解,降低问题难度,为模型提供更具信息量的学习信号,从而提升推理能力。
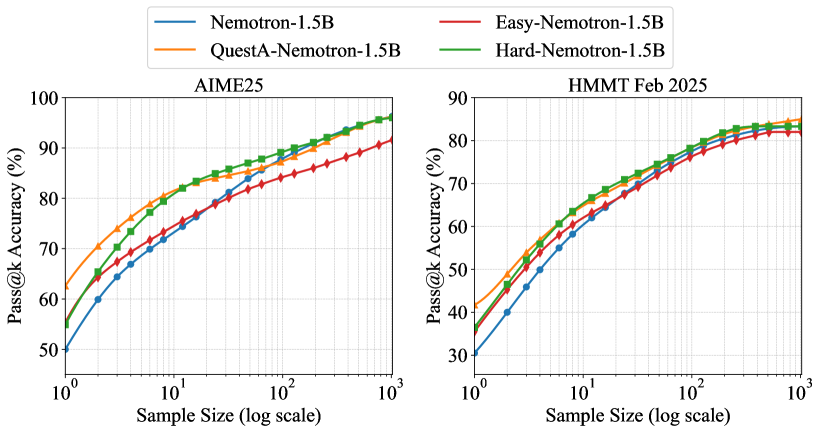
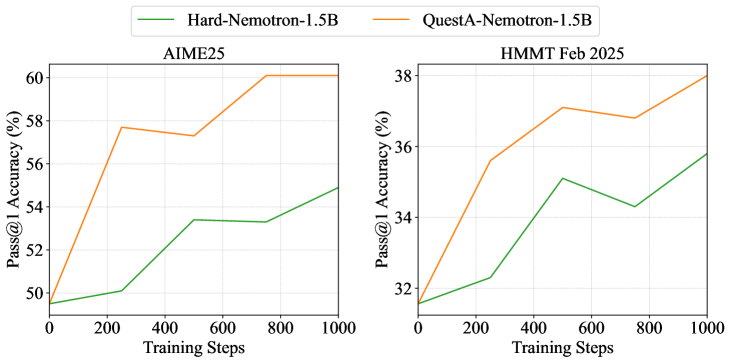
- 实验表明,QuestA显著提升了模型在数学推理基准测试上的性能,超越了现有开源模型,并取得了新的SOTA结果。
📝 摘要(中文)
强化学习(RL)已成为训练大型语言模型(LLM)进行推理任务的核心范式。然而,最近的研究质疑RL在激励超出基础模型的推理能力方面的作用。这提出了一个关键挑战:如何调整RL以更有效地解决更困难的推理问题?为了应对这一挑战,我们提出了一种简单而有效的策略,即通过问题增广:在训练期间引入部分解决方案,以降低问题难度并提供更丰富的信息学习信号。我们的方法QuestA,当应用于数学推理任务的RL训练时,不仅提高了pass@1,而且提高了pass@k,尤其是在标准RL难以取得进展的问题上。这使得能够持续改进强大的开源模型,如DeepScaleR和OpenMath Nemotron,进一步增强它们的推理能力。我们使用15亿参数模型在数学基准测试上取得了新的最先进的结果:在AIME24上为72.50%(+10.73%),在AIME25上为62.29%(+12.79%),在HMMT25上为41.67%(+10.11%)。代码、数据和模型可在https://github.com/foreverlasting1202/QuestA获取。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在复杂推理任务中,利用强化学习训练时,难以有效提升推理能力的问题。现有方法,特别是标准强化学习,在解决高难度推理问题时,学习效率低下,难以取得显著进展。模型的推理能力提升受限,无法充分利用强化学习的潜力。
核心思路:论文的核心思路是通过问题增广(Question Augmentation)来改善强化学习的训练过程。具体来说,在训练过程中,不是直接让模型解决完整的难题,而是逐步引入部分解或中间步骤,将难题分解为更小的、更易于处理的子问题。这样做的目的是降低每个训练步骤的难度,并为模型提供更明确、更丰富的学习信号。
技术框架:QuestA的整体框架是在标准的强化学习训练循环中加入问题增广模块。具体流程如下:1. 从原始问题集中采样问题。2. 对于每个问题,生成一个或多个部分解(augmented questions)。3. 使用原始问题和增广问题训练LLM。4. 使用强化学习算法(如PPO)优化模型,目标是最大化在原始问题和增广问题上的奖励。增广问题的生成方式可以有多种,例如,逐步给出数学题的解题步骤。
关键创新:QuestA的关键创新在于将问题增广的思想引入到LLM的强化学习训练中。与传统的强化学习方法相比,QuestA不是直接让模型面对完整的难题,而是通过逐步引入部分解来引导模型学习。这种方法可以有效地降低训练难度,并为模型提供更具信息量的学习信号,从而提升模型的推理能力。
关键设计:QuestA的关键设计包括:1. 部分解的生成策略:如何生成高质量的部分解,使其既能降低问题难度,又能提供有用的信息。2. 奖励函数的设计:如何设计奖励函数,以鼓励模型学习正确的推理步骤,并避免模型陷入局部最优。3. 增广问题的采样策略:如何选择哪些问题进行增广,以及如何控制增广问题的数量。论文中可能使用了启发式规则或学习算法来优化这些设计。
🖼️ 关键图片
📊 实验亮点
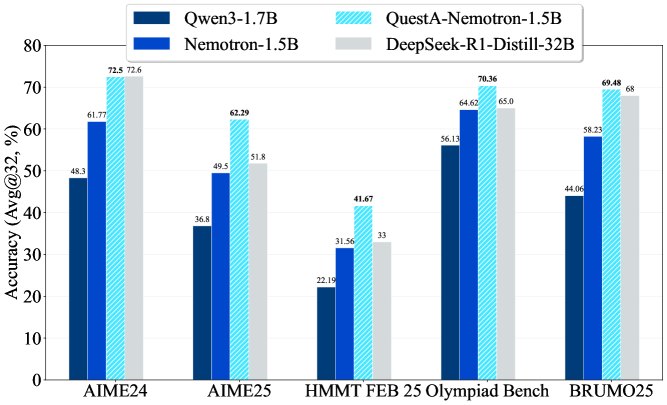
QuestA在数学推理基准测试上取得了显著的性能提升。具体而言,在AIME24上达到了72.50%的准确率,相比之前的最佳结果提升了10.73%;在AIME25上达到了62.29%的准确率,提升了12.79%;在HMMT25上达到了41.67%的准确率,提升了10.11%。这些结果表明,QuestA能够有效提升LLM在复杂推理任务中的性能,并超越了现有的开源模型。
🎯 应用场景
QuestA方法具有广泛的应用前景,可应用于各种需要复杂推理能力的场景,例如数学问题求解、代码生成、知识图谱推理等。该方法能够有效提升LLM在这些领域的性能,使其能够解决更复杂、更具挑战性的问题。未来,QuestA有望成为提升LLM推理能力的重要技术手段,推动人工智能在各个领域的应用。
📄 摘要(原文)
Reinforcement learning (RL) has emerged as a central paradigm for training large language models (LLMs) in reasoning tasks. Yet recent studies question RL's ability to incentivize reasoning capacity beyond the base model. This raises a key challenge: how can RL be adapted to solve harder reasoning problems more effectively? To address this challenge, we propose a simple yet effective strategy via Question Augmentation: introduce partial solutions during training to reduce problem difficulty and provide more informative learning signals. Our method, QuestA, when applied during RL training on math reasoning tasks, not only improves pass@1 but also pass@k-particularly on problems where standard RL struggles to make progress. This enables continual improvement over strong open-source models such as DeepScaleR and OpenMath Nemotron, further enhancing their reasoning capabilities. We achieve new state-of-the-art results on math benchmarks using 1.5B-parameter models: 72.50% (+10.73%) on AIME24, 62.29% (+12.79%) on AIME25, and 41.67% (+10.11%) on HMMT25. Code, data and model are available at https://github.com/foreverlasting1202/QuestA.